MySQL技术文章
-
数据库 · MySQL | 2星期前 | 性能优化 · 执行计划 · 生产实践 · MySQL教程 · 索引优化 · mysql explain 索引优化 Index Condition Pushdown ICP
 从 MySQL 8.4 Index Condition Pushdown 入手,讲清为什么用了索引仍可能回表拖慢,以及如何用 EXPLAIN、optimizer_switch 和线上指标验证 ICP 收益。179 收藏
从 MySQL 8.4 Index Condition Pushdown 入手,讲清为什么用了索引仍可能回表拖慢,以及如何用 EXPLAIN、optimizer_switch 和线上指标验证 ICP 收益。179 收藏 -
 通过订单列表慢查询案例,演示如何阅读 EXPLAIN 的 type、key、rows、Extra 字段,并设计联合索引优化 WHERE、ORDER BY 和 LIMIT 分页。159 收藏
通过订单列表慢查询案例,演示如何阅读 EXPLAIN 的 type、key、rows、Extra 字段,并设计联合索引优化 WHERE、ORDER BY 和 LIMIT 分页。159 收藏 -
数据库 · MySQL | 2星期前 | 性能优化 · InnoDB · 故障排查 · MySQL教程 · DBA实战 · mysql innodb 性能优化 预热 冷启动 MySQL 8.4 Buffer Pool
 从数据库重启后热点接口 P99 抖动切入,讲清 MySQL 8.x InnoDB Buffer Pool dump/load、冷启动诊断、预热脚本、参数检查和上线演练。158 收藏
从数据库重启后热点接口 P99 抖动切入,讲清 MySQL 8.x InnoDB Buffer Pool dump/load、冷启动诊断、预热脚本、参数检查和上线演练。158 收藏 -
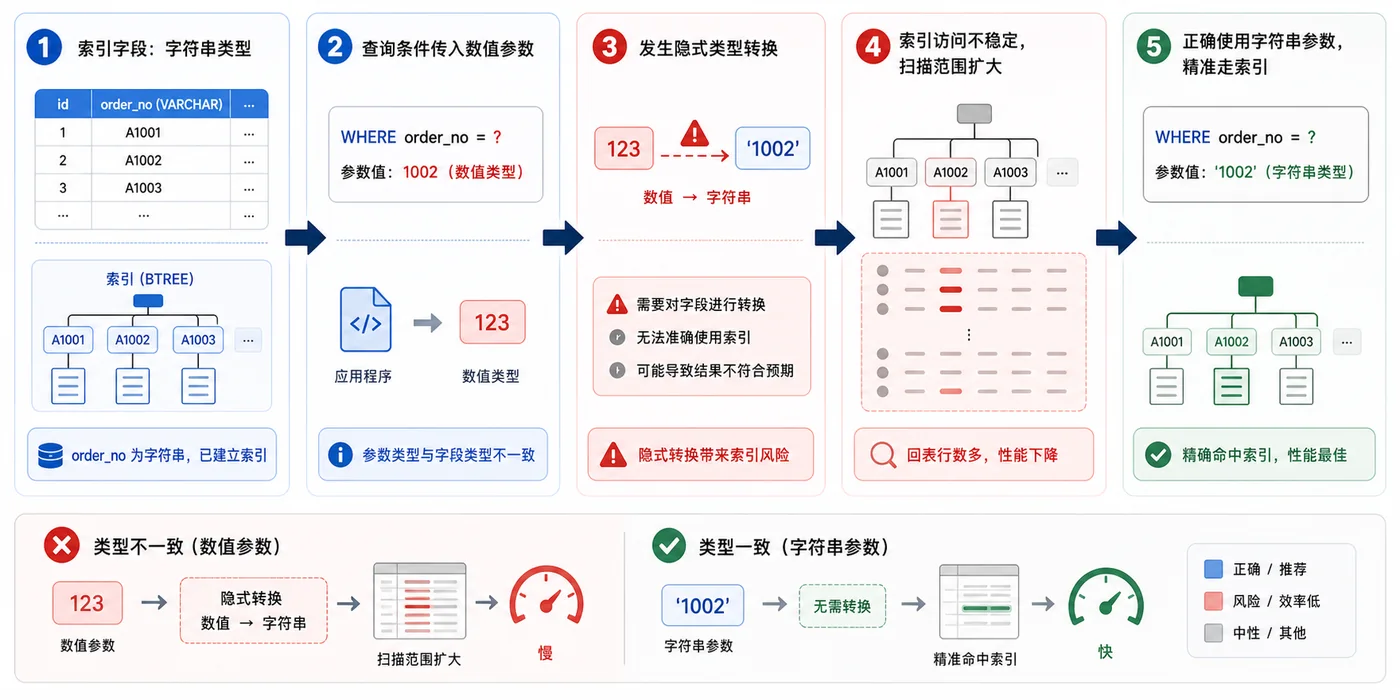 本文用订单号查询变慢的场景,演示 MySQL 隐式转换如何导致索引无法稳定命中,并给出字段类型统一、参数绑定和上线检查方案。152 收藏
本文用订单号查询变慢的场景,演示 MySQL 隐式转换如何导致索引无法稳定命中,并给出字段类型统一、参数绑定和上线检查方案。152 收藏 -
数据库 · MySQL | 2星期前 | MySQL教程 · 慢查询治理 · 索引优化 · 分区表 · DBA实战 · mysql 分区表 慢查询 索引优化 MySQL 8.4 partition pruning
 从订单历史表按月分区的慢查询切入,讲清 MySQL 8.x 分区裁剪的命中条件、失效写法、EXPLAIN PARTITIONS 验证、索引配合和上线检查。133 收藏
从订单历史表按月分区的慢查询切入,讲清 MySQL 8.x 分区裁剪的命中条件、失效写法、EXPLAIN PARTITIONS 验证、索引配合和上线检查。133 收藏 -
 MySQL数据归档主要有四种方式。1.使用SQL语句手动归档,通过INSERT和DELETE迁移历史数据,适合小规模场景但需注意事务控制、索引影响和备份确认;2.利用事件调度器实现定时自动归档,可设定周期任务并建议配合分区使用以减少性能影响;3.结合时间分区表进行归档,提升查询效率且操作整个分区更高效,但存在分区键设计限制;4.借助第三方工具如pt-archiver或mysqldump,前者支持边归档边删除并控制资源占用,后者适用于低频小规模归档。根据数据量和业务需求选择合适方法,小型项目可用SQL+事件127 收藏
MySQL数据归档主要有四种方式。1.使用SQL语句手动归档,通过INSERT和DELETE迁移历史数据,适合小规模场景但需注意事务控制、索引影响和备份确认;2.利用事件调度器实现定时自动归档,可设定周期任务并建议配合分区使用以减少性能影响;3.结合时间分区表进行归档,提升查询效率且操作整个分区更高效,但存在分区键设计限制;4.借助第三方工具如pt-archiver或mysqldump,前者支持边归档边删除并控制资源占用,后者适用于低频小规模归档。根据数据量和业务需求选择合适方法,小型项目可用SQL+事件127 收藏 -
数据库 · MySQL | 2星期前 | binlog · 主从复制 · 故障排查 · MySQL教程 · DBA实战 · mysql DBA binlog 主从复制 MySQL 8.4 复制延迟 relay log
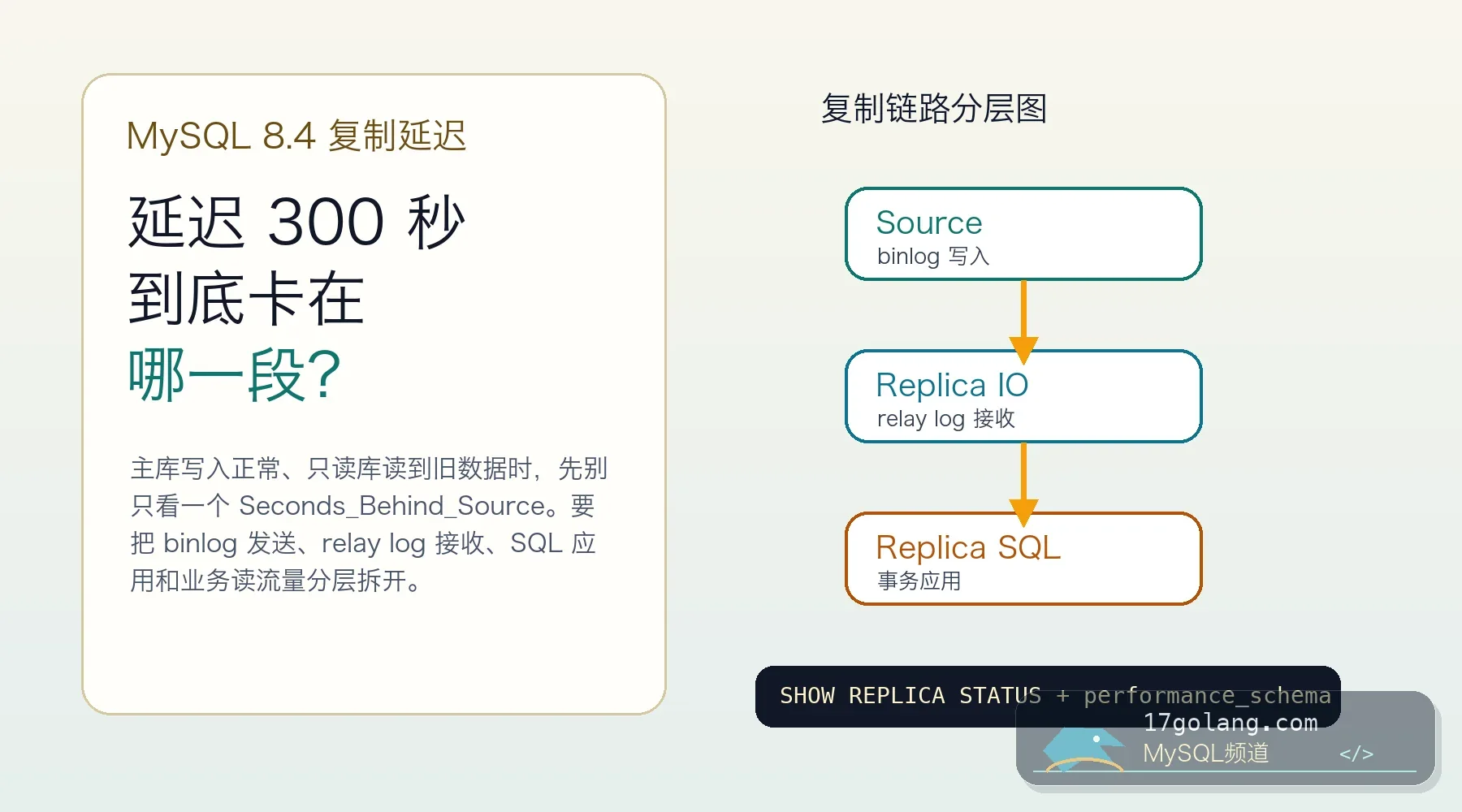 从只读库延迟导致读到旧数据的事故切入,讲清 MySQL 8.x 复制延迟如何区分 IO 接收、relay log 应用、大事务、并行复制和只读流量影响。119 收藏
从只读库延迟导致读到旧数据的事故切入,讲清 MySQL 8.x 复制延迟如何区分 IO 接收、relay log 应用、大事务、并行复制和只读流量影响。119 收藏 -
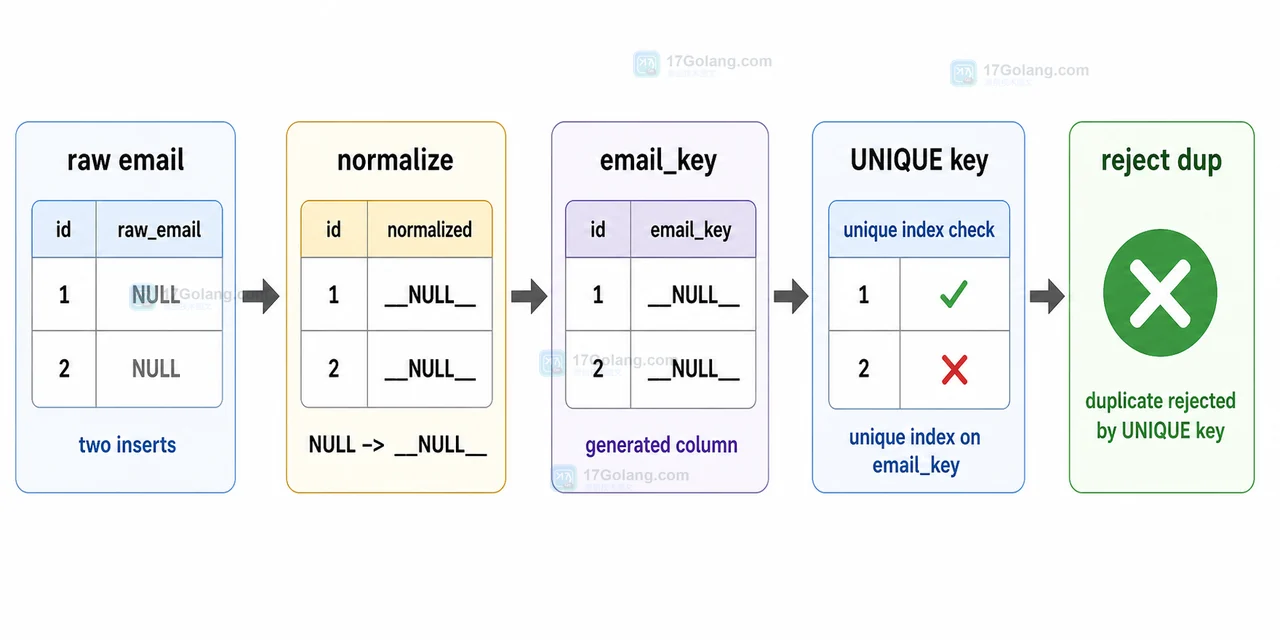 从一个唯一索引没有拦住多条 NULL 数据的现场开始,复现 MySQL 唯一索引与 NULL 的行为,再用 NOT NULL、业务默认值和生成列三种方案修复约束边界。109 收藏
从一个唯一索引没有拦住多条 NULL 数据的现场开始,复现 MySQL 唯一索引与 NULL 的行为,再用 NOT NULL、业务默认值和生成列三种方案修复约束边界。109 收藏 -
 MySQL数据备份的关键方法包括:一、使用mysqldump进行逻辑备份,适合中小型数据库,可通过命令实现全量备份并结合压缩节省空间;二、物理备份通过直接复制数据文件实现,速度快但需停机或使用一致性机制;三、利用binlog实现增量备份,支持时间点恢复,建议定期归档日志以减少数据丢失风险;四、合理策略如每日全量+小时binlog归档、周全量+日增量+binlog、主从复制+定时备份等,同时必须定期验证备份可恢复性。105 收藏
MySQL数据备份的关键方法包括:一、使用mysqldump进行逻辑备份,适合中小型数据库,可通过命令实现全量备份并结合压缩节省空间;二、物理备份通过直接复制数据文件实现,速度快但需停机或使用一致性机制;三、利用binlog实现增量备份,支持时间点恢复,建议定期归档日志以减少数据丢失风险;四、合理策略如每日全量+小时binlog归档、周全量+日增量+binlog、主从复制+定时备份等,同时必须定期验证备份可恢复性。105 收藏 -
数据库 · MySQL | 2星期前 | InnoDB · MySQL教程 · 数据库实战 · 死锁排查 · 锁等待 · mysql innodb 死锁 事务 锁等待 MySQL 8 data_locks
 从转账事务死锁复现出发,讲清 MySQL 8.x InnoDB 行锁、间隙锁、data_locks、data_lock_waits、SHOW ENGINE INNODB STATUS、事务顺序和重试策略。105 收藏
从转账事务死锁复现出发,讲清 MySQL 8.x InnoDB 行锁、间隙锁、data_locks、data_lock_waits、SHOW ENGINE INNODB STATUS、事务顺序和重试策略。105 收藏