-
数据库 · MySQL | 6天前 | 性能优化 · 执行计划 · 生产实践 · MySQL教程 · 索引优化 · mysql explain 索引优化 Index Condition Pushdown ICP
 从 MySQL 8.4 Index Condition Pushdown 入手,讲清为什么用了索引仍可能回表拖慢,以及如何用 EXPLAIN、optimizer_switch 和线上指标验证 ICP 收益。179 收藏
从 MySQL 8.4 Index Condition Pushdown 入手,讲清为什么用了索引仍可能回表拖慢,以及如何用 EXPLAIN、optimizer_switch 和线上指标验证 ICP 收益。179 收藏 -
数据库 · MySQL | 5天前 | 性能优化 · InnoDB · 故障排查 · MySQL教程 · DBA实战 · mysql innodb 性能优化 预热 冷启动 MySQL 8.4 Buffer Pool
 从数据库重启后热点接口 P99 抖动切入,讲清 MySQL 8.x InnoDB Buffer Pool dump/load、冷启动诊断、预热脚本、参数检查和上线演练。158 收藏
从数据库重启后热点接口 P99 抖动切入,讲清 MySQL 8.x InnoDB Buffer Pool dump/load、冷启动诊断、预热脚本、参数检查和上线演练。158 收藏 -
数据库 · MySQL | 5天前 | MySQL教程 · 慢查询治理 · 索引优化 · 分区表 · DBA实战 · mysql 分区表 慢查询 索引优化 MySQL 8.4 partition pruning
 从订单历史表按月分区的慢查询切入,讲清 MySQL 8.x 分区裁剪的命中条件、失效写法、EXPLAIN PARTITIONS 验证、索引配合和上线检查。133 收藏
从订单历史表按月分区的慢查询切入,讲清 MySQL 8.x 分区裁剪的命中条件、失效写法、EXPLAIN PARTITIONS 验证、索引配合和上线检查。133 收藏 -
数据库 · MySQL | 5天前 | binlog · 主从复制 · 故障排查 · MySQL教程 · DBA实战 · mysql DBA binlog 主从复制 MySQL 8.4 复制延迟 relay log
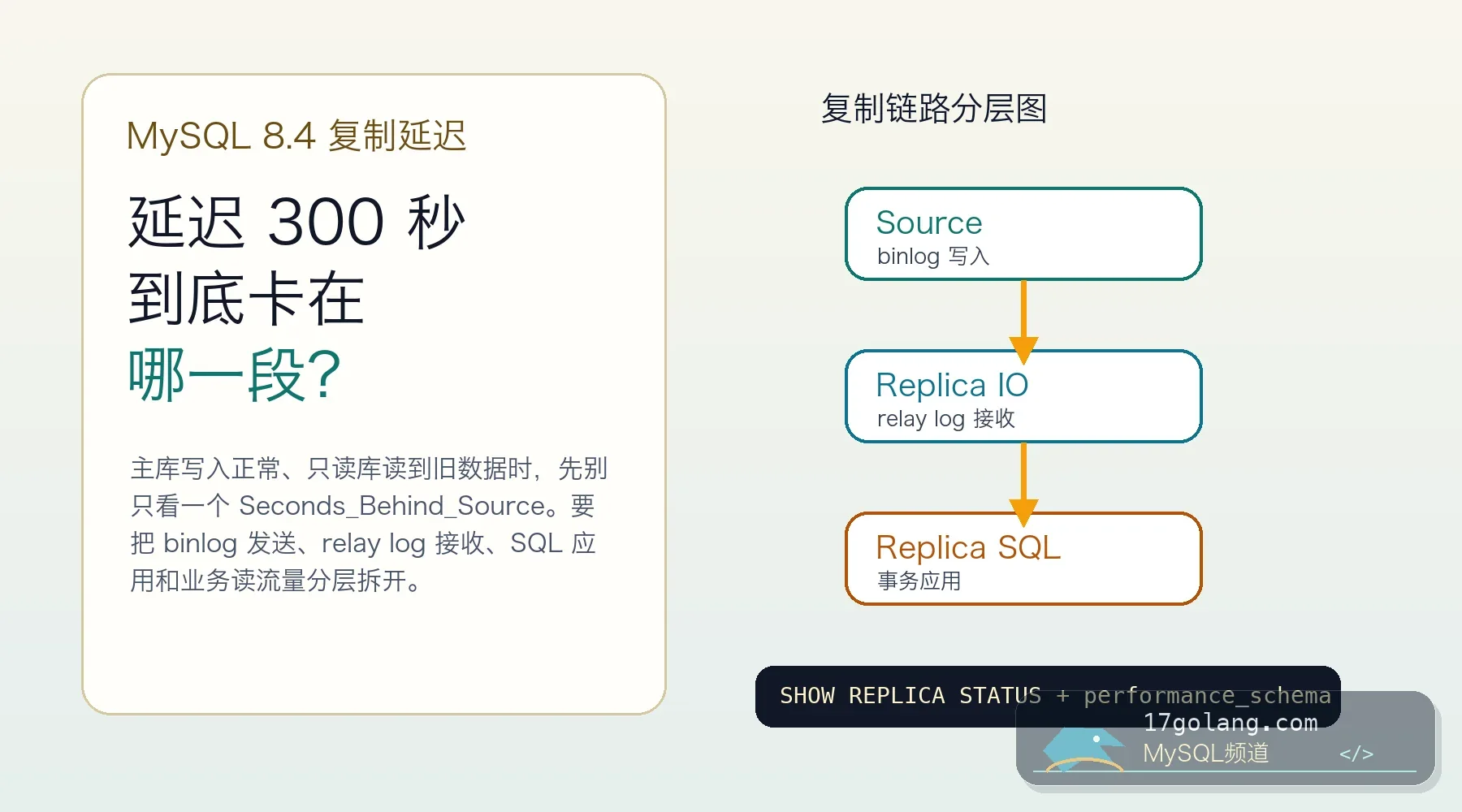 从只读库延迟导致读到旧数据的事故切入,讲清 MySQL 8.x 复制延迟如何区分 IO 接收、relay log 应用、大事务、并行复制和只读流量影响。119 收藏
从只读库延迟导致读到旧数据的事故切入,讲清 MySQL 8.x 复制延迟如何区分 IO 接收、relay log 应用、大事务、并行复制和只读流量影响。119 收藏