-

LocalDate.plusDays()语义上只支持加正数天数,负数虽可运行但属隐式兼容而非官方承诺;应改用minusDays()实现减法,以保证语义清晰、可读性强且避免静态分析警告。
-
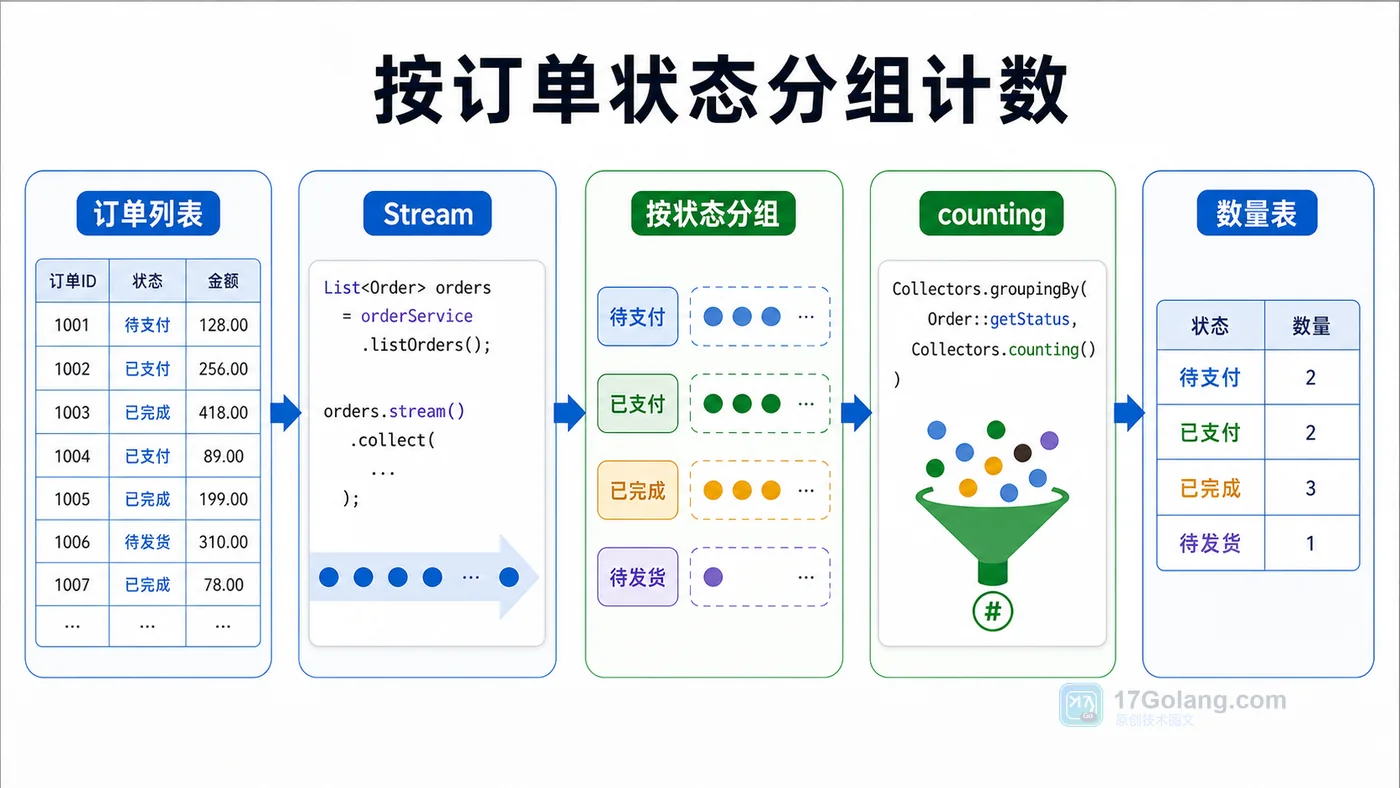
本文用订单列表示例讲清 Java Stream 分组统计:按状态分组计数、按用户汇总金额、用 summarizingInt 一次拿到数量、总和、最大值和平均值。
-

containsKey比get()+null判断更合适,因其能准确区分“键不存在”和“键存在但值为null”,避免误判缓存未命中;且不触发值构造或反序列化,线程安全,语义清晰。
-

最常见的原因是未指定-XX:HeapDumpPath,JVM默认写入当前工作目录,而生产环境常因权限不足、路径只读或磁盘满导致静默失败;必须显式指定可写且有足够空间的绝对路径。
-

TransactionSystemException报错需先查getCause(),90%为SQLException或ConnectionClosedException;常见原因包括连接池未校验连接有效性、本类方法调用导致事务失效、InnoDB锁等待超时。
-

Integer.parseInt()严格解析字符串为int,不接受null、空串、空格、非数字字符或溢出值,需前置校验和异常捕获;valueOf()返回缓存Integer对象;进制解析须先去除前缀;溢出时应改用BigInteger.intValueExact()等安全方式。
-

最可靠的判空方式是obj==null。它能准确识别未分配内存的对象,避免调用方法时抛出NullPointerException;其他方式如toString()或isEmpty()在null时会直接崩溃。
-

必须在main方法第一行调用System.setOut(),早于SpringApplication.run(),否则Banner、Actuator等组件及静态块中的System.out::println已固化输出流,重定向失效。
-

当需元素唯一且按插入顺序遍历时应选LinkedHashSet;它用哈希表+双向链表实现,遍历稳定O(n),顺序可预测,而HashSet无序、TreeSet按自然序排序。
-

Record类是Java16为DTO场景设计的不可变扁平数据载体,自动生成字段、构造器、getter、equals、hashCode和toString;组件名即访问器名(无get前缀);仅支持紧凑构造器校验,不支持继承。
-

普通ThreadLocal无法在父子线程间传递值是因为其值仅绑定当前线程的ThreadLocalMap,子线程为新实例且不复制父线程值;InheritableThreadLocal通过重写createInheritedMap()和childValue(),在子线程init时浅拷贝父线程值,但仅限直接创建的子线程,不适用于线程池等复用场景。
-

完成Java基础后应通过项目实践巩固知识,学生信息管理系统涵盖面向对象、集合与异常处理;2.系统功能包括增删改查学生信息;3.设计Student类封装属性并重写toString方法;4.使用ArrayList存储学生数据,Scanner接收用户输入;5.主逻辑在StudentManager中实现菜单循环与功能分支;6.添加学生时创建对象并存入列表;7.删除学生需遍历列表匹配学号并移除;8.修改与查询均基于学号定位目标对象;9.项目帮助理解代码真实运行流程,强化知识点串联。
-

JOL无法稳定捕捉锁升级全过程,因其仅解析Java堆内结构,而重量级锁指针在C++堆、轻量级锁地址在栈帧且易被JIT优化,偏向撤销时MarkWord可能被置零或全1;需禁用逃逸分析与JIT优化,单线程内分步新建对象并即时抓取布局,结合jstack验证重量级锁。
-

VectorAPI在JDK17中仍为孵化器模块,必须显式启用:运行时需添加--add-modulesjdk.incubator.vector,否则抛NoClassDefFoundError;SPECIES_PREFERRED返回平台推荐向量长度,但非绝对最优,应结合数据规模与硬件指令集(如AVX2/AVX-512)合理选用。
-

SimpleDateFormat非线程安全,多线程复用会导致结果错乱,应局部新建、加锁或改用DateTimeFormatter;parse()抛ParseException主因是字符串与模式不匹配,如时区缺失、月份超限、yy解析四位年份等;安全格式化需用局部变量指定模式及时区;DateTimeFormatter不可变、线程安全、API清晰,是Java8+推荐替代方案。