-

本文详解如何将Map<Integer,String>反转为Map<String,Integer>,解决因方法签名不匹配、静态上下文调用非静态方法等导致的编译错误,并提供可直接运行的完整示例。本文详解如何将`Map`反转为`Map`,解决因方法签名不匹配、静态上下文调用非静态方法等导致的编译错误,并提供可直接运行的完整示例。在Java中,将HashMap的键(Key)与值(Value)互换(即从<Int
-
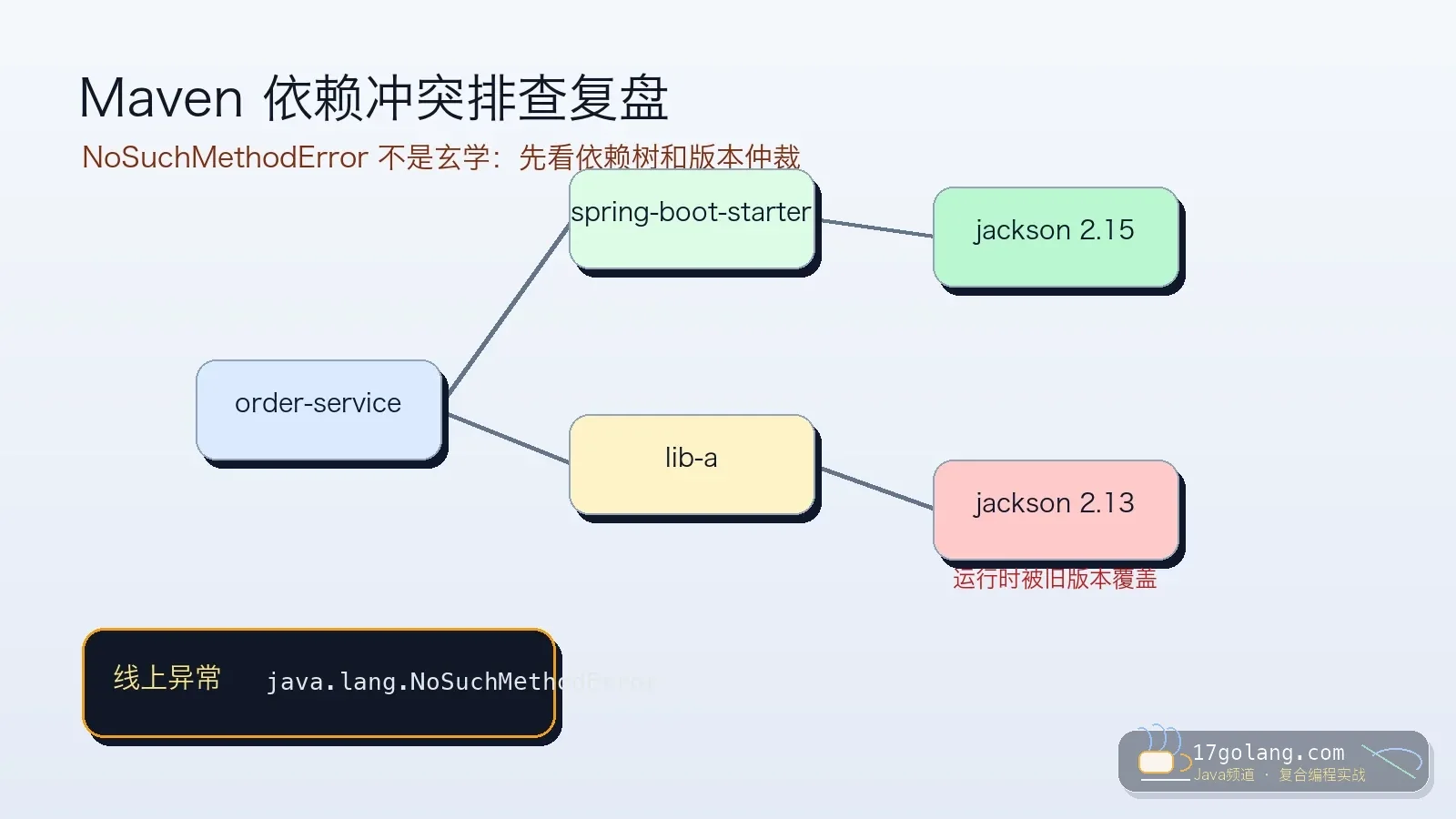
一次 Java/Spring Boot 依赖冲突排查复盘:从 NoSuchMethodError/ClassNotFoundException 出发,用 Maven dependency:tree、effective POM、BOM、dependencyManagement 和 exclusion 找到运行时类路径被污染的根因。
-

MapStruct需同时引入mapstruct与mapstruct-processor依赖且版本一致,启用注解处理器,@Mapper加componentModel="spring"使其成为SpringBean,空值策略分层级配置,自定义逻辑须外置工具类并通过uses声明。
-

双亲委派模型确保类加载的安全与唯一,其工作流程为:当类加载请求发起时,先由顶层启动类加载器尝试加载,失败后逐级向下委托,依次由扩展类加载器、应用程序类加载器尝试加载。该机制防止核心类被篡改,避免重复加载,保障系统稳定;典型应用场景包括SPI服务加载(如JDBC)和OSGi模块化框架,这些情况通过线程上下文类加载器或自定义加载逻辑打破双亲委派。
-

map将函数结果包装进Optional,flatMap要求函数返回Optional并自动展平一层,是避免嵌套Optional的唯一机制。
-

Java面向对象本质是建模现实世界的思维方式:类为模板定义属性与行为,对象为实例封装独立状态与共享逻辑;封装通过private+getter/setter控制访问并校验数据;继承支持单继承复用与分层;多态依托父类引用指向子类对象实现运行时动态绑定。
-

RejectedExecutionException是线程池的背压信号,表明任务队列已满且线程全忙,需结合poolsize、activethreads、queuedtasks定位根因,而非盲目调大参数。
-

Thread.UncaughtExceptionHandler没生效的主因是子线程异常默认静默终止,且全局处理器被覆盖或未统一配置;需通过ThreadFactory为线程池预设handler,验证时主动抛异常并确保handler轻量无副作用。
-

乐观读锁tryOptimisticRead成功当且仅当读期间未发生任何写操作;它仅读取版本戳,后续必须用validate验证,且只适用于轻量、无副作用的字段组合,validate为true后须立即使用数据。
-

Android开发中使用DecimalFormat(".2")无法正确显示小数位,因该模式缺少整数部分占位符;应改用String.format("%.2f",value)或修正DecimalFormat模式为"0.00"。
-

根本原因是注解处理器未启用或Lombok依赖配置不正确。需启用IDEA的AnnotationProcessors、检查pom.xml或build.gradle中compileOnly+annotationProcessor配置、重启IDEA并清理缓存。
-

HashMap性能退化主因是桶数量不足导致哈希碰撞概率上升,引发链表变长或树化;初始容量应按expectedSize/0.75向上取2的幂,兼顾低碰撞与内存效率。
-

UUID核心用途是无中心生成极大概率不重复的128位唯一标识符;常用randomUUID()生成版本4随机UUID,适合分布式主键、traceId等;nameUUIDFromBytes()生成版本3确定性UUID,适用于URL等输入映射;不可对版本4调用timestamp()等方法。
-

可以,但必须用FileOutputStream包装;PrintStream不接受文件路径字符串,正确写法是newPrintStream(newFileOutputStream("data.log"),true,StandardCharsets.UTF_8)。
-

应避免用异常控制流程,频繁抛出异常会因栈追踪导致性能下降。推荐预判条件代替try-catch校验,如用正则或NumberUtils判断数字格式;自定义异常可重写fillInStackTrace返回this以减少开销;捕获时应优先具体异常,合理使用multi-catch合并处理;延迟构建异常信息,避免无谓的字符串拼接,提升性能。