java教程技术文章
-
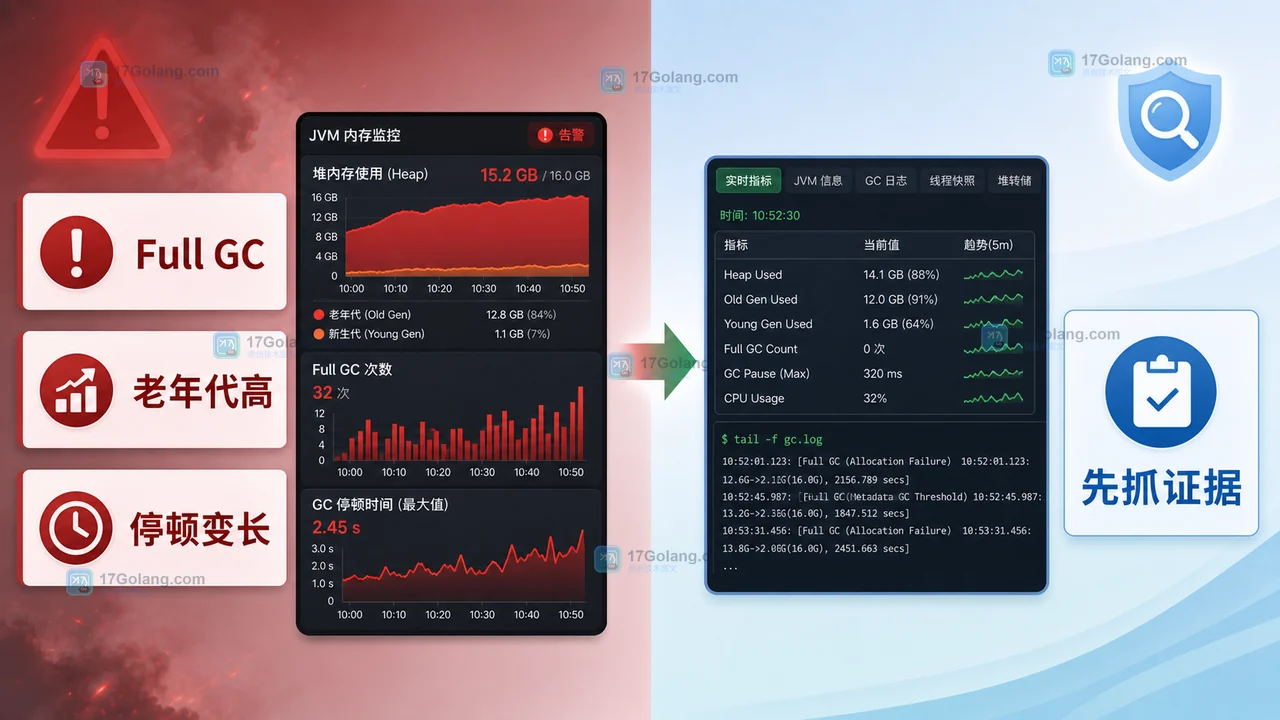 Java 服务频繁 Full GC 时,先看老年代占用、停顿时间和业务错误,再抓取堆信息与线程状态。不要一上来放大堆或重启,优先保留证据、控制流量、回滚可疑发布,并用告警恢复情况确认处理结果。136 收藏
Java 服务频繁 Full GC 时,先看老年代占用、停顿时间和业务错误,再抓取堆信息与线程状态。不要一上来放大堆或重启,优先保留证据、控制流量、回滚可疑发布,并用告警恢复情况确认处理结果。136 收藏 -
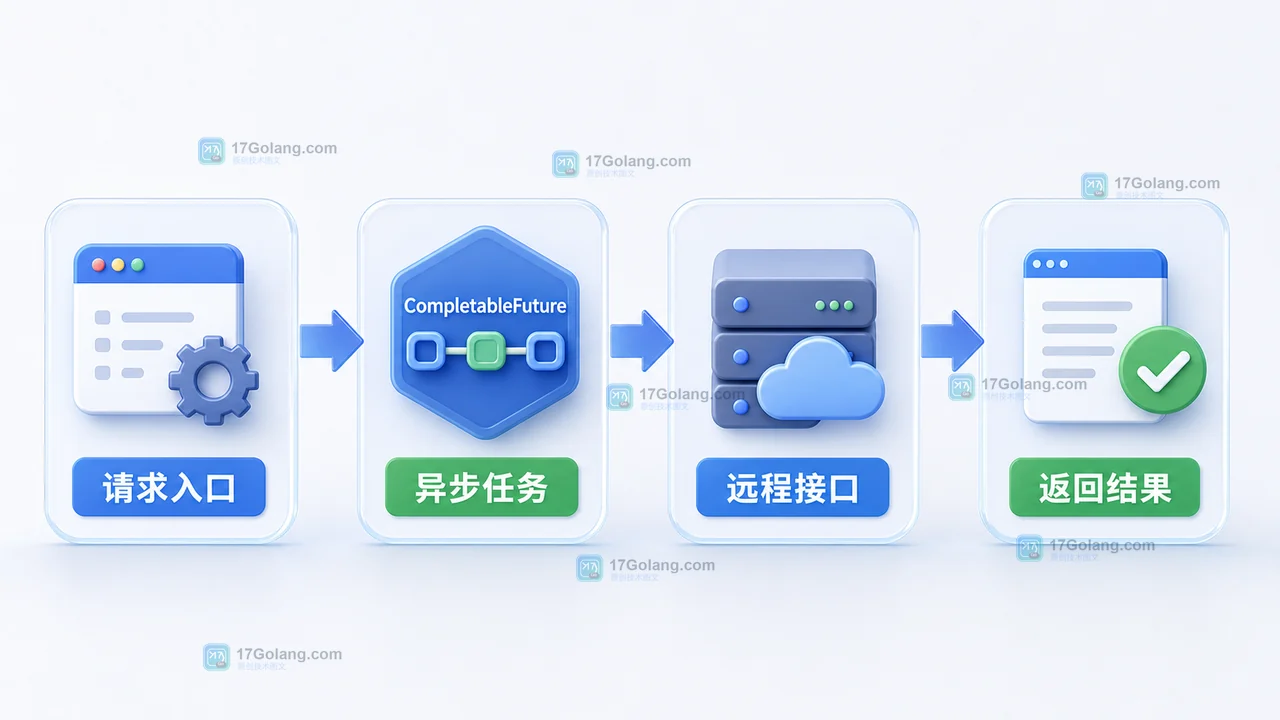 Java 后端接口调用远程服务时,不能只把同步等待套进 CompletableFuture 就结束,还要处理超时、兜底值和异常记录。本文用一个小实验演示 supplyAsync、orTimeout、completeOnTimeout 和 join 的组合写法,让页面在远程接口变慢时仍能给出可控响应。304 收藏
Java 后端接口调用远程服务时,不能只把同步等待套进 CompletableFuture 就结束,还要处理超时、兜底值和异常记录。本文用一个小实验演示 supplyAsync、orTimeout、completeOnTimeout 和 join 的组合写法,让页面在远程接口变慢时仍能给出可控响应。304 收藏 -
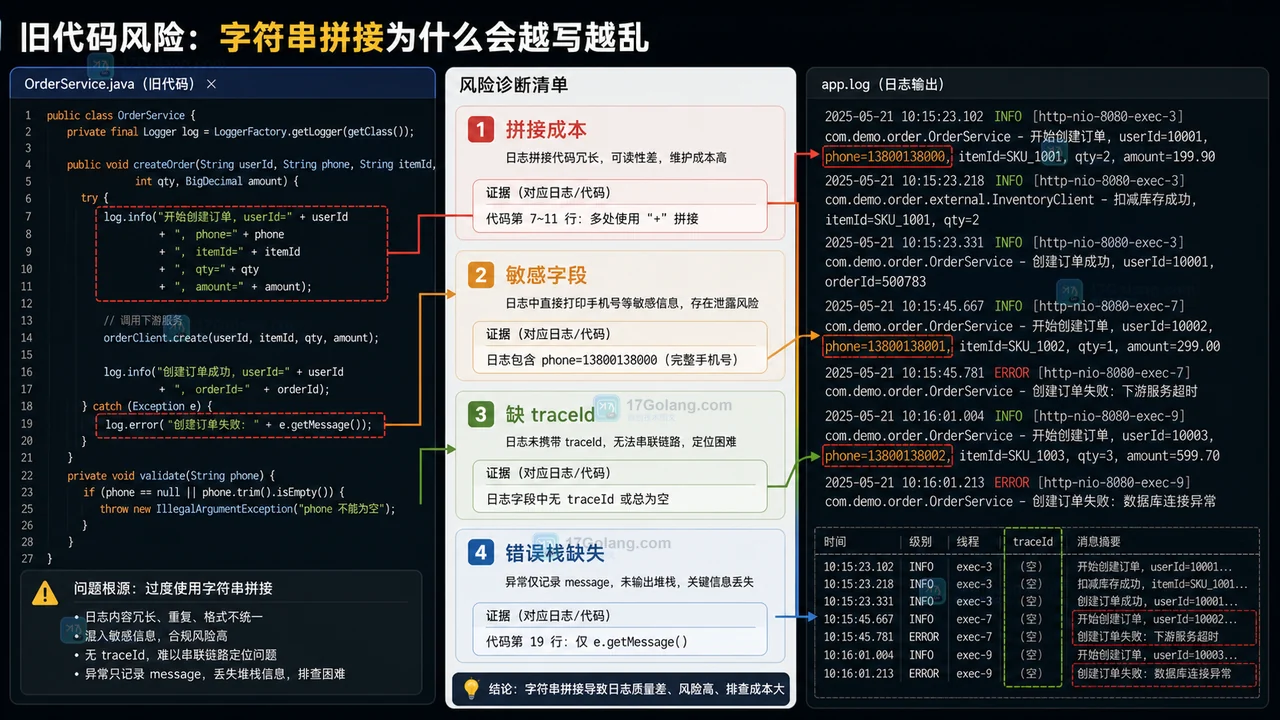 围绕 Java 老项目日志迁移,说明如何从字符串拼接改成 SLF4J 参数化日志,并补上 MDC traceId、脱敏规则和回归检查,让日志更可查也更稳。182 收藏
围绕 Java 老项目日志迁移,说明如何从字符串拼接改成 SLF4J 参数化日志,并补上 MDC traceId、脱敏规则和回归检查,让日志更可查也更稳。182 收藏 -
文章 · java教程 | 3星期前 | 性能优化 · Java教程 · CompletableFuture · 接口聚合 · java completablefuture orTimeout completeOnTimeout 接口性能 P95
 用指标驱动方式讲解 Java CompletableFuture 聚合接口优化:先建立串行调用基线,再改为并发请求、设置超时兜底,最后用 P95、错误率和慢依赖占比验证效果。255 收藏
用指标驱动方式讲解 Java CompletableFuture 聚合接口优化:先建立串行调用基线,再改为并发请求、设置超时兜底,最后用 P95、错误率和慢依赖占比验证效果。255 收藏 -
文章 · java教程 | 3星期前 | Spring Boot · Java教程 · 接口设计 · Webhook · 幂等设计 · java spring boot WebHook 回调接口 幂等 状态流转 验签
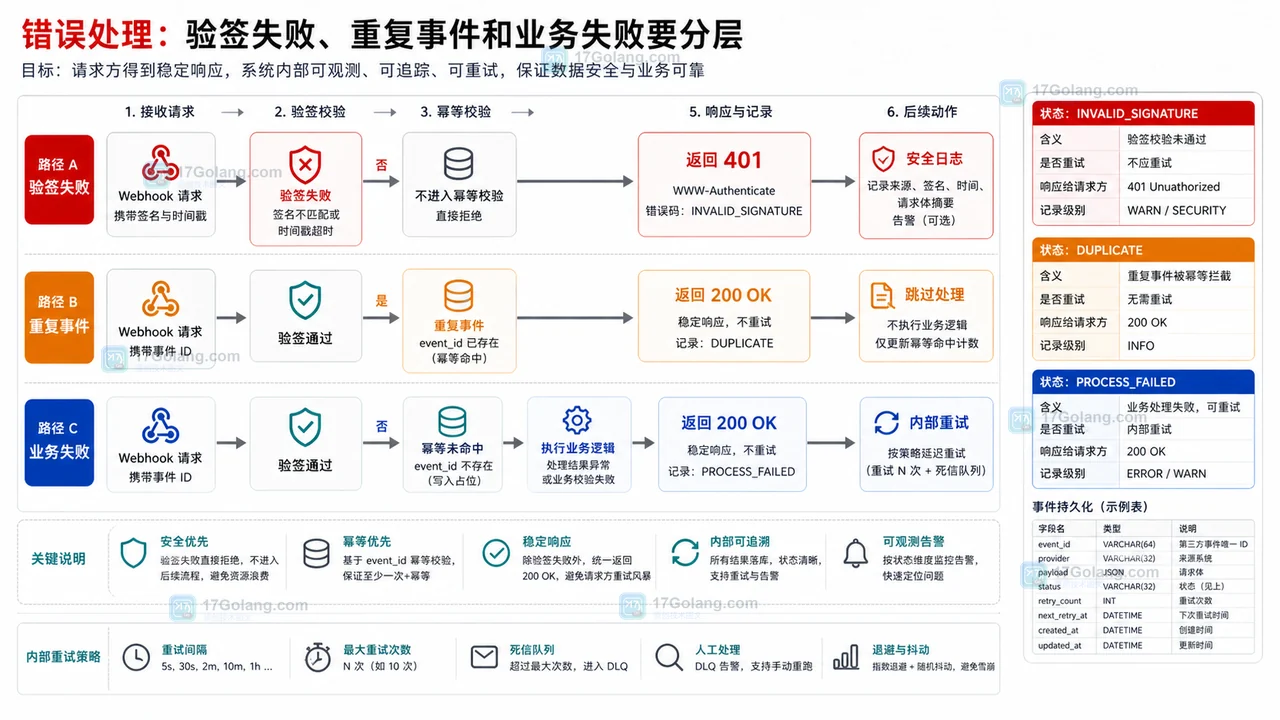 本文从 Java 服务接收第三方 Webhook 的接口设计出发,说明如何定义回调目标、验签参数、幂等键、错误响应、状态流转和兼容策略,避免重复通知和伪造请求。488 收藏
本文从 Java 服务接收第三方 Webhook 的接口设计出发,说明如何定义回调目标、验签参数、幂等键、错误响应、状态流转和兼容策略,避免重复通知和伪造请求。488 收藏 -
文章 · java教程 | 3星期前 | Java教程 · TTL缓存 · ConcurrentHashMap · 小项目 · java 本地缓存 concurrenthashmap TTL缓存 过期淘汰
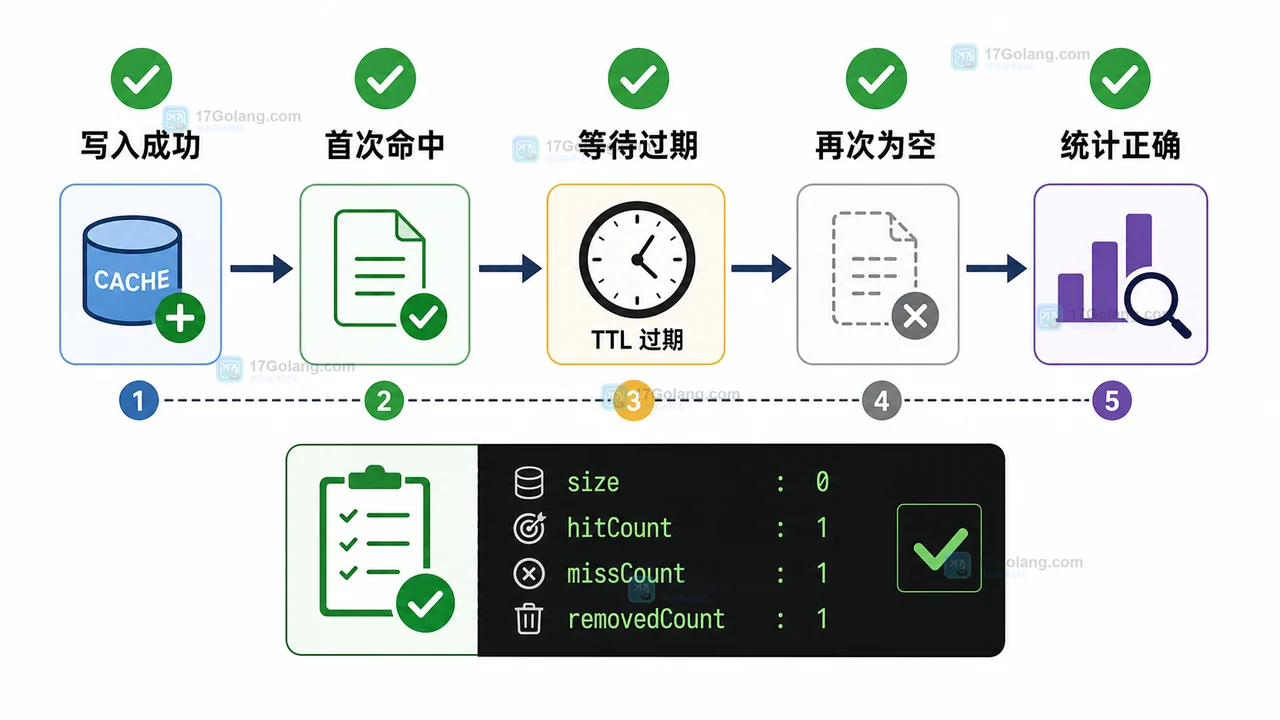 从零实现一个可运行的 Java 本地 TTL 缓存,包含写入、读取、过期淘汰、命中统计和本地验收,适合作为接口临时缓存或小工具缓存的入门项目。394 收藏
从零实现一个可运行的 Java 本地 TTL 缓存,包含写入、读取、过期淘汰、命中统计和本地验收,适合作为接口临时缓存或小工具缓存的入门项目。394 收藏 -
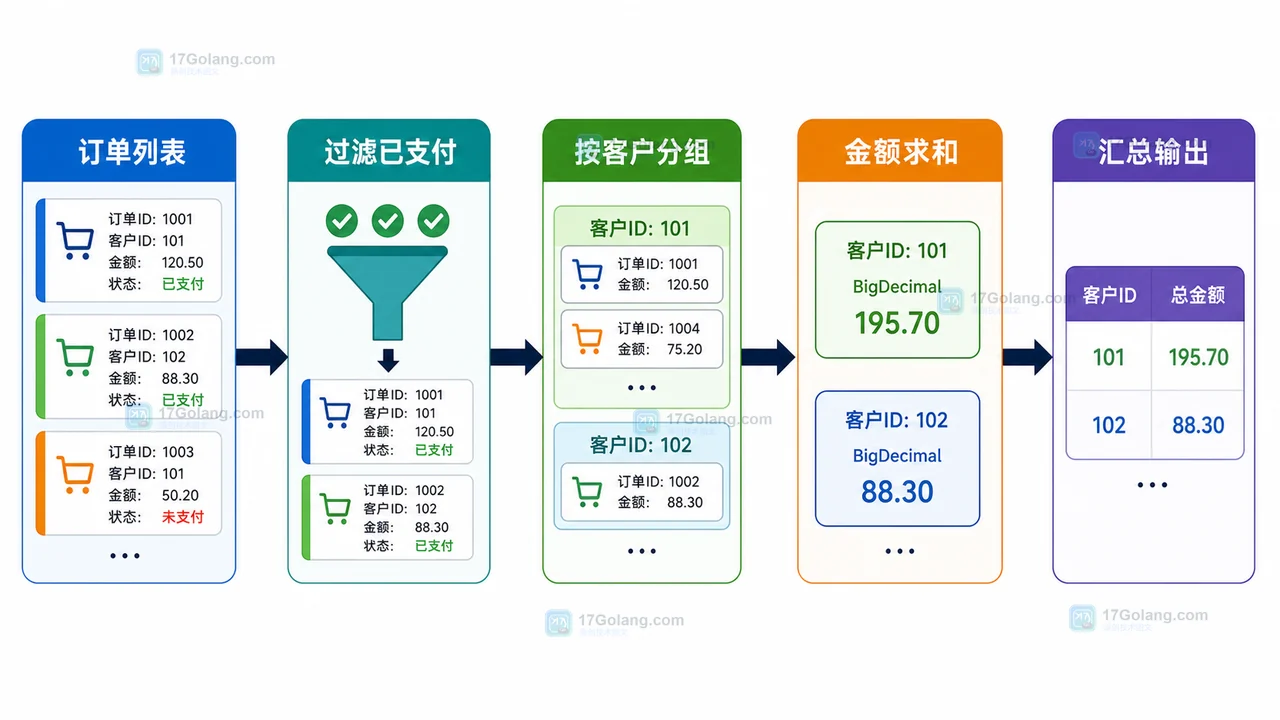 用一个可运行的小实验演示 Java Stream 如何把订单列表过滤、分组、金额求和并输出客户消费汇总,补充双维度统计和常见坑检查。355 收藏
用一个可运行的小实验演示 Java Stream 如何把订单列表过滤、分组、金额求和并输出客户消费汇总,补充双维度统计和常见坑检查。355 收藏 -
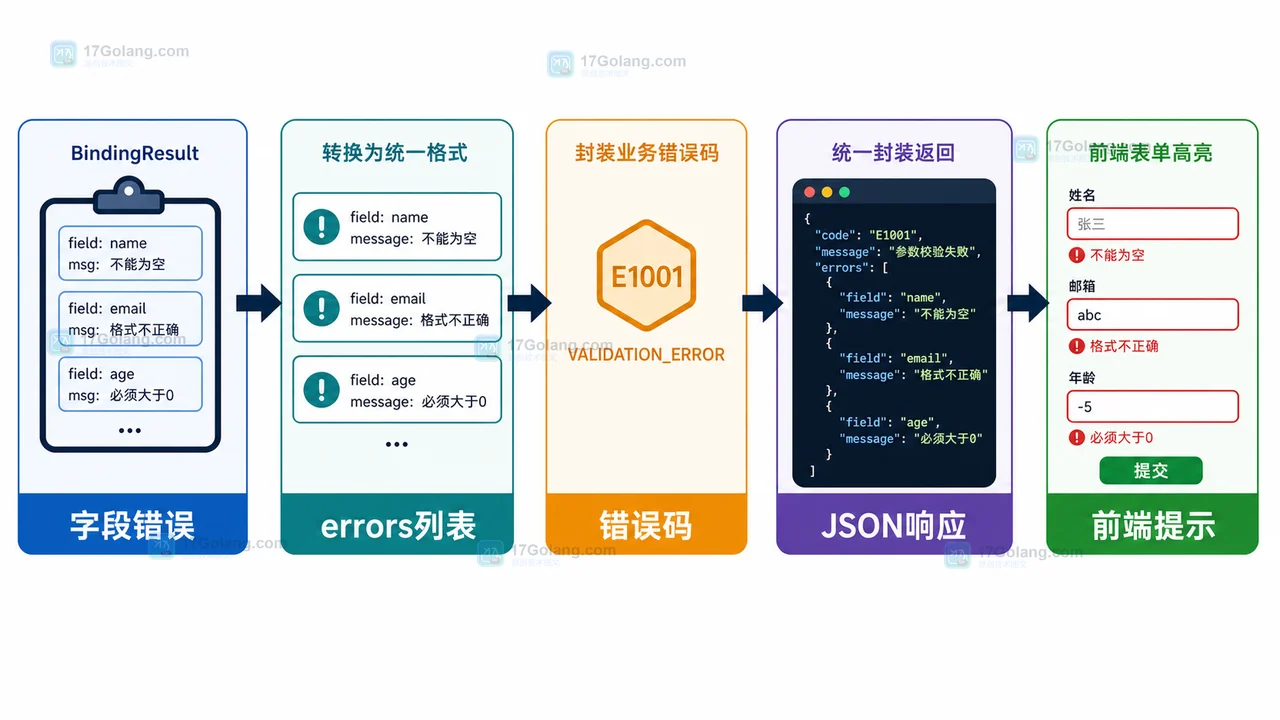 梳理 Spring Boot 接口参数校验完整工作流:定义 DTO 边界、添加校验注解、触发 @Valid、统一错误响应,并给出常见误区和速查表。495 收藏
梳理 Spring Boot 接口参数校验完整工作流:定义 DTO 边界、添加校验注解、触发 @Valid、统一错误响应,并给出常见误区和速查表。495 收藏 -
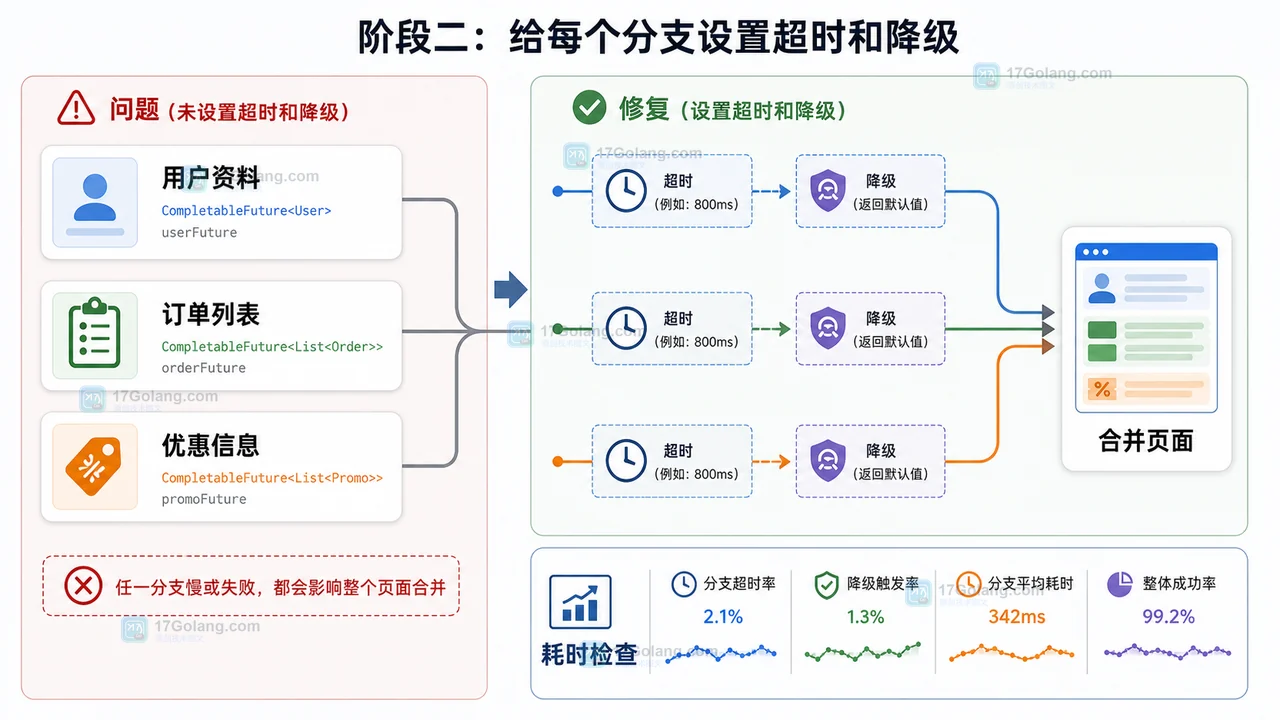 本文用一个用户首页聚合场景,梳理 Java CompletableFuture 的并发拉取、超时边界、异常兜底、结果合并和上线检查流程,让接口聚合在慢依赖下仍能稳定返回。365 收藏
本文用一个用户首页聚合场景,梳理 Java CompletableFuture 的并发拉取、超时边界、异常兜底、结果合并和上线检查流程,让接口聚合在慢依赖下仍能稳定返回。365 收藏 -
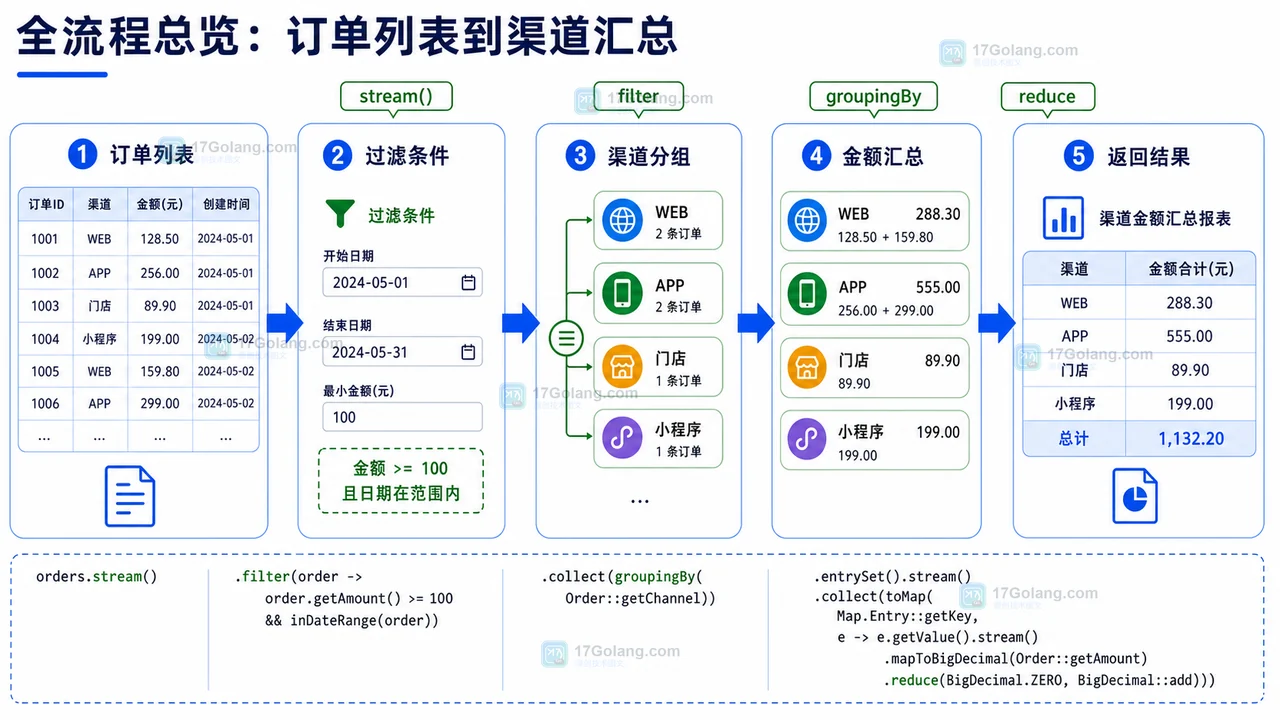 本文用订单列表统计场景,梳理 Java Stream 的完整处理流程:字段口径、过滤条件、分组汇总、结果校验和常见误区,帮助把零散链式调用整理成可复用的后端数据处理方案。455 收藏
本文用订单列表统计场景,梳理 Java Stream 的完整处理流程:字段口径、过滤条件、分组汇总、结果校验和常见误区,帮助把零散链式调用整理成可复用的后端数据处理方案。455 收藏 -
文章 · java教程 | 1个月前 | hashmap · 集合 · Java教程 · hashCode · equals · java HashMap map equals hashCode 可变key
 本文从一个 HashMap 放入键值对后修改 key 属性,后续 get 返回 null 的现场出发,逐步复现问题,解释 hashCode、equals 和桶定位的关系,并给出不可变 key、稳定 ID、先删后放和单测兜底的修复方案。474 收藏
本文从一个 HashMap 放入键值对后修改 key 属性,后续 get 返回 null 的现场出发,逐步复现问题,解释 hashCode、equals 和桶定位的关系,并给出不可变 key、稳定 ID、先删后放和单测兜底的修复方案。474 收藏 -
 本文用完整工作流讲解 Java 接口幂等设计:请求标识、入口校验、Redis SETNX 防重、数据库唯一键兜底、超时查询和补偿状态。178 收藏
本文用完整工作流讲解 Java 接口幂等设计:请求标识、入口校验、Redis SETNX 防重、数据库唯一键兜底、超时查询和补偿状态。178 收藏 -
文章 · java教程 | 1个月前 | map · 并发安全 · 缓存设计 · Java教程 · java optional concurrenthashmap computeIfAbsent Map缓存
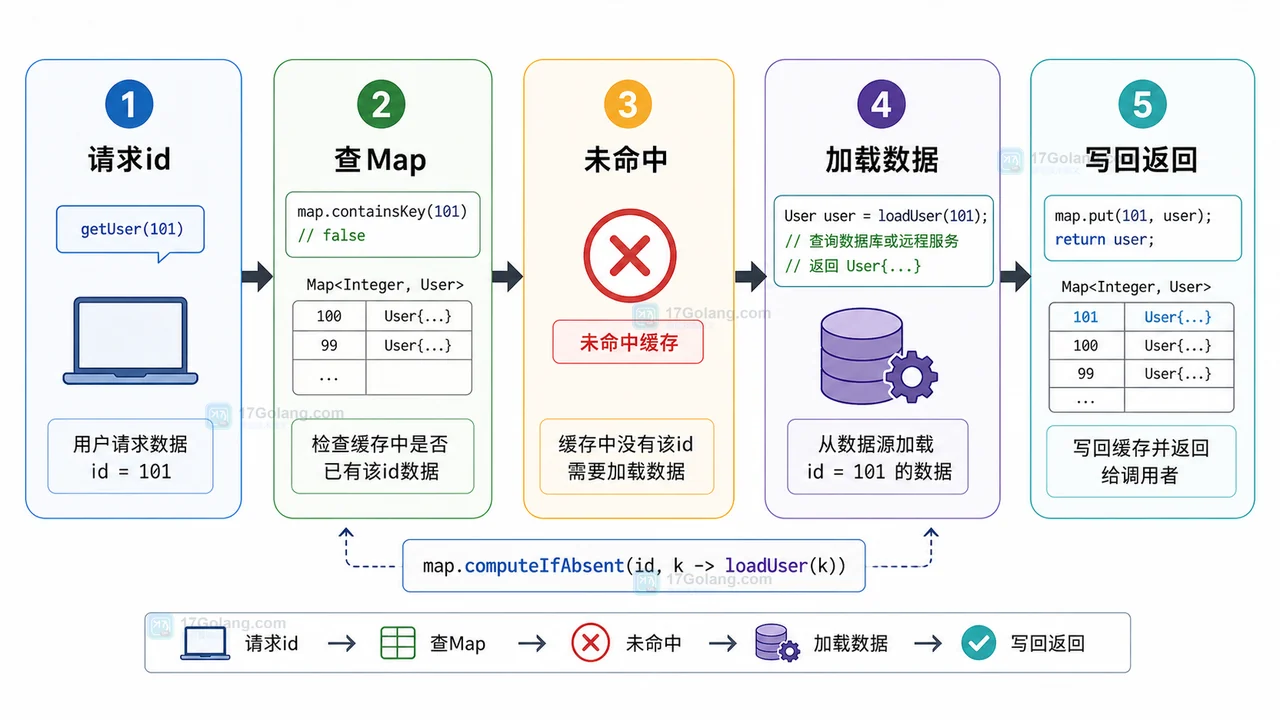 本文用一个用户资料缓存场景,完整拆解 Java Map computeIfAbsent 的使用边界、缺失加载、空值包装、并发 Map 选择和上线前检查,帮助你写出更简洁且行为可控的缓存初始化代码。236 收藏
本文用一个用户资料缓存场景,完整拆解 Java Map computeIfAbsent 的使用边界、缺失加载、空值包装、并发 Map 选择和上线前检查,帮助你写出更简洁且行为可控的缓存初始化代码。236 收藏 -
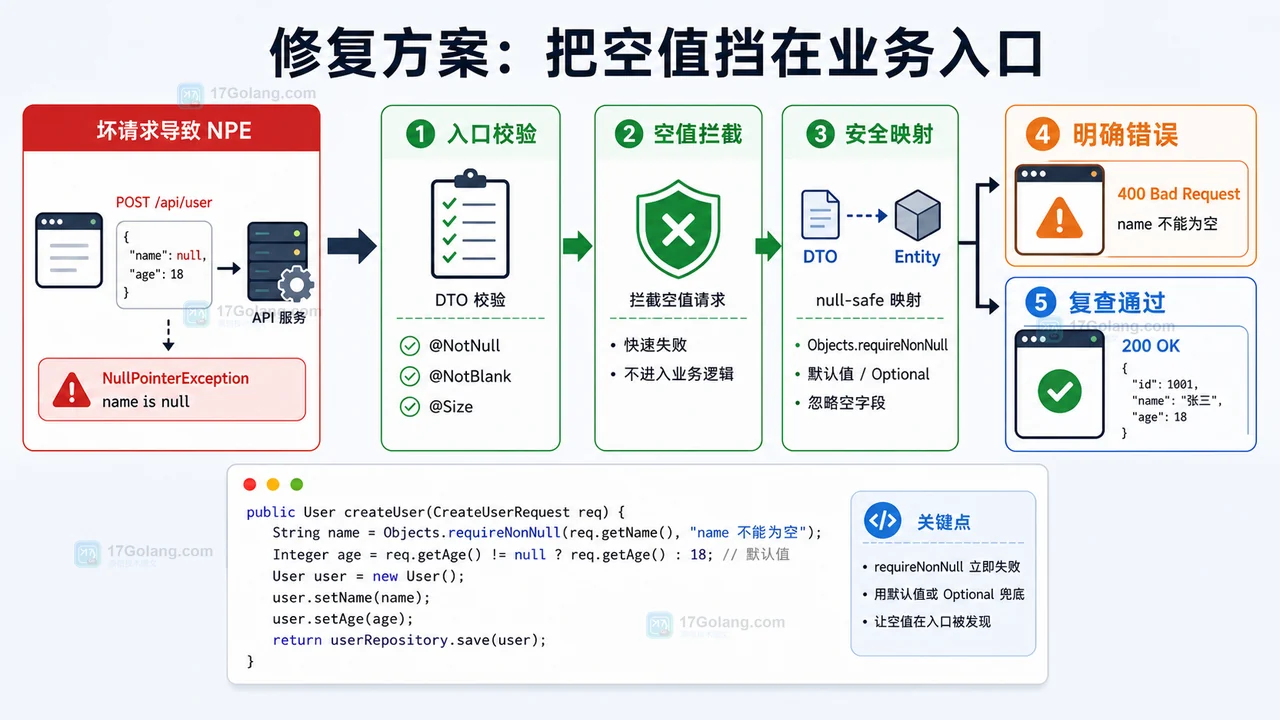 Java 后端线上出现 NullPointerException 时,不要只在报错行补 if。本文从日志定位开始,复现空字段请求,逐步确认根因,并用入口校验、安全映射和复查用例降低同类问题。204 收藏
Java 后端线上出现 NullPointerException 时,不要只在报错行补 if。本文从日志定位开始,复现空字段请求,逐步确认根因,并用入口校验、安全映射和复查用例降低同类问题。204 收藏 -
文章 · java教程 | 1个月前 | Java · 集合 · ArrayList · Iterator · removeIf · java iterator ArrayList ConcurrentModificationException removeIf
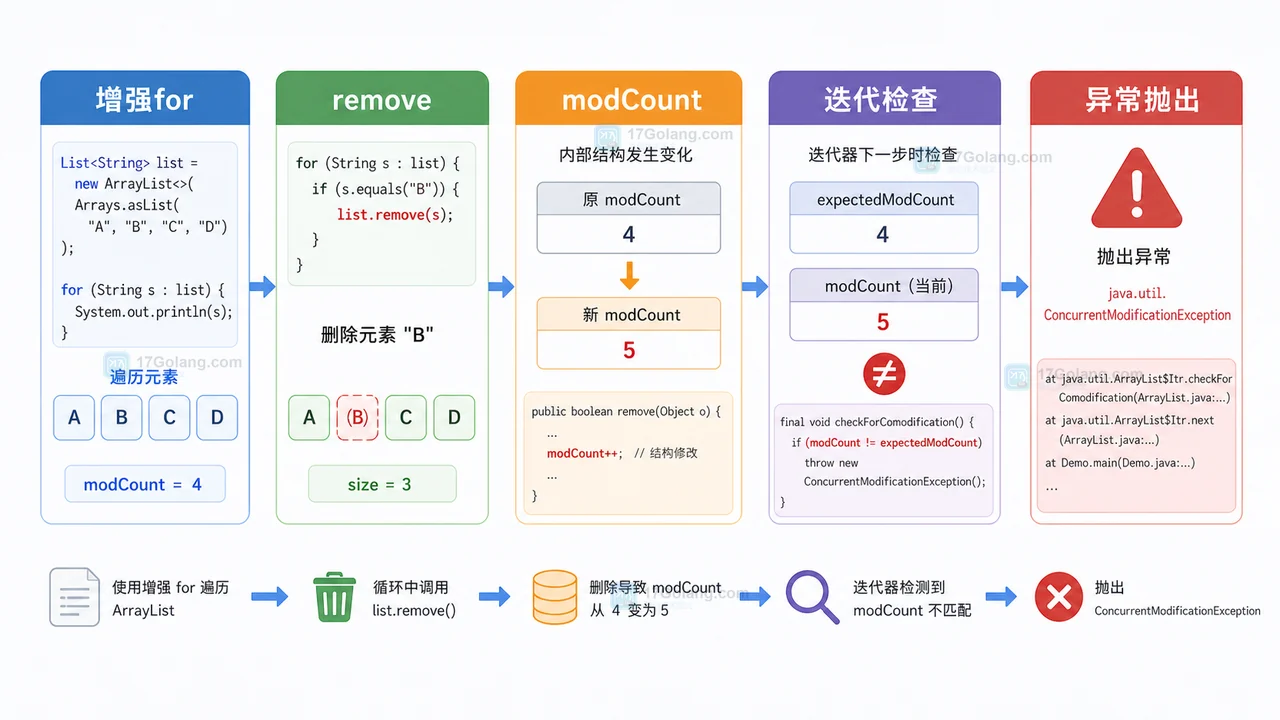 ArrayList 遍历时删除元素很容易抛 ConcurrentModificationException。本文按完整流程拆解增强 for、modCount、迭代器检查机制,并给出 Iterator.remove、removeIf、复制新列表三种安全方案。410 收藏
ArrayList 遍历时删除元素很容易抛 ConcurrentModificationException。本文按完整流程拆解增强 for、modCount、迭代器检查机制,并给出 Iterator.remove、removeIf、复制新列表三种安全方案。410 收藏