Go语言技术文章
-
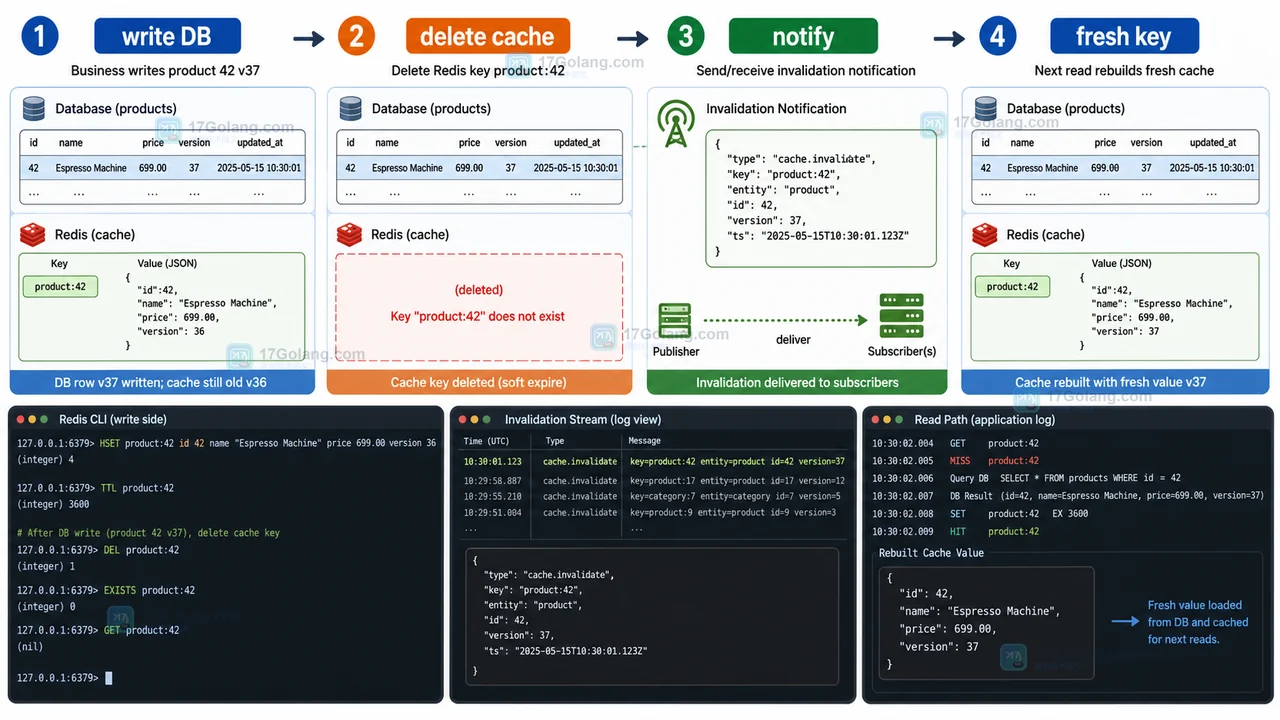 从 Redis 缓存治理趋势出发,分析单一 TTL 的不足,给出软过期、写侧失效通知、新鲜度指标和渐进落地路径,帮助团队在高峰流量下减少脏读窗口。280 收藏
从 Redis 缓存治理趋势出发,分析单一 TTL 的不足,给出软过期、写侧失效通知、新鲜度指标和渐进落地路径,帮助团队在高峰流量下减少脏读窗口。280 收藏 -
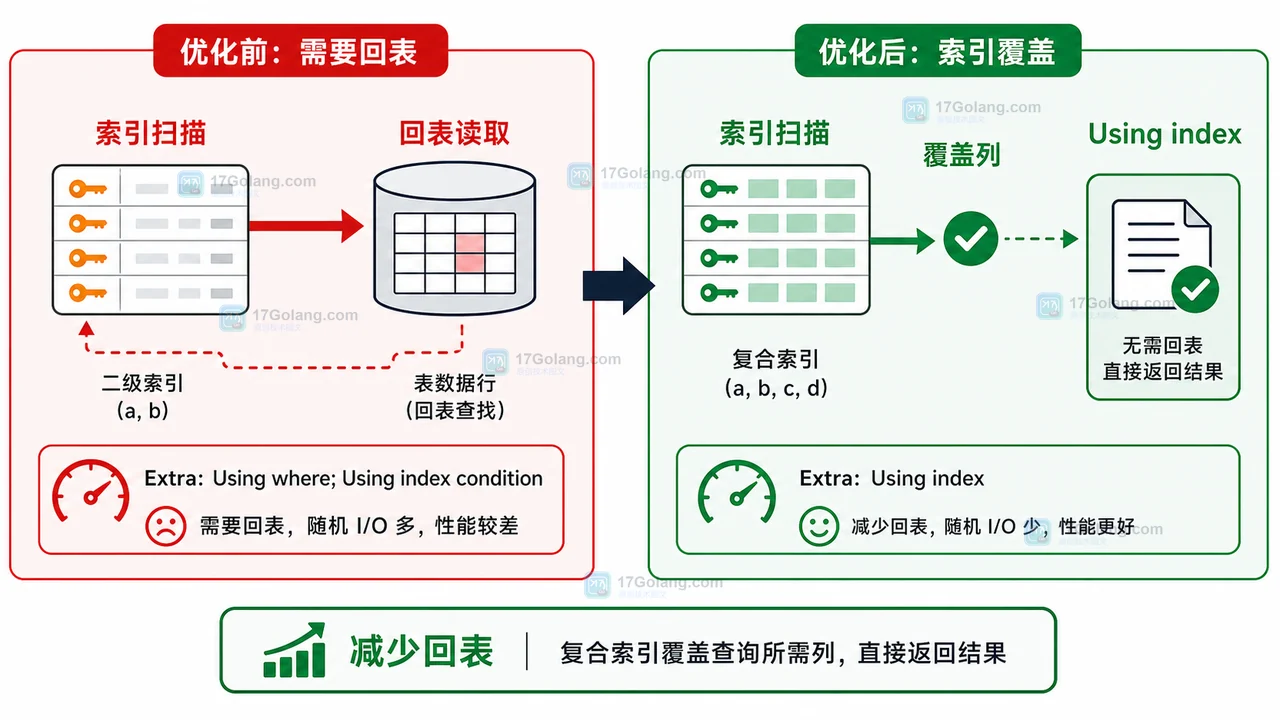 通过一个可复现的小实验,从订单列表慢查询开始,初始化表和数据,添加复合索引,再用 EXPLAIN 检查 Using index,理解覆盖索引的适用边界。276 收藏
通过一个可复现的小实验,从订单列表慢查询开始,初始化表和数据,添加复合索引,再用 EXPLAIN 检查 Using index,理解覆盖索引的适用边界。276 收藏 -
 用自然问答方式说明国家医保服务平台亲情账户、家庭共济和医保钱包的区别,配合官方页面和应用商店真实截图,提醒入口辨别、绑定使用和隐私安全。276 收藏
用自然问答方式说明国家医保服务平台亲情账户、家庭共济和医保钱包的区别,配合官方页面和应用商店真实截图,提醒入口辨别、绑定使用和隐私安全。276 收藏 -
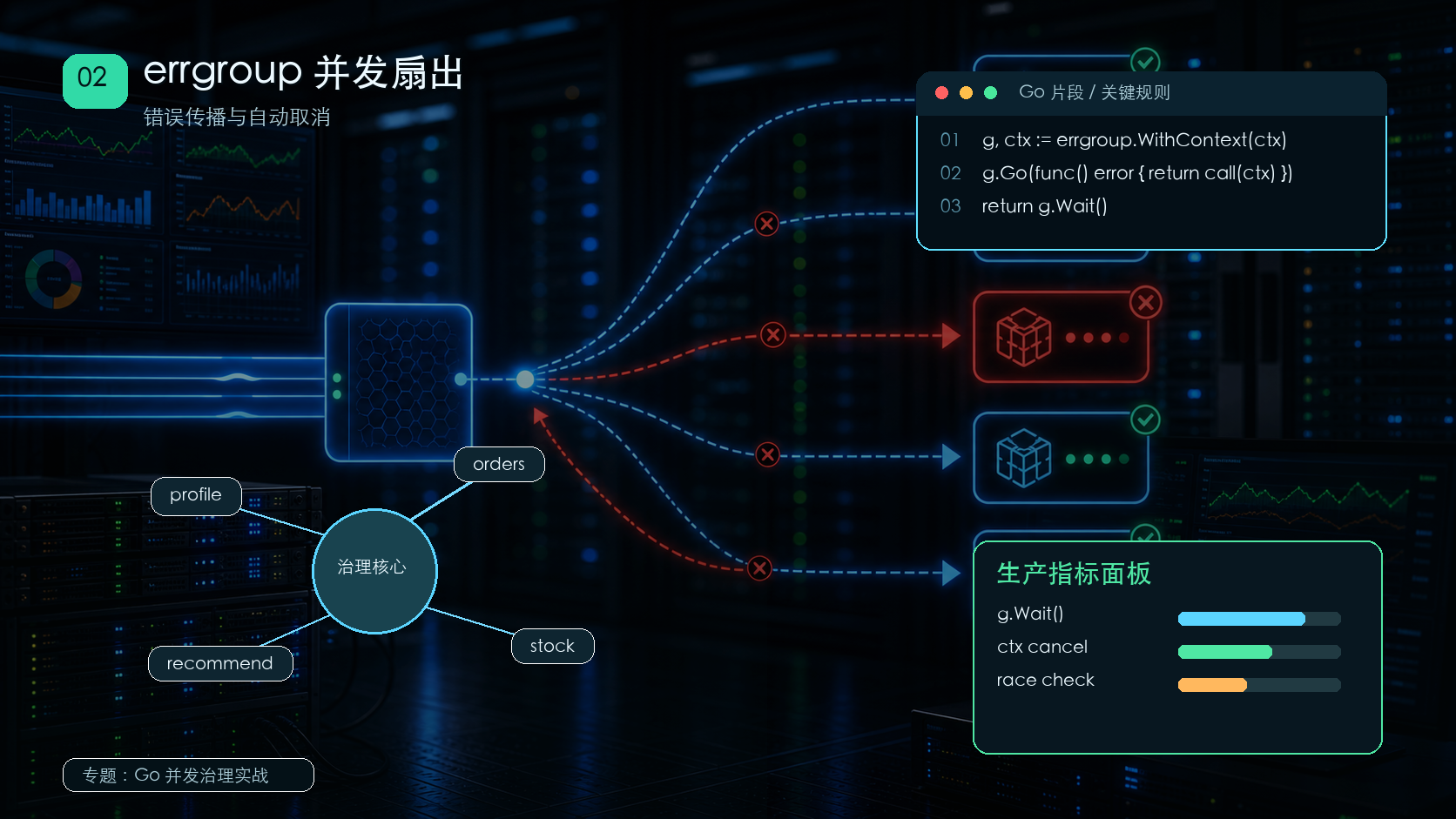 使用 errgroup.WithContext 同时启动多个下游任务,并在任一任务失败时取消其它任务。273 收藏
使用 errgroup.WithContext 同时启动多个下游任务,并在任一任务失败时取消其它任务。273 收藏 -
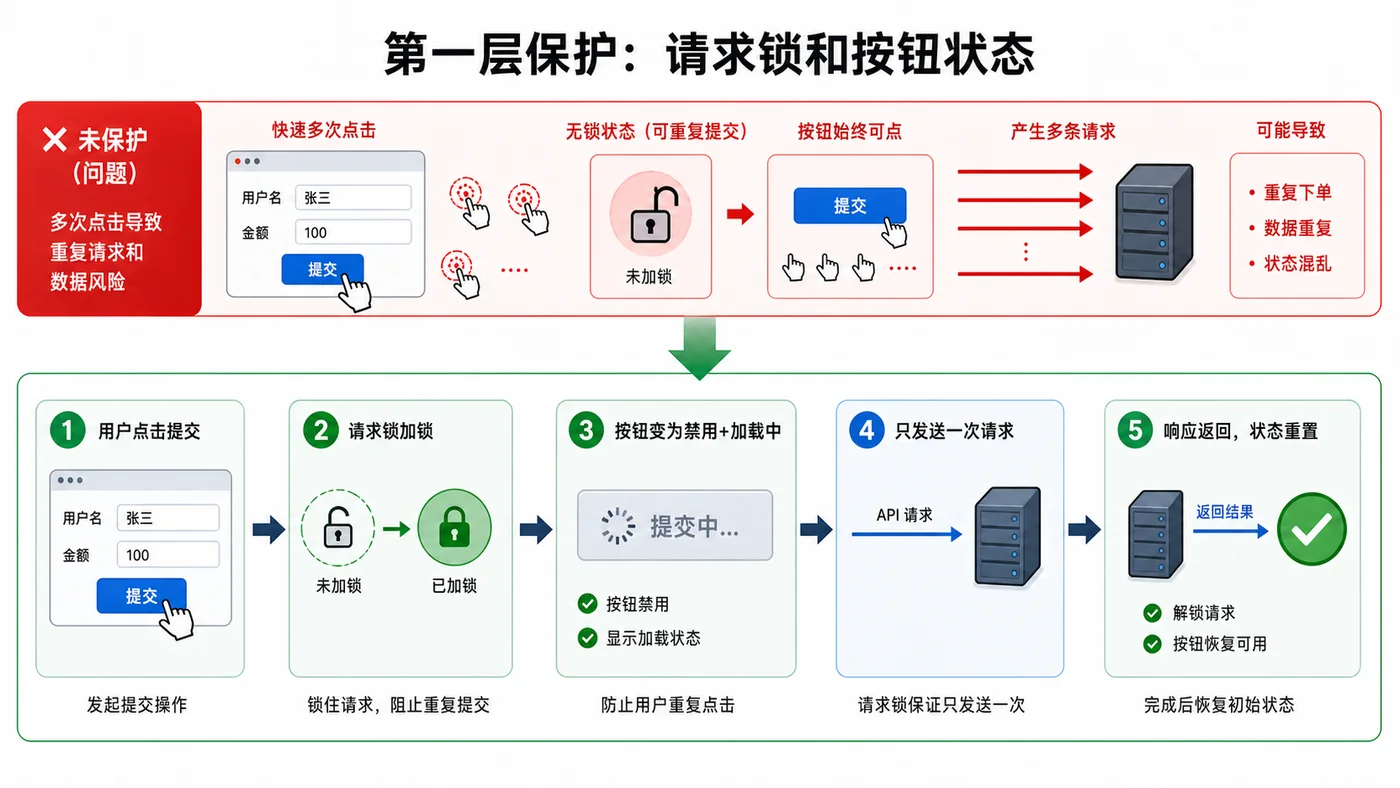 本文从用户连续点击提交按钮的真实场景出发,讲解前端如何用请求锁、按钮禁用、幂等请求头和失败回滚来减少重复订单、重复保存和重复消息。273 收藏
本文从用户连续点击提交按钮的真实场景出发,讲解前端如何用请求锁、按钮禁用、幂等请求头和失败回滚来减少重复订单、重复保存和重复消息。273 收藏 -
Golang · Go教程 | 3星期前 | map · 并发安全 · RWMutex · sync.Map · Go教程 · 并发安全 RWMutex sync.Map Go map并发读写 go test race
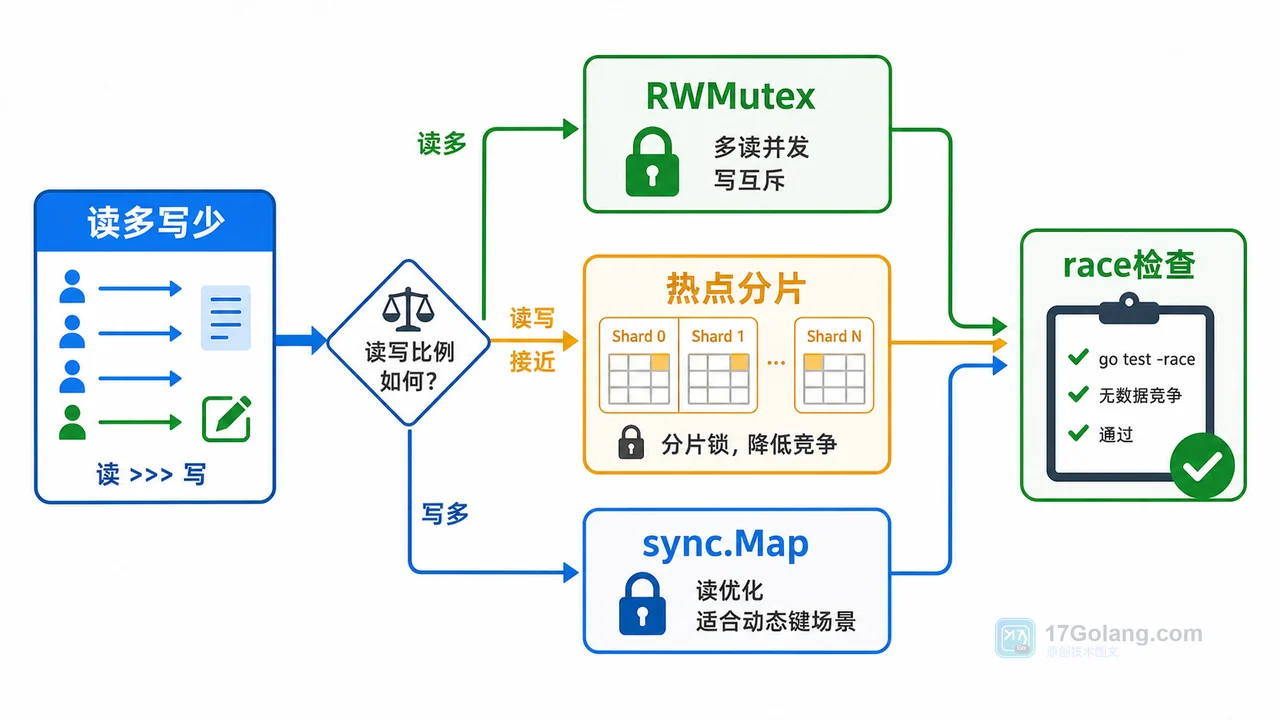 Go 原生 map 不能在无保护情况下并发读写。本文用完整工作流拆解:先复现 fatal error,再用 race 检查定位,随后用 RWMutex 修复,并说明分片 map 和 sync.Map 的选型边界。272 收藏
Go 原生 map 不能在无保护情况下并发读写。本文用完整工作流拆解:先复现 fatal error,再用 race 检查定位,随后用 RWMutex 修复,并说明分片 map 和 sync.Map 的选型边界。272 收藏 -
数据库 · MySQL | 4星期前 | 性能优化 · InnoDB · MySQL教程 · 数据库运维 · 高并发写入 · mysql innodb 批量写入 Change Buffer innodb_change_buffering
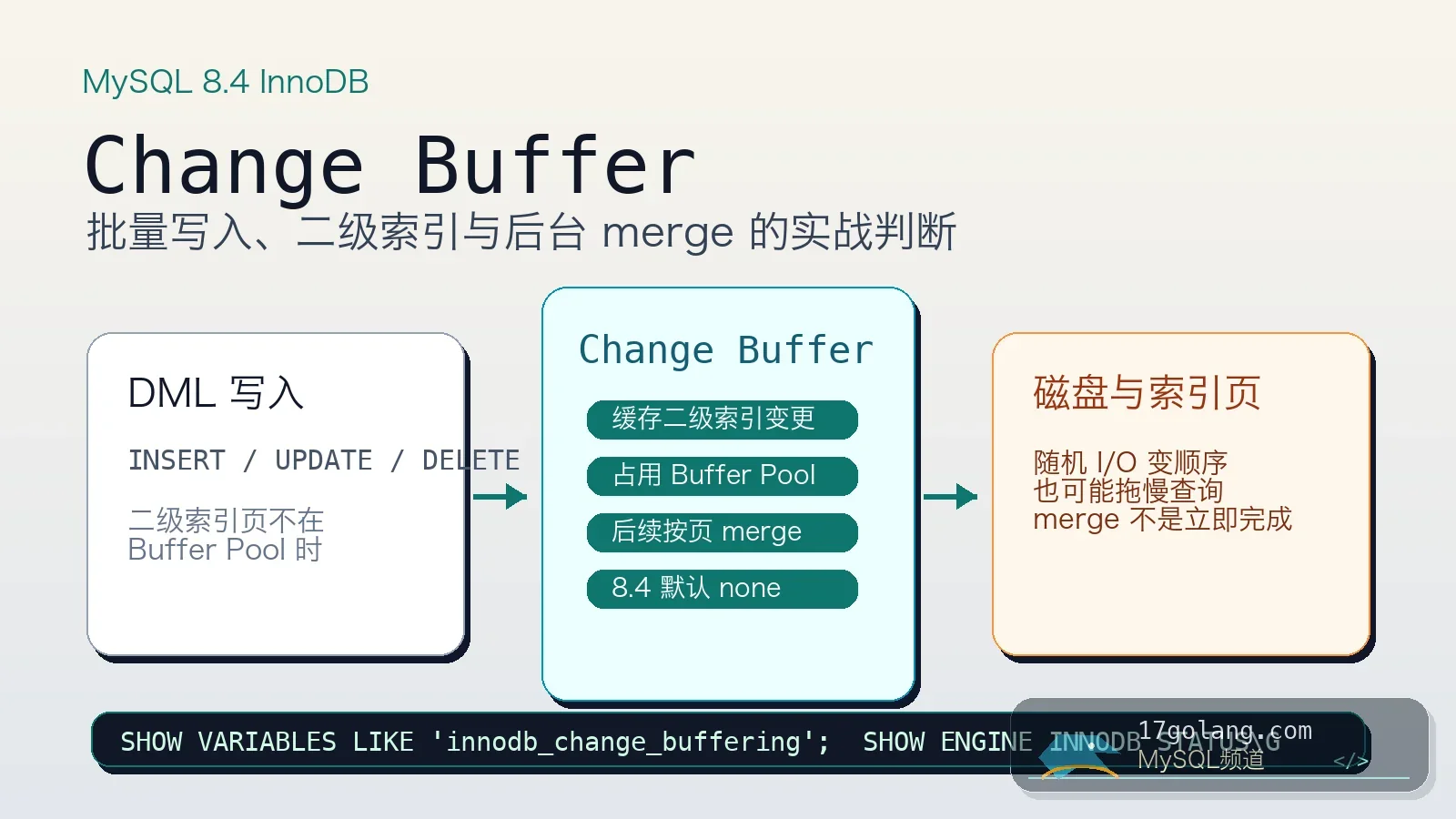 从 MySQL 8.4 InnoDB Change Buffer 默认值变化入手,讲清批量写入、二级索引随机 I/O、merge 观察和上线回滚。270 收藏
从 MySQL 8.4 InnoDB Change Buffer 默认值变化入手,讲清批量写入、二级索引随机 I/O、merge 观察和上线回滚。270 收藏 -
Golang · Go问答 | 5天前 | 中间件 · Context · Go问答 · 架构模式 · 代码边界 · 中间件 context Context.Value Go问答 WithValue 请求作用域 业务参数
 Go context 可以放用户 ID、traceID 这类请求作用域值,但不适合替代函数参数。本文用中间件、Service 和 Repository 的边界示例说明怎么判断。269 收藏
Go context 可以放用户 ID、traceID 这类请求作用域值,但不适合替代函数参数。本文用中间件、Service 和 Repository 的边界示例说明怎么判断。269 收藏 -
文章 · java教程 | 3星期前 | Java · 文件读取 · 异常处理 · 资源管理 · try-with-resources · java 异常处理 try-with-resources 资源关闭 AutoCloseable 文件流
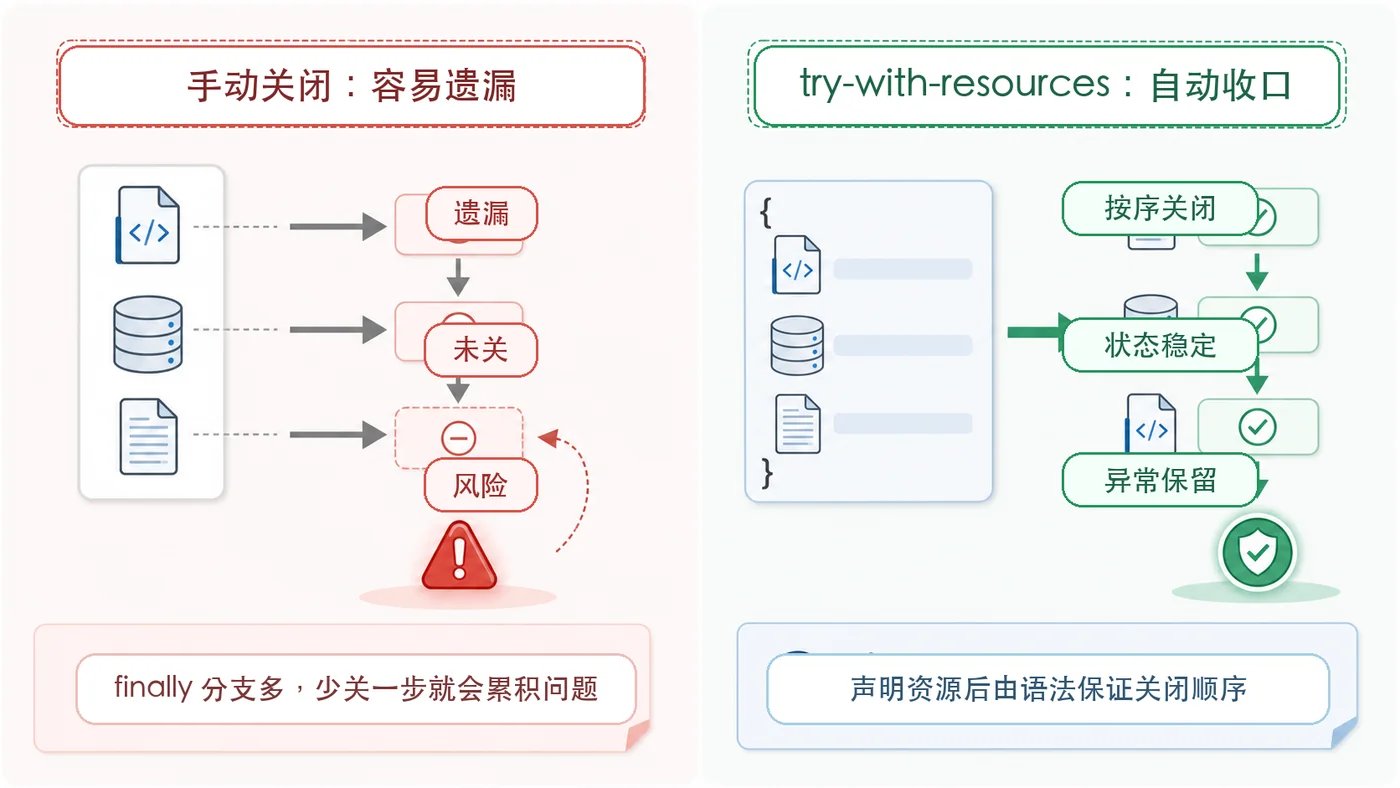 本文用文件读取和目录扫描两个场景,演示 Java try-with-resources 如何自动关闭资源、控制关闭顺序,并避免 finally 分支遗漏带来的线上隐患。268 收藏
本文用文件读取和目录扫描两个场景,演示 Java try-with-resources 如何自动关闭资源、控制关闭顺序,并避免 finally 分支遗漏带来的线上隐患。268 收藏 -
数据库 · MySQL | 4星期前 | 性能优化 · 执行计划 · MySQL教程 · 慢查询治理 · 数据库运维 · mysql GROUP BY优化 TempTable 内部临时表 Created_tmp_disk_tables
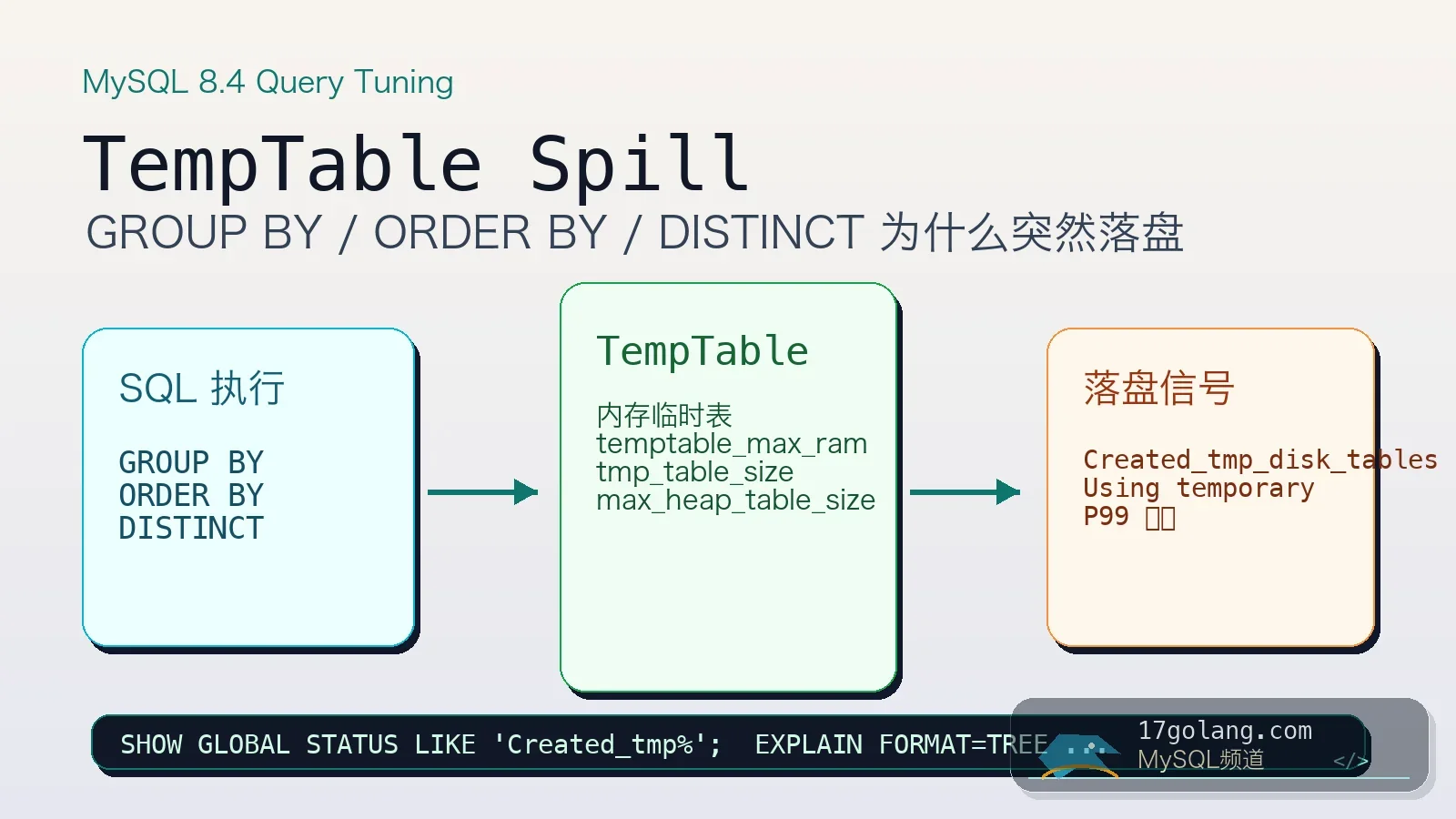 从 MySQL 8.4 内部临时表和 TempTable 入手,讲清 GROUP BY、ORDER BY、DISTINCT 落盘诊断、SQL 改写、索引策略和参数兜底。267 收藏
从 MySQL 8.4 内部临时表和 TempTable 入手,讲清 GROUP BY、ORDER BY、DISTINCT 落盘诊断、SQL 改写、索引策略和参数兜底。267 收藏 -
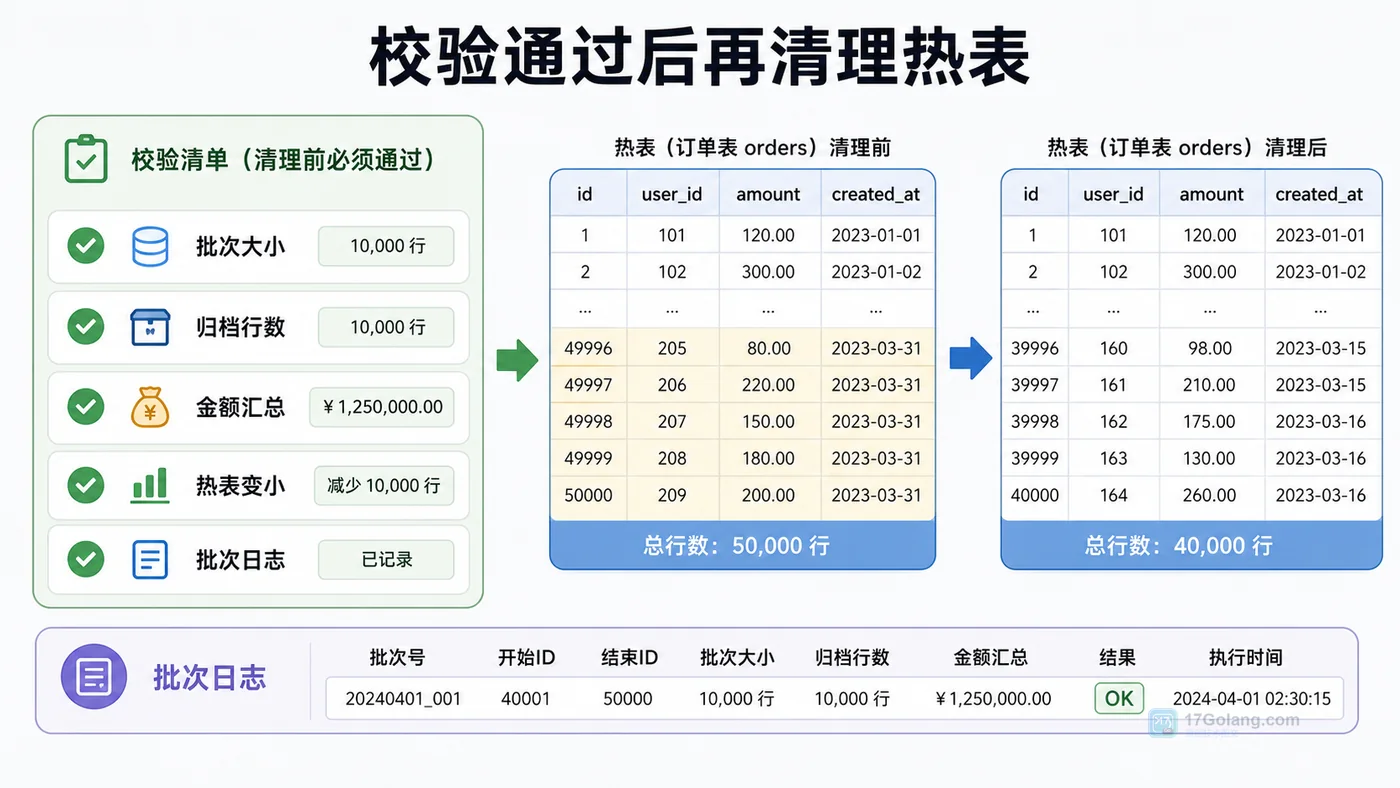 本文用订单表归档为例,讲清 MySQL 历史数据如何按时间窗口分批搬迁:先确定归档边界,再批量写入归档表,校验数量和金额,最后小批量清理热表,降低锁等待和慢查询风险。261 收藏
本文用订单表归档为例,讲清 MySQL 历史数据如何按时间窗口分批搬迁:先确定归档边界,再批量写入归档表,校验数量和金额,最后小批量清理热表,降低锁等待和慢查询风险。261 收藏 -
文章 · linux | 2星期前 | Linux · 运维 · 性能排查 · 磁盘IO · iostat · pidstat · Linux 性能排查 iostat 磁盘IO pidstat %util
 本文从 Linux 接口变慢和磁盘 IO 飙高的现场开始,使用 iostat 判断磁盘压力,再用 pidstat 定位写入进程,最后通过限速清理、迁移写入和复查指标恢复稳定。260 收藏
本文从 Linux 接口变慢和磁盘 IO 飙高的现场开始,使用 iostat 判断磁盘压力,再用 pidstat 定位写入进程,最后通过限速清理、迁移写入和复查指标恢复稳定。260 收藏 -
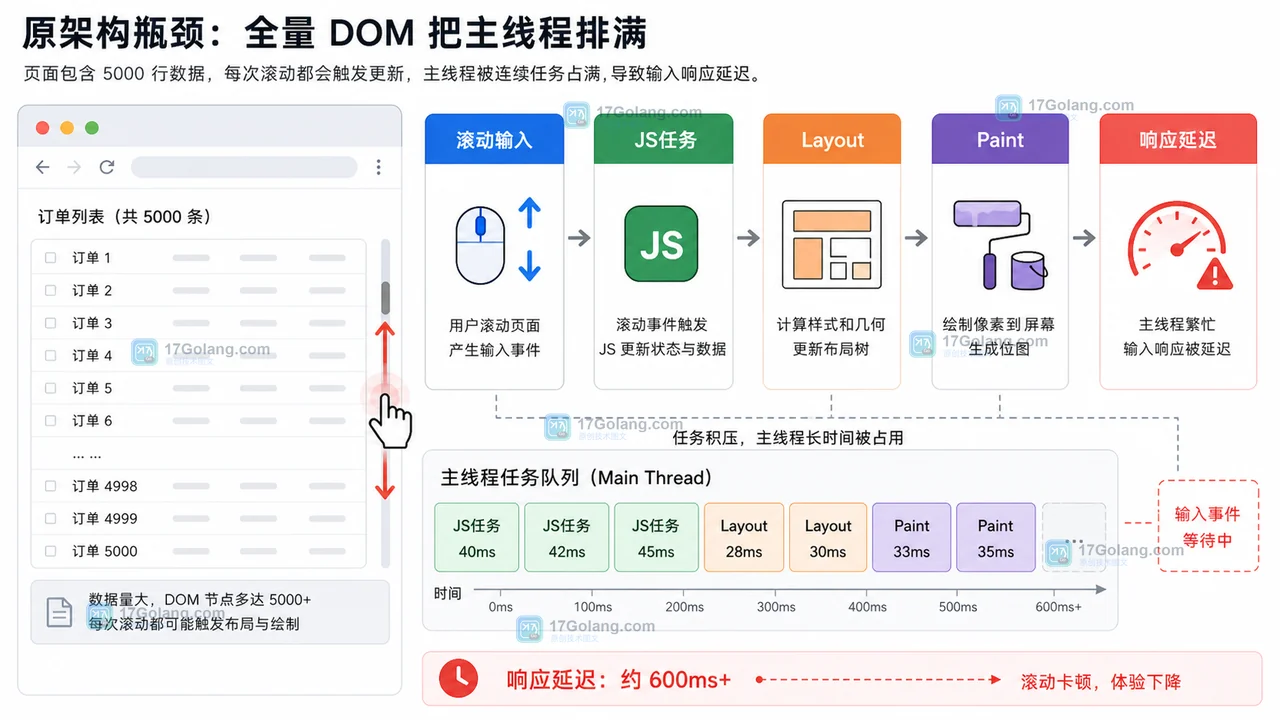 从长列表全量 DOM 的主线程等待链讲起,说明虚拟列表如何通过可见窗口、节点复用和占位高度降低 Layout/Paint 压力,并给出最小实现与上线检查。260 收藏
从长列表全量 DOM 的主线程等待链讲起,说明虚拟列表如何通过可见窗口、节点复用和占位高度降低 Layout/Paint 压力,并给出最小实现与上线检查。260 收藏 -
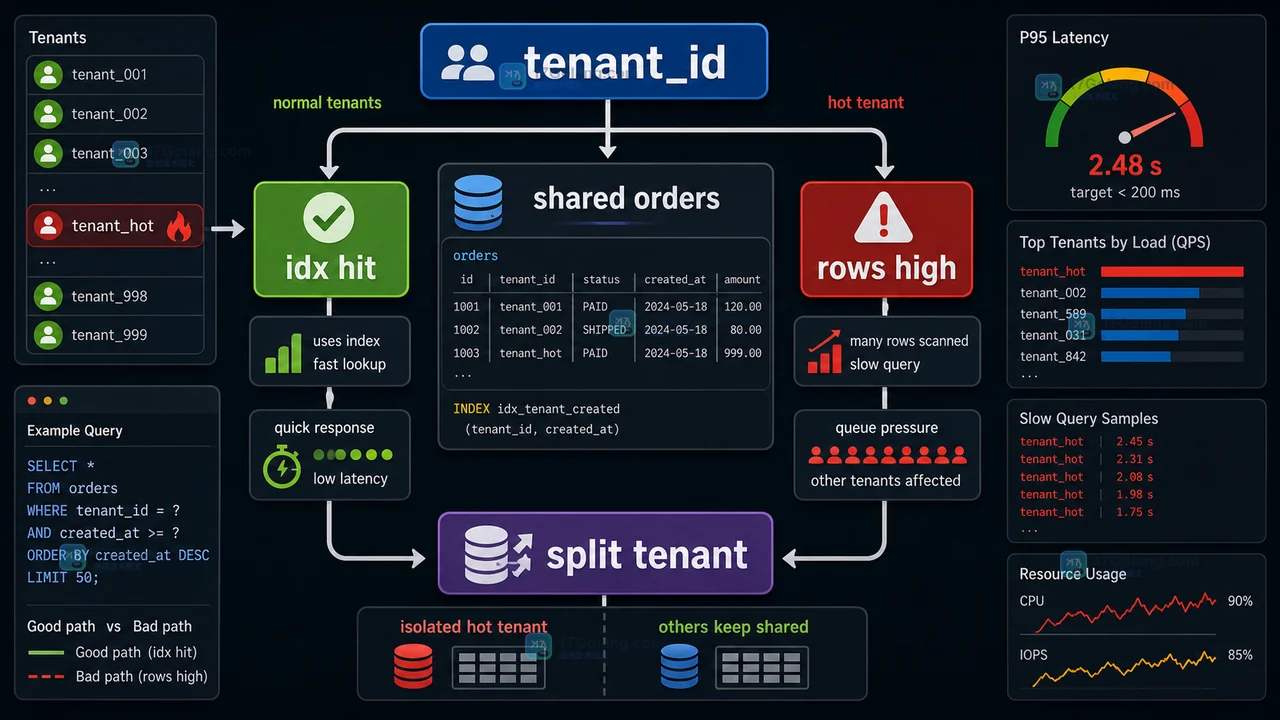 MySQL 多租户订单表变慢时,先用 tenant_id 领头的联合索引稳住常见查询;当热点租户持续拉高 rows、慢日志和队列等待,再考虑租户路由、冷热分流或独立分片。259 收藏
MySQL 多租户订单表变慢时,先用 tenant_id 领头的联合索引稳住常见查询;当热点租户持续拉高 rows、慢日志和队列等待,再考虑租户路由、冷热分流或独立分片。259 收藏 -
文章 · java教程 | 1星期前 | 性能优化 · Java教程 · CompletableFuture · 接口聚合 · java completablefuture orTimeout completeOnTimeout 接口性能 P95
 用指标驱动方式讲解 Java CompletableFuture 聚合接口优化:先建立串行调用基线,再改为并发请求、设置超时兜底,最后用 P95、错误率和慢依赖占比验证效果。255 收藏
用指标驱动方式讲解 Java CompletableFuture 聚合接口优化:先建立串行调用基线,再改为并发请求、设置超时兜底,最后用 P95、错误率和慢依赖占比验证效果。255 收藏