Go语言技术文章
-
 活动报名、接口去重、用户访问统计里经常会用 Redis Set。本文从“页面显示人数不对”的现场开始,逐步验证 SADD 返回值、SCARD 数量、Key 粒度和过期策略,整理一套更稳的 Set 去重写法。194 收藏
活动报名、接口去重、用户访问统计里经常会用 Redis Set。本文从“页面显示人数不对”的现场开始,逐步验证 SADD 返回值、SCARD 数量、Key 粒度和过期策略,整理一套更稳的 Set 去重写法。194 收藏 -
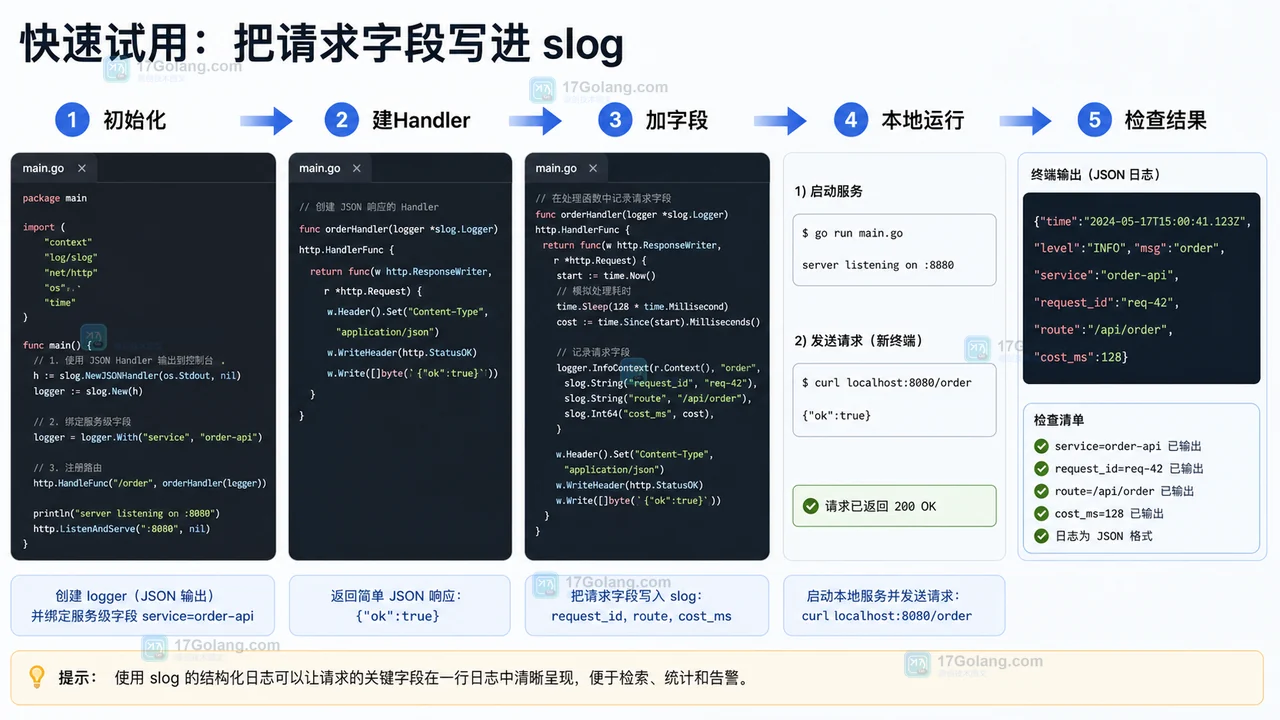 本文用一个 Go HTTP 接口示例,把 log/slog 的 JSONHandler、Logger.With、请求字段和本地检查串起来,说明如何把普通日志变成可检索、可过滤、可定位的结构化日志。194 收藏
本文用一个 Go HTTP 接口示例,把 log/slog 的 JSONHandler、Logger.With、请求字段和本地检查串起来,说明如何把普通日志变成可检索、可过滤、可定位的结构化日志。194 收藏 -
文章 · java教程 | 4星期前 | 并发编程 · Spring Boot · 生产实践 · Java教程 · 线程池隔离 · java 并发编程 线程池 spring boot completablefuture
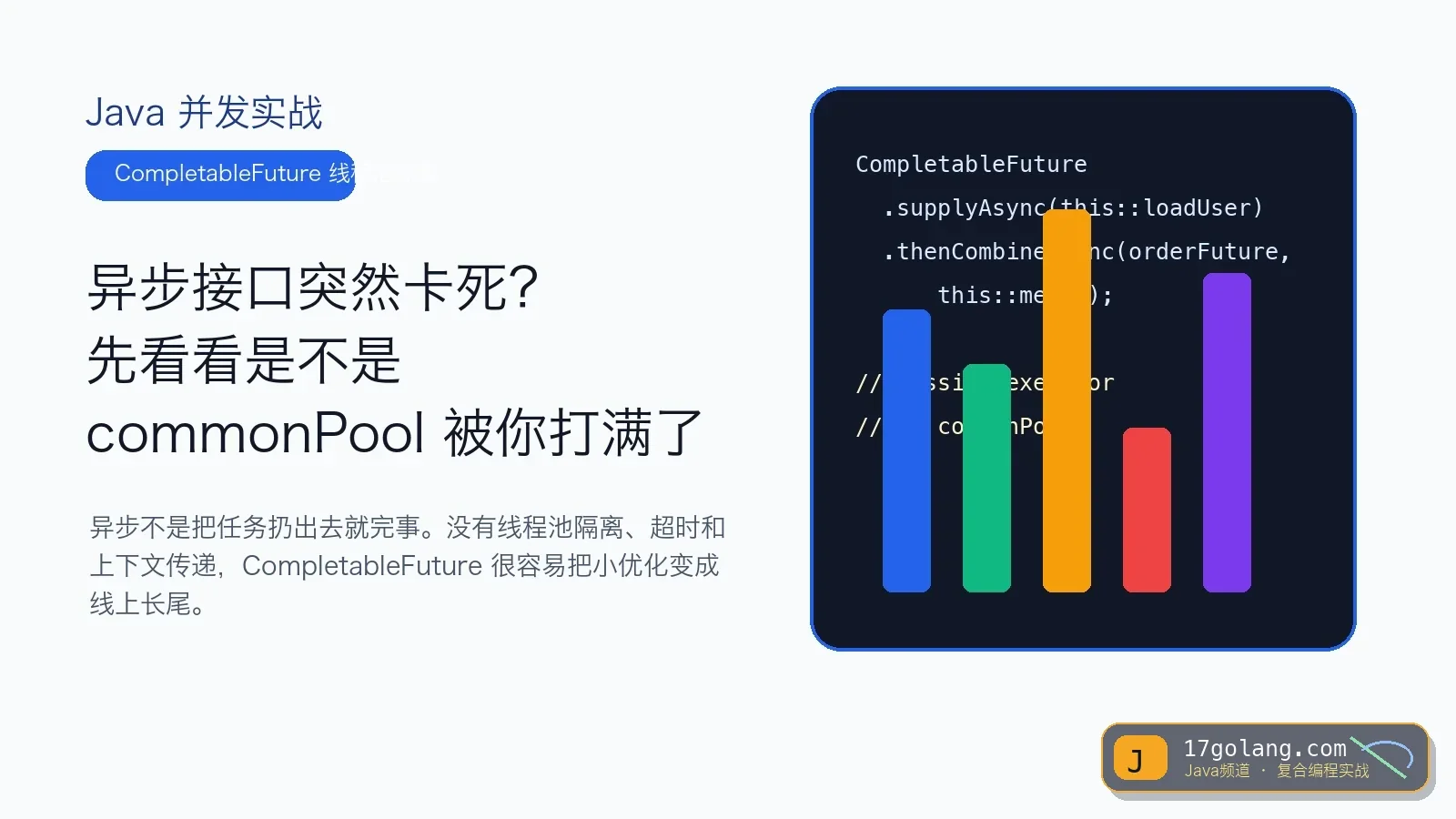 从 Spring Boot 异步接口长尾事故讲清 CompletableFuture 显式 Executor、线程池隔离、超时、异常收口和上下文传递。191 收藏
从 Spring Boot 异步接口长尾事故讲清 CompletableFuture 显式 Executor、线程池隔离、超时、异常收口和上下文传递。191 收藏 -
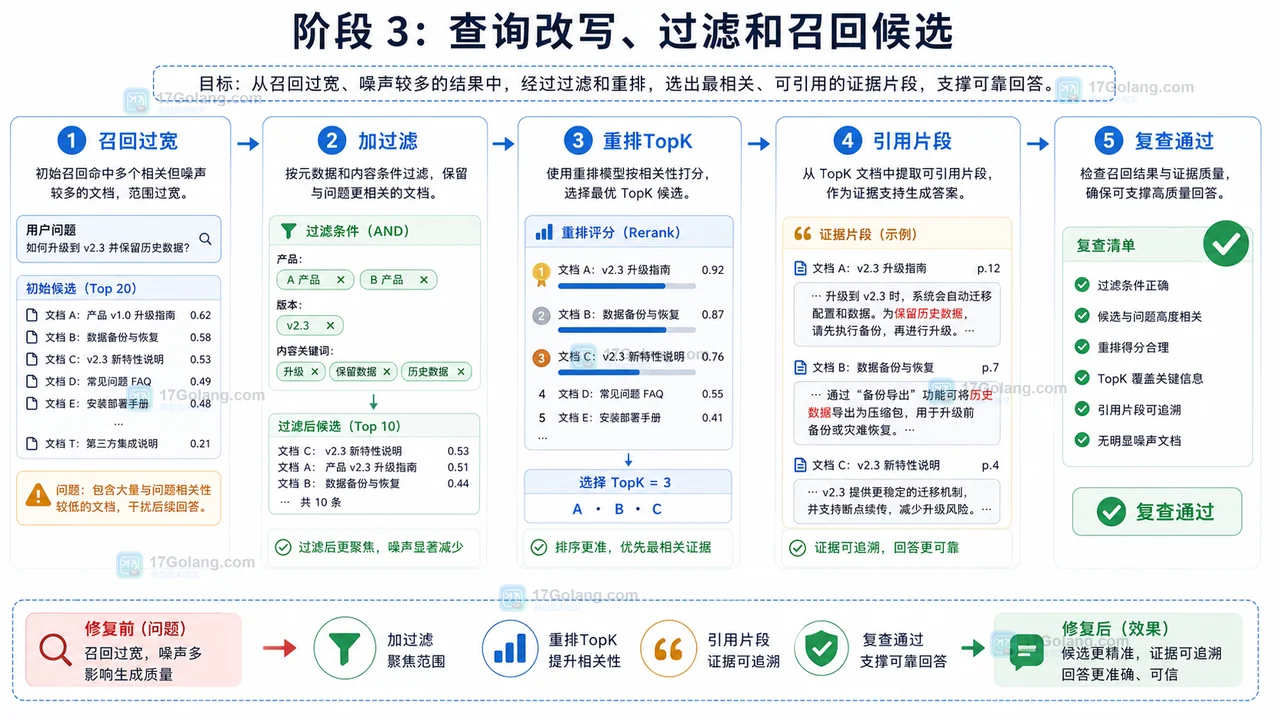 本文整理一套 AI 知识库检索召回工作流,从文档清洗、切分、向量入库、查询改写、过滤重排到证据引用和复查指标,帮助知识库回答从能用走向可控。191 收藏
本文整理一套 AI 知识库检索召回工作流,从文档清洗、切分、向量入库、查询改写、过滤重排到证据引用和复查指标,帮助知识库回答从能用走向可控。191 收藏 -
 从 MySQL 8.4 Skip Scan 入手,讲清复合索引没有左前缀条件时优化器为什么仍可能走索引,以及如何用 EXPLAIN ANALYZE 和 optimizer_switch 做生产验证。189 收藏
从 MySQL 8.4 Skip Scan 入手,讲清复合索引没有左前缀条件时优化器为什么仍可能走索引,以及如何用 EXPLAIN ANALYZE 和 optimizer_switch 做生产验证。189 收藏 -
文章 · python教程 | 3星期前 | 日志 · 工程化 · 异步编程 · 故障排查 · 可观测性 · Python教程 · Python 异步任务 可观测性 logging contextvars 生产实践 QueueHandler QueueListener request_id JSON日志
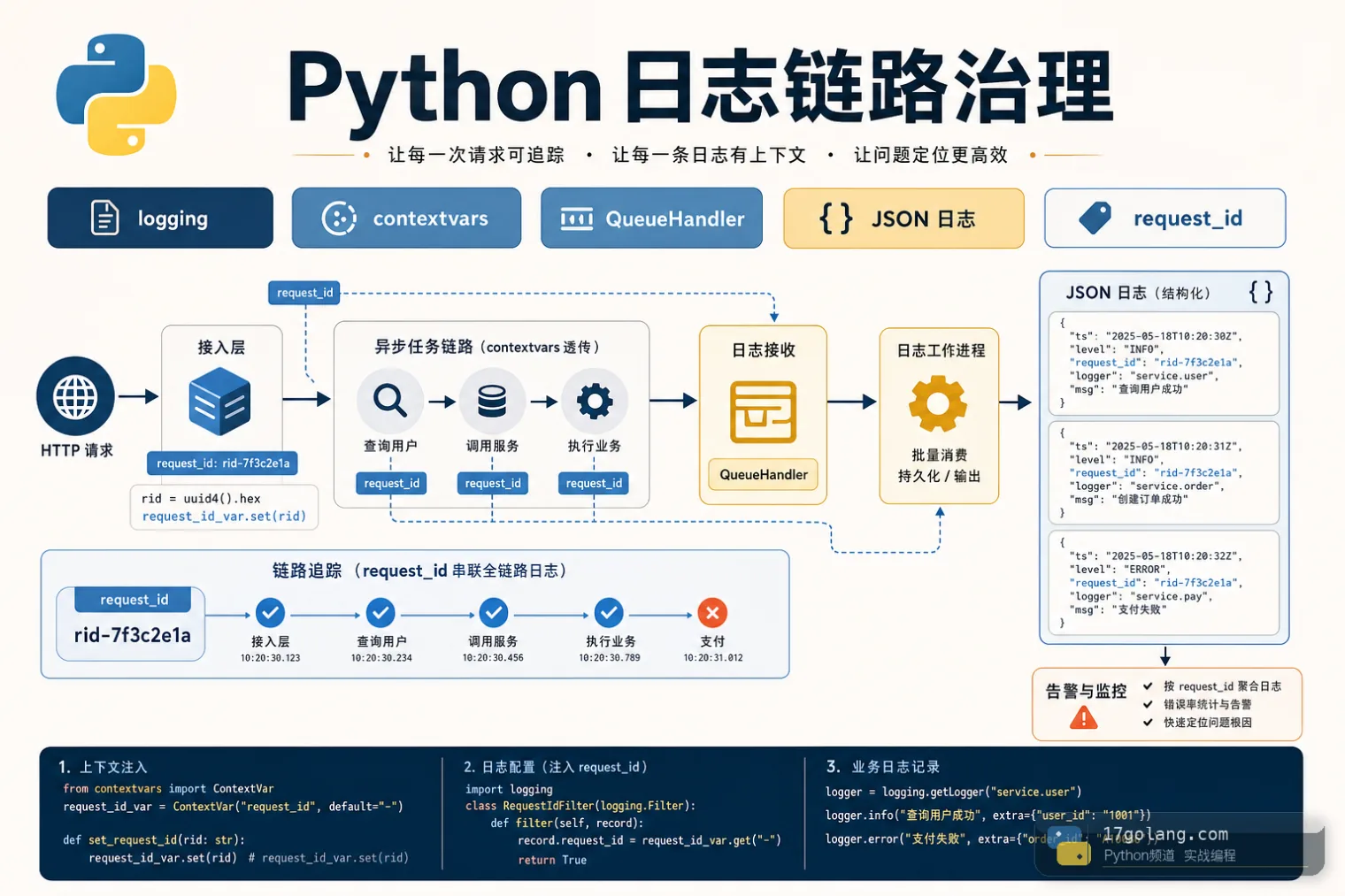 从 Python 服务 request_id 丢失和日志阻塞问题入手,实战讲解 contextvars、logging.Filter、JSON 日志、QueueHandler/QueueListener 与上线检查。189 收藏
从 Python 服务 request_id 丢失和日志阻塞问题入手,实战讲解 contextvars、logging.Filter、JSON 日志、QueueHandler/QueueListener 与上线检查。189 收藏 -
数据库 · Redis | 2星期前 | Redis · 消息队列 · Stream · 消费组 · redis 消息队列 Redis Stream 消费组 XREADGROUP XACK XPENDING XAUTOCLAIM
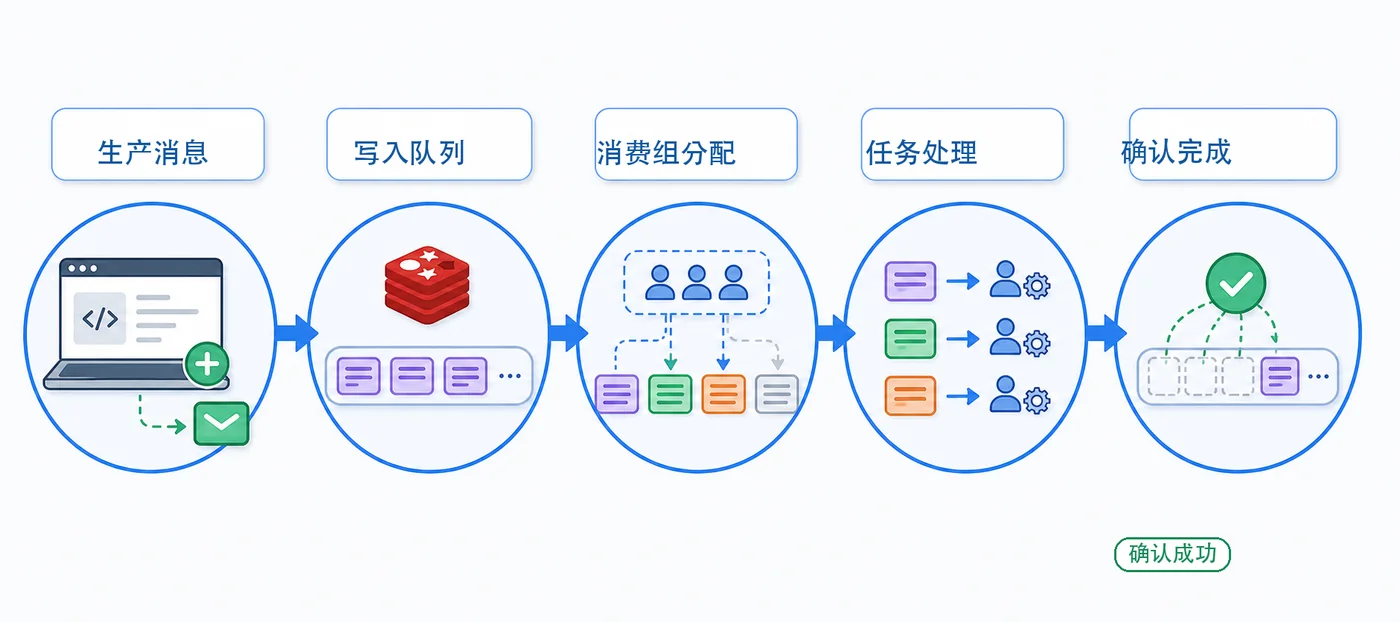 用订单异步处理场景讲清楚 Redis Stream 的实用队列模型:生产者写入消息,消费组分配任务,Worker 处理成功后 ACK,失败或超时的消息进入待确认列表,再通过 XPENDING 和 XAUTOCLAIM 做重投。187 收藏
用订单异步处理场景讲清楚 Redis Stream 的实用队列模型:生产者写入消息,消费组分配任务,Worker 处理成功后 ACK,失败或超时的消息进入待确认列表,再通过 XPENDING 和 XAUTOCLAIM 做重投。187 收藏 -
Golang · Go教程 | 4星期前 | 并发编程 · CI · Go教程 · Go1.25 · 代码质量 · golang Go WaitGroup Go1.25 go vet HostPort
 围绕 Go 1.25 新增的 go vet waitgroup 和 hostport 检查,讲清 WaitGroup.Add 位置、IPv6 地址拼接、CI 门禁、误报处理和团队落地规范。185 收藏
围绕 Go 1.25 新增的 go vet waitgroup 和 hostport 检查,讲清 WaitGroup.Add 位置、IPv6 地址拼接、CI 门禁、误报处理和团队落地规范。185 收藏 -
文章 · 前端 | 2星期前 | 前端 · 性能优化 · javascript · 图片优化 · IntersectionObserver · 前端 性能优化 图片懒加载 IntersectionObserver Web性能 首屏优化
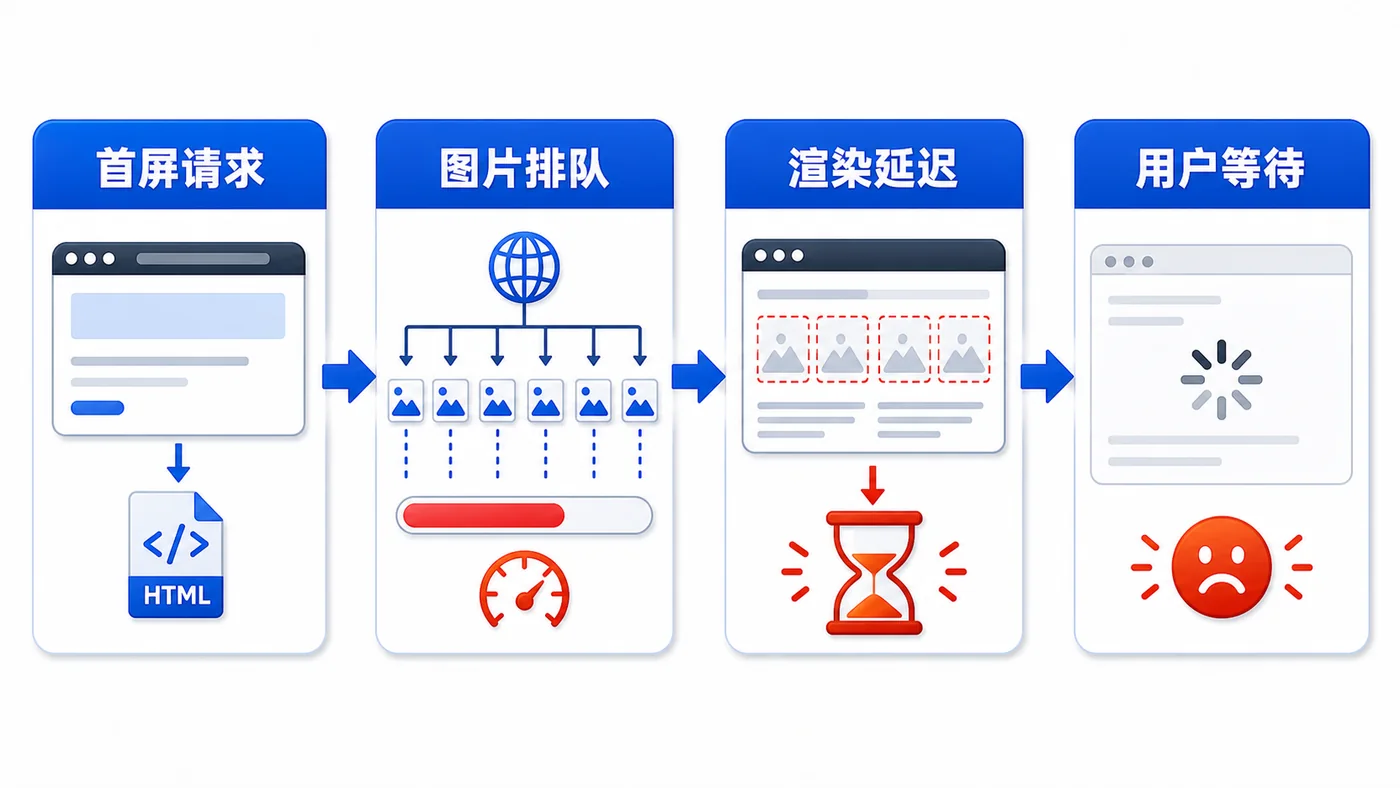 本文用商品列表图片场景,演示图片为什么会拖慢首屏,并用 IntersectionObserver 实现占位、进入视口、替换地址和加载完成的懒加载流程。184 收藏
本文用商品列表图片场景,演示图片为什么会拖慢首屏,并用 IntersectionObserver 实现占位、进入视口、替换地址和加载完成的懒加载流程。184 收藏 -
Golang · Go教程 | 4星期前 | web安全 · Go教程 · 后端工程 · Golang实战 · net/http · CSRF · golang 安全 Go net/http HTTP服务 csrf Go1.25 CrossOriginProtection
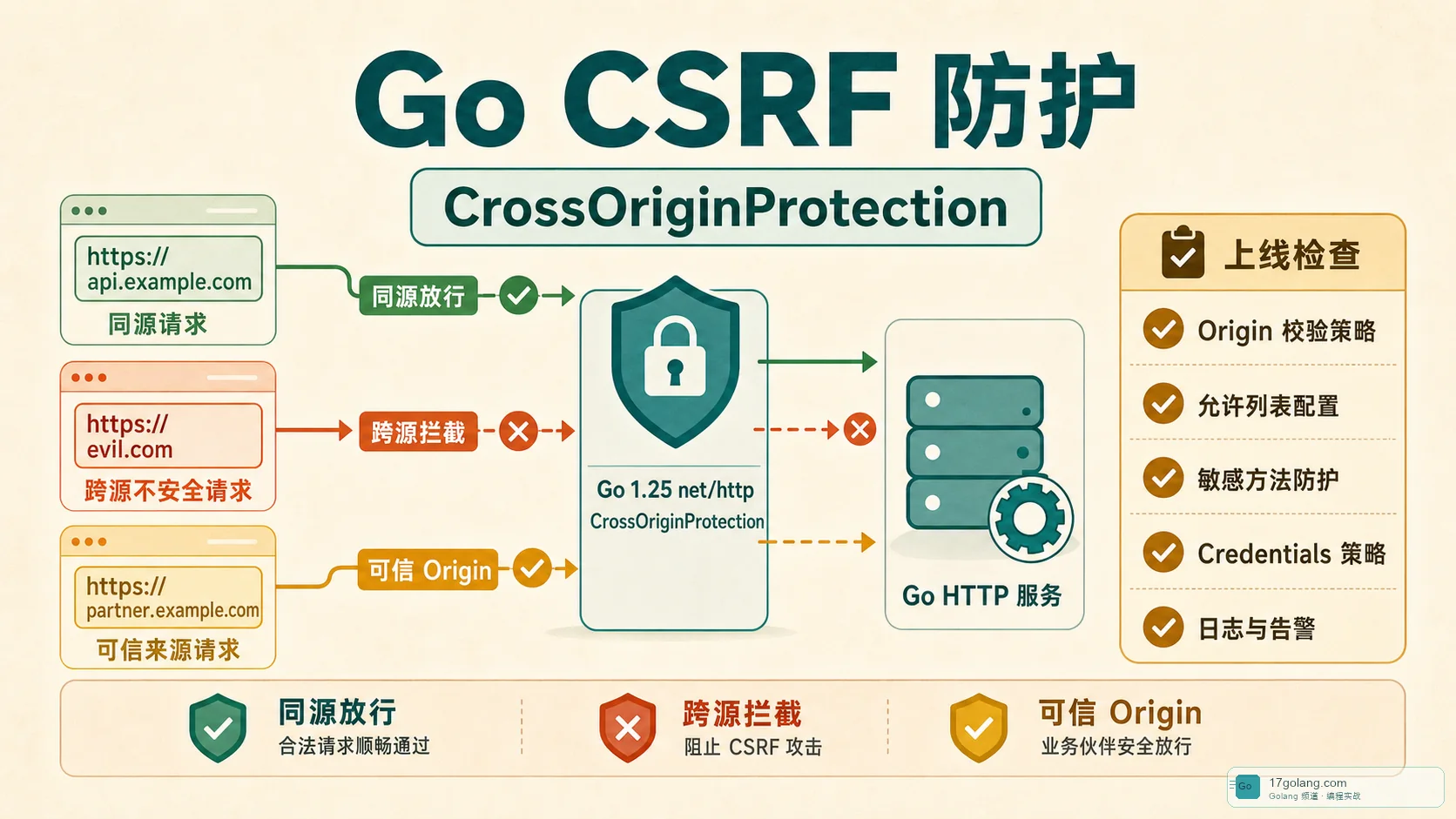 从后台接口 CSRF 风险出发,讲清 Go 1.25 net/http CrossOriginProtection 的判断逻辑、可信 Origin、拒绝日志、绕过白名单风险、预发测试和上线检查。183 收藏
从后台接口 CSRF 风险出发,讲清 Go 1.25 net/http CrossOriginProtection 的判断逻辑、可信 Origin、拒绝日志、绕过白名单风险、预发测试和上线检查。183 收藏 -
 通过有界 channel、select 和 context,把压力显式传回生产端。183 收藏
通过有界 channel、select 和 context,把压力显式传回生产端。183 收藏 -
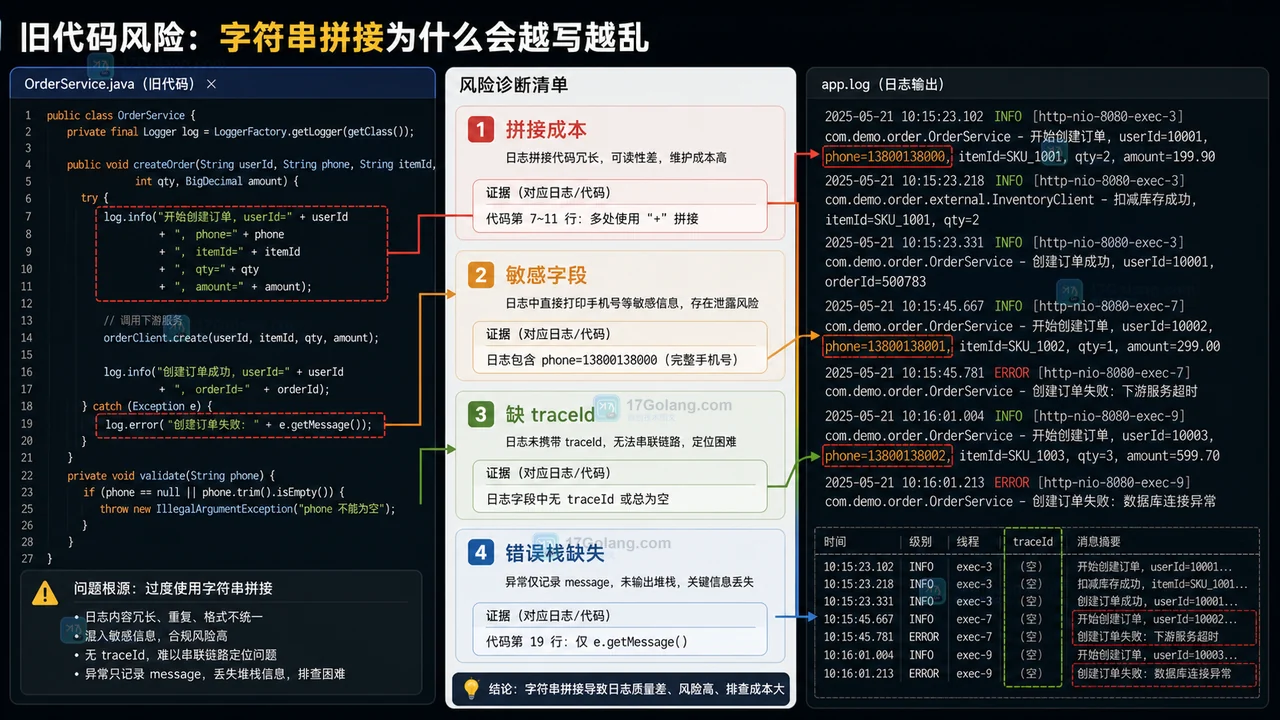 围绕 Java 老项目日志迁移,说明如何从字符串拼接改成 SLF4J 参数化日志,并补上 MDC traceId、脱敏规则和回归检查,让日志更可查也更稳。182 收藏
围绕 Java 老项目日志迁移,说明如何从字符串拼接改成 SLF4J 参数化日志,并补上 MDC traceId、脱敏规则和回归检查,让日志更可查也更稳。182 收藏 -
 理解 Allow、Wait、Reserve 和 Burst 的区别,给接口加上可解释的限流策略。181 收藏
理解 Allow、Wait、Reserve 和 Burst 的区别,给接口加上可解释的限流策略。181 收藏 -
数据库 · Redis | 2天前 | Redis · 缓存治理 · Keyspace Notifications · 过期事件 · redis Pub/Sub Keyspace Notifications 过期事件 缓存监听 补偿任务
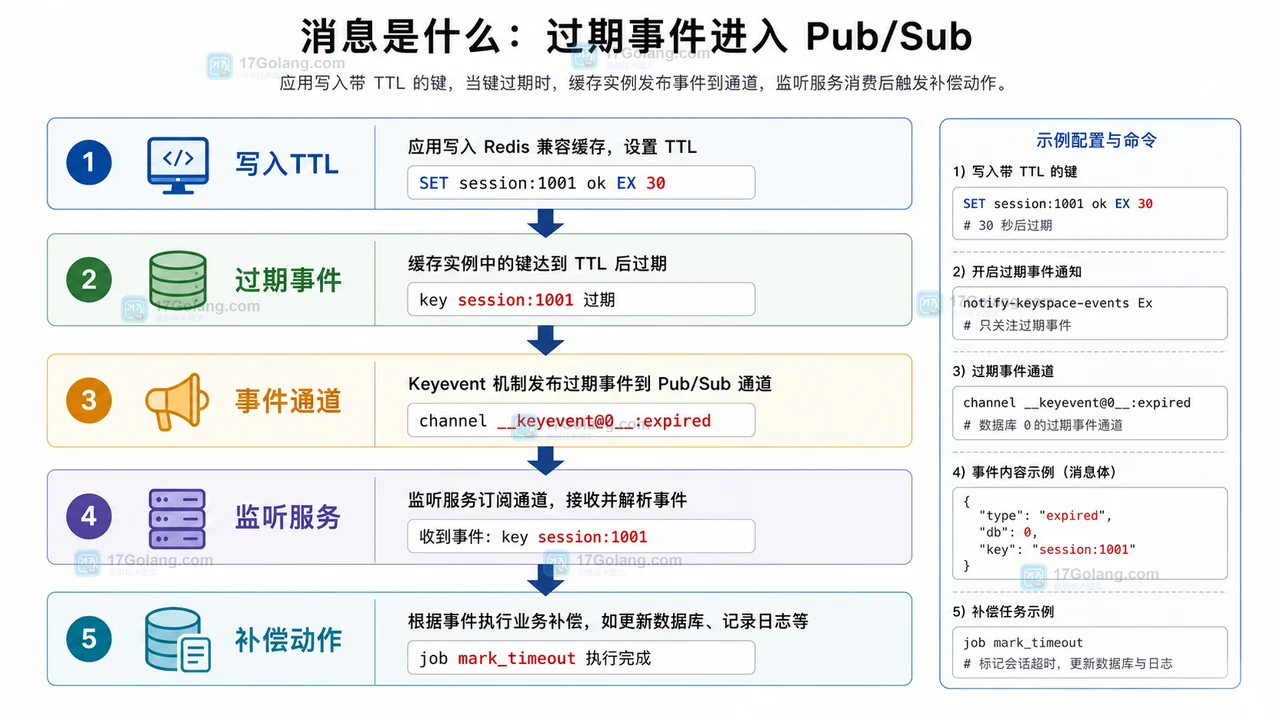 本文用 Redis Keyspace Notifications 演示如何监听过期 Key,配置 notify-keyspace-events,接收 __keyevent@0__:expired 事件,并说明事件通知的丢失风险与补扫兜底做法。181 收藏
本文用 Redis Keyspace Notifications 演示如何监听过期 Key,配置 notify-keyspace-events,接收 __keyevent@0__:expired 事件,并说明事件通知的丢失风险与补扫兜底做法。181 收藏 -
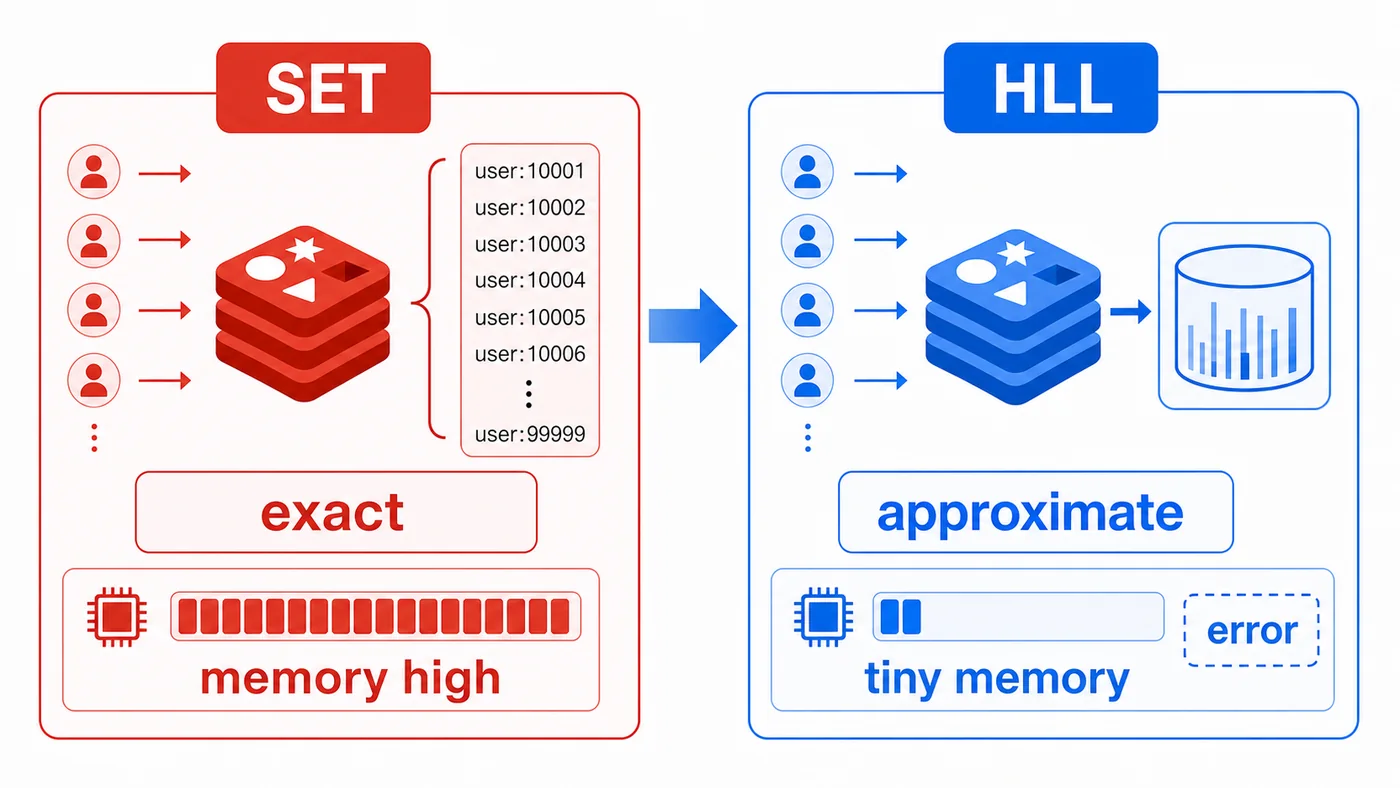 用 Redis HyperLogLog 做站点 UV 统计:通过 PFADD 写入用户标识,用 PFCOUNT 读取近似去重人数,对比 Set 精确去重的内存成本,并说明适用场景和误差边界。180 收藏
用 Redis HyperLogLog 做站点 UV 统计:通过 PFADD 写入用户标识,用 PFCOUNT 读取近似去重人数,对比 Set 精确去重的内存成本,并说明适用场景和误差边界。180 收藏