-

若灵珠AI合同处理结果不准确,需依次启用条款审阅模块并设定审查立场与交易背景、激活规范审阅校验文本结构、限定时效与地域约束调用文书生成器、执行敏感信息脱敏、切换本地化部署交叉验证。
-

通过CSS的background-image等属性可灵活设置网页背景图片。首先使用background-image指定图片路径,如body{background-image:url('bg.jpg');};默认图片会平铺,可通过background-repeat控制,取值包括repeat(默认)、no-repeat(不重复)、repeat-x(横向重复)和repeat-y(纵向重复),例如添加background-repeat:no-repeat防止重复;利用background-position调整图片
-

tofai实现镜像翻转有五种方法:一、图形界面通过【编辑→变换】菜单或快捷键;二、命令行使用--flip参数;三、Python脚本调用ta.flip()API;四、网页预览中用CSStransform临时显示翻转;五、启用EXIF方向自动校正。
-

Python网络程序高可用需从连接、重试、超时、熔断、监控五层面系统设计:连接管理用Session复用与分段超时;重试仅针对临时错误并指数退避;超时独立设置,配合熔断降级;监控覆盖指标、日志、链路与告警自愈。
-

file-i比扩展名靠谱,因其基于文件魔数和结构特征而非后缀识别类型;即使重命名(如ELF改为.txt),仍准确返回application/x-executable;它读取/usr/share/file/magic规则库,支持-z解压识别、-k深度检测,但遇自定义二进制格式需手动查十六进制头。
-

sync.Once.Do传入函数panic后永远失效,因done字段被原子置1且不可逆,不捕获panic也不重试;须在闭包内defer/recover或改用error返回路径,并避免闭包捕获外部可变变量。
-

QUEUE_CONNECTION改了仍同步执行,根本原因是配置未刷新:必须运行phpartisanconfig:clear(开发)或config:cache(生产),否则Laravel读取缓存旧配置,默认sync;验证用tinker执行config('queue.default')应返回redis等非sync值。
-

安装brotli库即可解决:执行pipinstallbrotli,Requests会自动通过urllib3注册br解码器,无需改代码;若仍报错,需检查环境一致性、urllib3版本是否≥1.26或是否存在自定义适配器干扰解码流程。
-

不推荐在Django中直接使用APScheduler,因其为单进程内存调度器,多worker下会重复执行、热重载时任务注册冲突、无持久化导致重启丢失、无法适配Django生命周期;推荐轻量用django-crontab(复用系统crond),动态管理则选django-celery-beat。
-

Nginx代理WebSocket升级失败的主因是Upgrade和Connection头未正确配置,而非证书问题;必须设置proxy_http_version1.1、proxy_set_headerUpgrade$http_upgrade、proxy_set_headerConnection"upgrade",并确保路径、域名、协议严格匹配。
-

Packagist不支持直接筛选PHP7.4兼容包,需通过包页面的require.php字段确认(如"^7.2||^8.0"含7.4即兼容),或用composershowvendor/package查看各版本具体约束;搜索时可加php74等关键词初筛,但必须结合Packagist页面或show命令二次验证,避免依赖声明与实际语法/子依赖不一致。
-

必须用构图锚定+动作绑定双保险强制校准:先拍镜框清晰、人物正对镜面整理动作的真实参考图作为空间对称轴标定依据,再在可灵AI图生视频中开启镜像同步渲染并写明光学反射提示词,最后在剪映中手动蒙版镜面区域、水平翻转并精准校准中线与帧匹配。
-

推荐五种AI绘画工具本地部署方案:一、秋叶整合包(Windows一键部署);二、Docker版Z-ImageTurbo(跨平台GPU加速);三、Conda手动配置WebUI(高自由度开发);四、Neeshck-Z-Image_LYX_v2零代码Docker;五、麦橘超然Flux(Python原生+float8量化适配中端显卡)。
-

围绕 Go 1.24 正式支持的泛型类型别名,讲清 type Alias[T] = ... 的语义、约束写法、API 迁移、兼容测试和公共库使用边界。
-
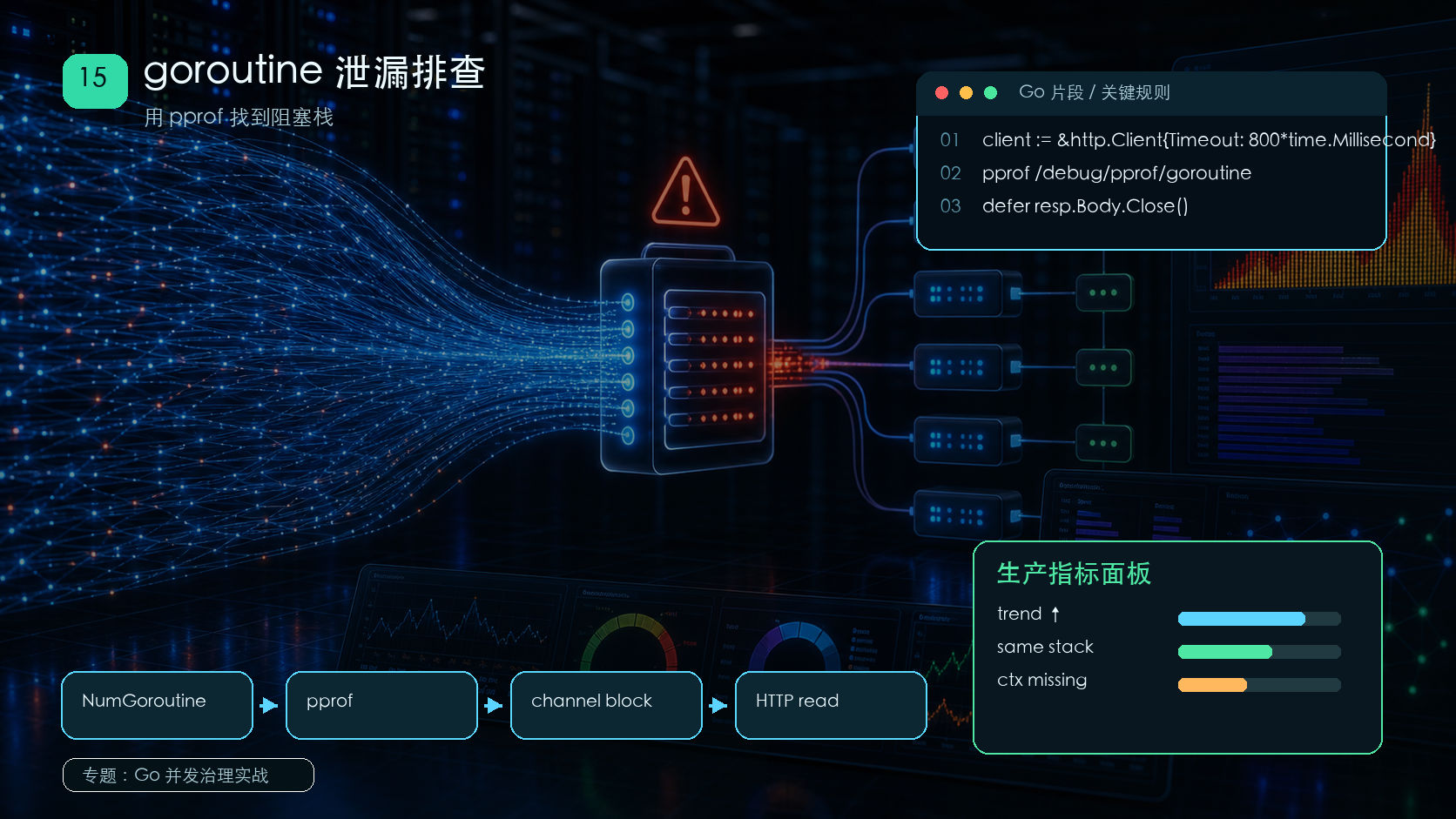
通过 goroutine profile、阻塞栈和请求路径定位泄漏来源。