-
 这是防止中文字符乱码的基础。2. 避免直接在 JS 中写中文选择器尽量不要在 JavaScript">
这是防止中文字符乱码的基础。2. 避免直接在 JS 中写中文选择器尽量不要在 JavaScript">
querySelector不支持中文作为CSS选择器值,必须使用标准语言标签(如zh、en);data-lang应为运行时标识,友好名称需用独立属性(如data-lang-label)承载,并确保HTML声明UTF-8编码。
-

驾考精灵官网在线入口是https://www.jiakaoyingling.com,提供2026年最新科目一、四题库,含视频解析、智能学习路径、多端同步及实用辅助工具。
-

表格错位、边框消失、对齐异常的根源在于默认样式干扰和嵌套结构错误;必须用<tr>包裹<td>/<th>,禁止单独嵌套,且需用CSS设置border和border-collapse:collapse,并区分<th>(居中加粗)与<td>(左对齐)的语义及样式。
-

通过高强度间歇训练、肱三头肌专项练习、自重训练、日常微运动及充足蛋白质摄入,可有效紧致手臂线条。首先进行波比跳结合哑铃推举,每周3-4次,每次4组,提升代谢并燃烧手臂脂肪;接着做俯身臂屈伸强化肱三头肌,改善“蝴蝶袖”,每组12-15次,完成3组;配合墙壁俯卧撑等自重训练增强上肢力量,逐步进阶至标准动作;日常中加入平举画圈和手指拉伸,促进循环、缓解僵硬;同时每日按体重摄入1.2-1.5克/公斤蛋白质,优选鸡胸肉、鱼、蛋清等,尤其在训练后30分钟内补充,以支持肌肉修复与紧实塑形。
-

EventTimingAPI是唯一能准确获取FID的原生机制,因其提供startTime与processingStart字段,差值即为标准FID;而performance.getEntriesByName('first-input')仅返回事件处理耗时(duration),不包含主线程排队延迟,故无法替代。
-

局部变量表中数组变量仅占1个Slot存储引用,实际元素存于堆;Slot可复用以降低栈压力,但编译期已固定总大小,作用域控制比分支位置更影响空间效率。
-
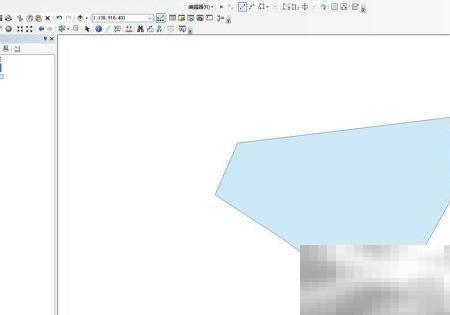
ARCGIS数据导出方法详解1、先安装软件,完成后启动并加载所需数据。2、如图所示,点击箭头所指位置并右键单击。3、在弹出菜单中点击“导出”选项,如下图所示。4、进入“导出数据”对话框,界面如图所示。5、导出过程中需指定空间参考(坐标系),不同坐标系将影响输出数据的空间位置与精度。6、当前数据库中软件识别并显示的坐标系信息,可在此处核对或修改。7、支持多种导出格式,满足不同应用场景需求。8、提供XML、ZIP和Z三种文件类
-

番茄音乐最火入口是官网https://music.360.cn/,首页流式卡片推荐、顶部四模块导航、底部双滑轨播放器及全链路微动效构成核心交互体验。
-

可通过四种方式将GitHub项目保存到本地:一、用gitclone命令完整克隆含历史记录的仓库;二、直接下载ZIP包获取默认分支最新代码;三、使用GitHubDesktop图形化工具可视化操作;四、通过GitHubCLI工具命令行拉取并自动配置远程源。
-

Workerman仅负责连接与协议处理,支撑Discord级万人多频道需自建分层架构:接入层(多Worker进程)、路由层(中心化ChannelManager+Redis同步映射)、存储层(Redis集群+MySQL),禁用全局连接遍历与进程内状态存储。
-
里番漫画网页版免登录入口为https://www.libanmanhua.com,该平台资源丰富,涵盖多种题材,更新及时,分类清晰,支持高清流畅阅读;界面简洁,适配多设备,操作便捷,具备智能推荐和自定义阅读模式;无需登录即可访问,加载迅速,广告少,用户体验良好。
-

直接选择Python3.10及以上版本最合适,因其性能更强、语法更现代、错误提示更清晰;Python2已停止维护,资源不兼容且存在安全隐患;推荐安装python.org提供的最新稳定版如Python3.12,并通过python--version验证版本。
-

strip()仅删除字符串首尾属于指定字符集的字符,不按子串匹配;removeprefix/removesuffix则精确删除固定前缀或后缀,Python3.9+引入,语义明确、安全可靠。
-

本文讲解如何在PHP中将三个一维数组(如字母、数字、状态)进行全量组合,生成笛卡尔积式的数据结构,并通过预处理语句高效批量插入MySQL数据库。本文讲解如何在PHP中将三个一维数组(如字母、数字、状态)进行全量组合,生成笛卡尔积式的数据结构,并通过预处理语句高效批量插入MySQL数据库。在实际开发中,常需将多个维度的取值进行全量配对后写入数据库——例如为每个产品型号($array1)绑定所有可用规格($array2)和对应库存状态($arr
-

宝塔旧版本(如7.x、8.x)无法通过界面更新,需用命令行强刷;v9.0.0不可直升v11.4,须重装迁移。执行前务必备份,升级后需手动修复插件、调整计划任务PHP路径及检查防火墙规则。