-

MySQL是一种常用的数据库管理系统,由于其高效率、高性能和高可靠性,在Web应用程序中得到了广泛的应用。在MySQL中,数据存储结构是一种非常重要的概念,它有助于我们理解数据库存储的方式,使我们能够更好地优化数据库性能。本文将介绍MySQL中的数据存储结构分析方法。InnoDB存储引擎InnoDB是MySQL中最常用的存储引擎,它以数据的行为单位进行存储,
-

随着互联网和物联网的快速发展,数据已成为对企业最为重要的资产之一。数据透析处理是企业将数据转化为实际洞见和决策的过程,因此对于企业来说是至关重要的。在这个过程中,数据库是数据存储和管理的核心,而程序语言则是实现透析处理的重要工具。这篇文章将介绍MySQL数据库与Go语言结合使用的方法,实现数据透析处理。MySQL数据库是一款性能稳定、安全易用的开源数据库,在
-

随着数据量的不断增加,数据库的性能成为了一个越来越重要的问题。数据冷热分离处理是一种有效的解决方案,它可以将热点数据和冷数据进行分离,从而提高系统的性能和效率。本文将介绍如何使用Go语言和MySQL数据库进行数据冷热分离处理。一、什么是数据冷热分离处理数据冷热分离处理是一种将热点数据和冷数据进行分类处理的方式。热点数据是指访问频率高、对性能要求高的数据,冷数
-

如何处理MySQL连接异常终止时的数据一致性和保护机制?摘要:MySQL是一款常用的关系型数据库管理系统,但在使用过程中,可能会遇到连接异常终止的情况,这会导致数据的一致性和安全性受到威胁。本文将介绍如何处理MySQL连接异常终止时的数据一致性和保护机制,以提高系统的可靠性和稳定性。关键词:MySQL、连接异常、数据一致性、保护机制一、异常终止的原因及危害
-

如何使用Redis和Ruby开发缓存更新任务简介:在现代Web应用中,缓存是提高性能和减少响应时间的重要组成部分。Redis是一个高性能的键值数据库,可以用于快速读取和写入数据,并且它支持多种数据结构,如字符串、哈希表、列表等。在本文中,我们将探讨如何使用Redis和Ruby开发缓存更新任务,以实现更高效的缓存管理和更新。步骤1:安装和配置Redis首先,我
-

Redis和Perl语言开发:构建可扩展的网络应用引言:随着互联网的发展,网络应用的需求越来越复杂,同时对性能要求也越来越高。为了满足这种需求,开发人员需要选择一种高效可扩展的方式来构建他们的应用程序。本文将介绍如何使用Redis和Perl语言开发,并展示如何通过Redis的各种特性来构建可扩展的网络应用。一、Redis简介:Redis是一个开源的内存数据结
-

让我们首先看看MySQL中IFNOTIN的语法-if(yourVariableName NOTIN(yourValue1,yourValue2,........N))then statement1else statement2endif 让我们实现上述语法以使用IFNOTIN-mysql>DELIMITER//mysql>CREATEPROCEDUREIF_NOT_INDemo(INvalueint) &nb
-

在这种情况下,MySQL将考虑复合INTERVAL单元中给出的最右边的单元。它将根据所附单位值集中提供的单个值计算间隔后返回输出。下面的例子将阐明它-mysql>SelectTIMESTAMP('2017-10-2204:05:36'+INTERVAL'2'year_month)AS'OnlyMonthValueChanged';+--------------------------+|OnlyMonthValueChanged|+----------
-

您可以锁定一条记录、一组记录、数据库表、表空间等,并且当我们这样做时,我们无法更改锁定的值。以下是JDBC中的锁定类型:行锁和键锁:它们用于锁定特定行。使用这些锁,您可以实现并发。页面锁:这些用于锁定页面。如果应用此功能,每当行的内容发生更改时,数据库都会锁定保存该行的整个页。如果您需要一次更新/更改大量行,您可以使用此锁。表锁:您可以使用这些锁定表锁有两种表锁。共享和独占。数据库锁定:这会锁定整个数据库。您可以使用此锁来阻止其他数据库的事务访问当前数据库。
-

如何解决MySQL报错:未知命令,需要具体代码示例MySQL是一种常用的开源数据库管理系统,被广泛用于网站开发和数据存储。在使用MySQL过程中,有时候会遇到报错信息,其中之一就是"未知命令"(Unknowncommand)。本文将介绍如何解决这种报错,并通过具体的代码示例加以说明。首先,我们需要明确问题的来源和具体原因。当使用MySQL客户端或命令行工具
-

建立MySQL中买菜系统的优惠券表优惠券是现代购物的重要促销手段之一。在买菜系统中,为了提供更好的用户体验和促销效果,我们需要通过建立优惠券表来管理和使用优惠券。本文将详细介绍如何在MySQL数据库中创建一个优惠券表,并给出具体的代码示例。一、确定表结构在建立优惠券表之前,我们首先需要确定表的结构和字段。根据需求,一个典型的优惠券表可能包含以下字段:id:优
-

Oracle导入数据时遇到中文乱码是一个常见的问题,主要是因为数据库的字符集与数据文件的字符集不一致所致。解决这个问题需要确保数据库字符集和数据文件字符集保持一致,并进行正确的转码操作。下面将结合具体的代码示例,介绍如何在Oracle数据库中导入数据时处理中文乱码问题。检查数据库字符集首先需要确认数据库的字符集,在Oracle中可以通过以下SQL语句查询数据
-
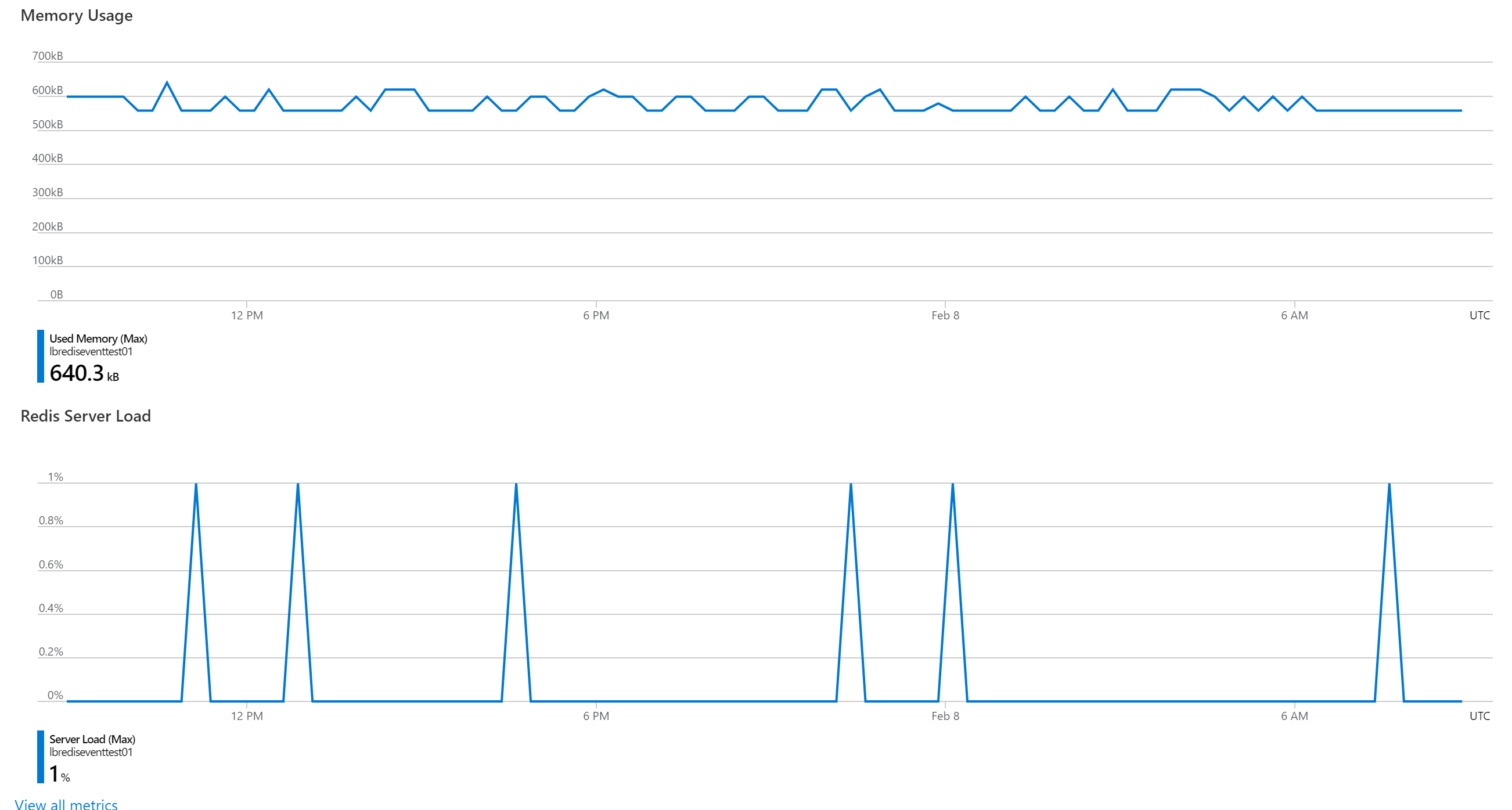
问题描述通过Metrics监控页面,我们能得知当前资源(如Redis)的运行情况与各种指标。如果我们需要把指标下载到本地或者生成JSON数据导入到第三方的监控平台呢?Azure是否可以通过Python代码或者时Powershell脚本导出各种指标数据呢?解决办法可以!PowerShell命令可以使用Get-AzMetric或者是azmonitormetricslist命令来获取资源的Metrics值。Get-AzMetric:Getsthemetricvaluesofaresource.https://d
-

在IntelliJIDEA的Mybatis测试类中使用接口方法的障碍在Mybatis...
-

数据库语法难题:聚合函数与排序执行顺序在SQL...