-
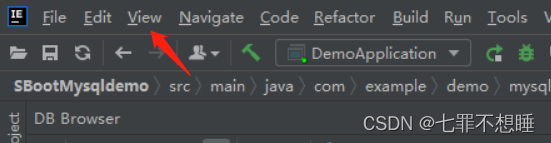
第一步:在idea中找到View->Tool Windows
然后发现我的idea里面并没有Database这一选项
第二步:找到File->Settings
第三步:找到plugins,然后在marketplace输入data,找到database navigate,点击install(因为我
-

Redis作为一款高性能的内存数据库,在日常应用中会面临着高并发的场景。为了应对这些需求,Redis提供了主从同步与读写分离的两种机制,以提高Redis的性能和可用性。本文将详细介绍Redis的主从同步与读写分离原理与实现方式。一、Redis的主从同步机制Redis的主从同步机制可以将数据从一个Redis服务器同步到另一个Redis服务器,以实现数据备份、负
-

1.docker search mysql 查看mysql版本2.docker pull mysql 要选择starts最高的那个name 进行下载3.docker images 查看下载好的镜像4.启动mysql实例 docker run --name&
-
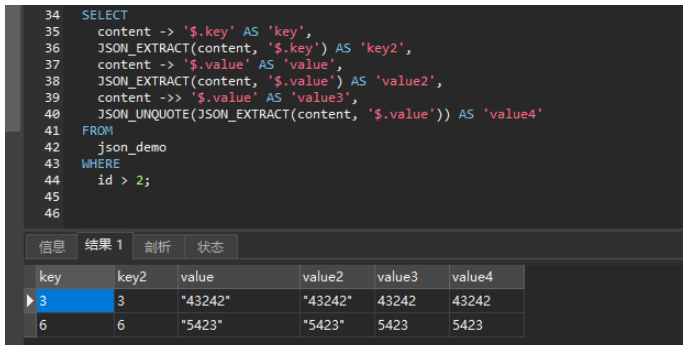
测试环境: MySQL8.0.19准备工作CREATE TABLE json_demo (
`id` INT ( 11 ) NOT NULL PRIMARY KEY,
`content` json NOT NULL
);
INSERT INTO&nb
-

MySQL 日期时间数据类型 1. datatime和date datetime格式:年-月-日 小时:分:秒 支持范围1000-01-01 00:00:00到9999-12-31 23:59:59 2. timestamp 时间戳 datetime和timestamp类型表现上
-

SQL中的JOINSQL是如何理解JOIN运算SQL对JOIN的定义两个集合(表)做笛卡尔积后再按某种条件过滤,写出来的语法就是A JOIN B ON …。理论上讲,笛卡尔积的结果集应该是以两个集合成员
-
react 一直遵循UI = fn(state) 的原则,有时候我们的state却和UI不同步 有时候组件本身在业务上不需要渲染,却又会再一次re-render。之前在项目中遇到的一些问题,这里做一个简单的分析,大家可以
-
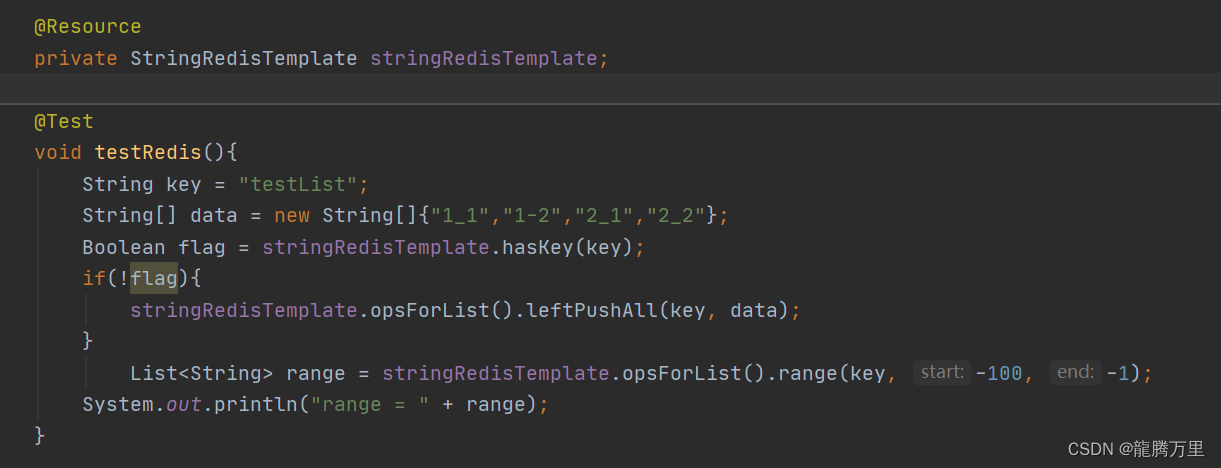
测试stringRedisTemplate.opsForList().range(key, start, end)的使用
结论(具体测试数据请往下看)
1、start—end总体保持着顺序就没问题
2、按照顺序,即便start < -N或者end > N-1也能查询出数据
3、特殊用法
-

如何在Java程序中正确关闭MySQL连接?MySQL是一个常用的关系型数据库管理系统,而Java是一种广泛使用的编程语言。在开发Java程序时,经常需要连接到MySQL数据库来进行数据的增删改查操作。然而,连接数据库是一个资源消耗较大的过程,如果不正确地关闭数据库连接,会浪费系统资源,甚至可能导致性能下降或程序崩溃。因此,正确关闭MySQL连接是一个至关重
-

MySQL双写缓冲优化原理与方法解析MySQL是一个开源的关系型数据库管理系统,用于处理大规模数据的存储和管理。在MySQL的日志系统中,存在一种机制称为“双写缓冲”,其作用是提高数据写入的性能和稳定性。本文将详细解析MySQL双写缓冲的原理和优化方法,并附带代码示例。一、双写缓冲原理在MySQL中,数据的写入是通过InnoDB存储引擎完成的。当用户执行一条
-

假设我们有一个表,现在需要在列名上添加AUTO_INCRMENT。为此,请使用MODIFY命令。在这里,我们首先创建一个演示表。mysql>createtableAddingAutoIncrement->(->Idint,->Namevarchar(200),->Primarykey(Id)->);QueryOK,0rowsaffected(0.47sec)我们在上面创建了一个表,现在让我们更改该表以在列名“Id”上添加AUTO_INCRMENT。语法如下-altert
-

实际上,MySQL允许我们在多个列上设置PRIMARYKEY。这样做的优点是我们可以将多个列作为单个实体进行处理。示例我们通过在多个列上定义复合主键来创建表分配,如下所示-mysql>Createtableallotment(RollNoInt,NameVarchar(20),RoomNoInt,PRIMARYKEY(RollNo,RoomNo));QueryOK,0rowsaffected(0.23sec)mysql>Describeallotment;+--------+---------
-

MySQL可以使用MySQLSLES存储库进行升级。让我们看看此升级所需的步骤。默认情况下,MySQLSLES存储库将MySQL更新到用户在安装期间选择的发行系列中的最新版本要更新到不同的发行系列,已选择的系列的子存储库需要被禁用。建议从一个系列升级到下一个系列,而不是跳过一个系列。使用MySQLSLES存储库时不支持就地降级MySQL。升级MySQL使用以下命令升级MySQL及其组件-shell>sudozypperupdatemysql-community-server否则,可以通过指示Zypp
-

MySQLMVCC原理解析和应用实践:提高数据库事务处理效率一、MVCC原理解析MVCC(Multi-VersionConcurrencyControl)是MySQL中实现并发控制的一种机制。它通过记录行的历史版本来实现并发事务的隔离性,避免了锁的争用和阻塞。MVCC的实现主要依赖于版本链和读视图。版本链每当一个事务对数据库进行修改时,MySQL
-

MySQL跨平台技术解析随着信息化时代的发展,数据库技术在各行业中扮演着越来越重要的角色。MySQL作为一个开源的关系型数据库管理系统,被广泛应用在各种应用场景中。随着网络的普及,不同平台之间的数据交互也变得越来越频繁,为了保证数据的稳定和一致性,跨平台数据传输和同步成为数据库开发中的一个重要问题。本文将深入探讨MySQL跨平台技术,通过具体的代码示例来解