Go语言技术文章
-
 布隆过滤器是解决缓存穿透最可控的手段,需部署在Redis之前拦截非法key;它不支持删除、存在误判率,须按真实数据量预估容量,并配合参数校验与限流使用。122 收藏
布隆过滤器是解决缓存穿透最可控的手段,需部署在Redis之前拦截非法key;它不支持删除、存在误判率,须按真实数据量预估容量,并配合参数校验与限流使用。122 收藏 -
 Redis集群执行Lua脚本失败大概率因KEYS未落在同一slot,必须用{}哈希标签确保所有KEYS经CRC16计算后归属相同slot,否则直接报CROSSSLOT错误,EVALSHA同理受限,脚本无法补救key设计缺陷。120 收藏
Redis集群执行Lua脚本失败大概率因KEYS未落在同一slot,必须用{}哈希标签确保所有KEYS经CRC16计算后归属相同slot,否则直接报CROSSSLOT错误,EVALSHA同理受限,脚本无法补救key设计缺陷。120 收藏 -
数据库 · MySQL | 1个月前 | binlog · 主从复制 · 故障排查 · MySQL教程 · DBA实战 · mysql DBA binlog 主从复制 MySQL 8.4 复制延迟 relay log
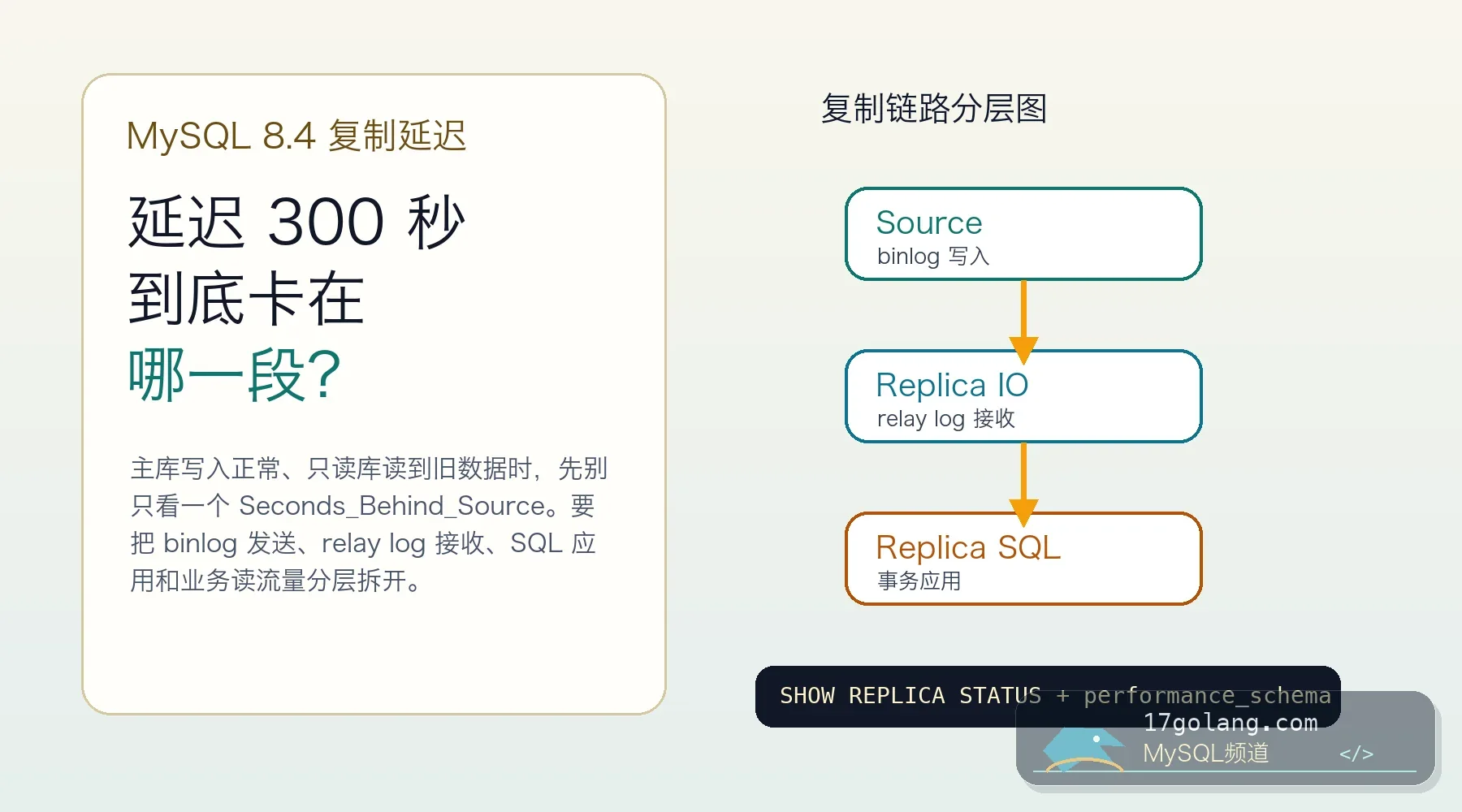 从只读库延迟导致读到旧数据的事故切入,讲清 MySQL 8.x 复制延迟如何区分 IO 接收、relay log 应用、大事务、并行复制和只读流量影响。119 收藏
从只读库延迟导致读到旧数据的事故切入,讲清 MySQL 8.x 复制延迟如何区分 IO 接收、relay log 应用、大事务、并行复制和只读流量影响。119 收藏 -
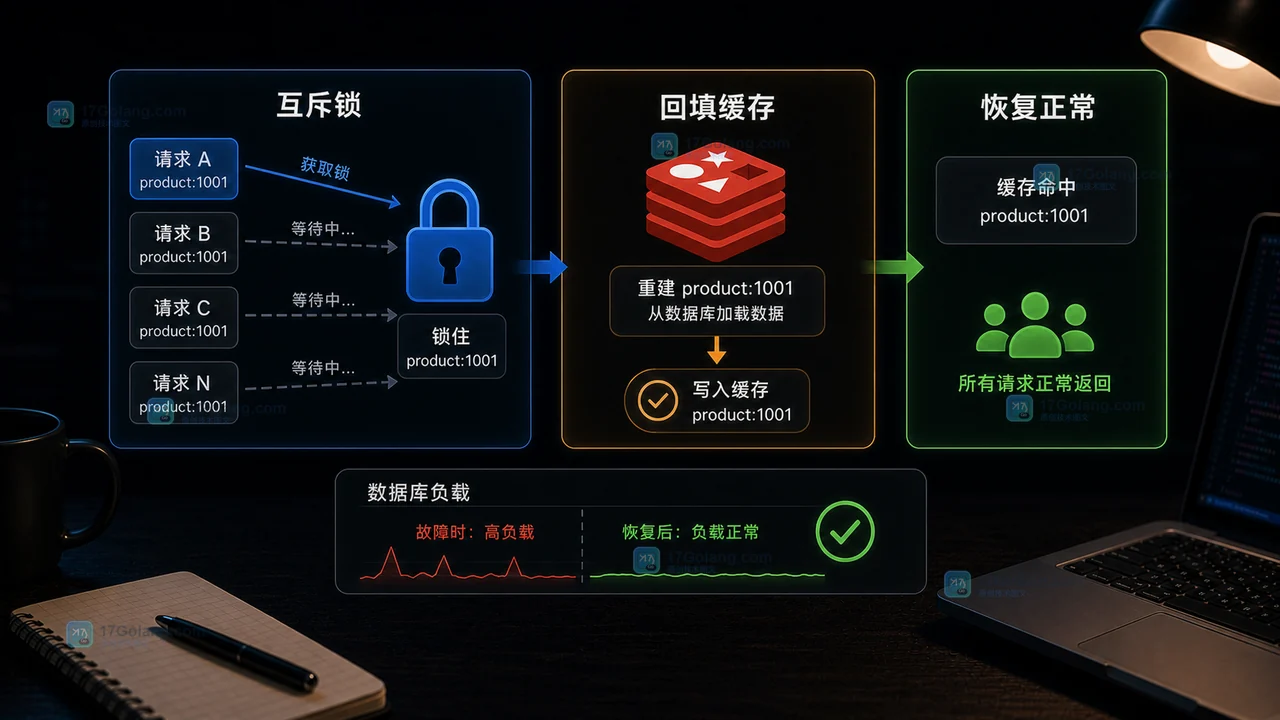 Redis 热点 key 在高并发下同时过期,所有请求会一起回源数据库,表现为 DB QPS 突增、接口超时和 Redis 命中率下降。排查时先看热点 key 的 TTL、命中率和回源日志,修复时用互斥锁、逻辑过期、随机 TTL 和降级保护控制回源压力。119 收藏
Redis 热点 key 在高并发下同时过期,所有请求会一起回源数据库,表现为 DB QPS 突增、接口超时和 Redis 命中率下降。排查时先看热点 key 的 TTL、命中率和回源日志,修复时用互斥锁、逻辑过期、随机 TTL 和降级保护控制回源压力。119 收藏 -
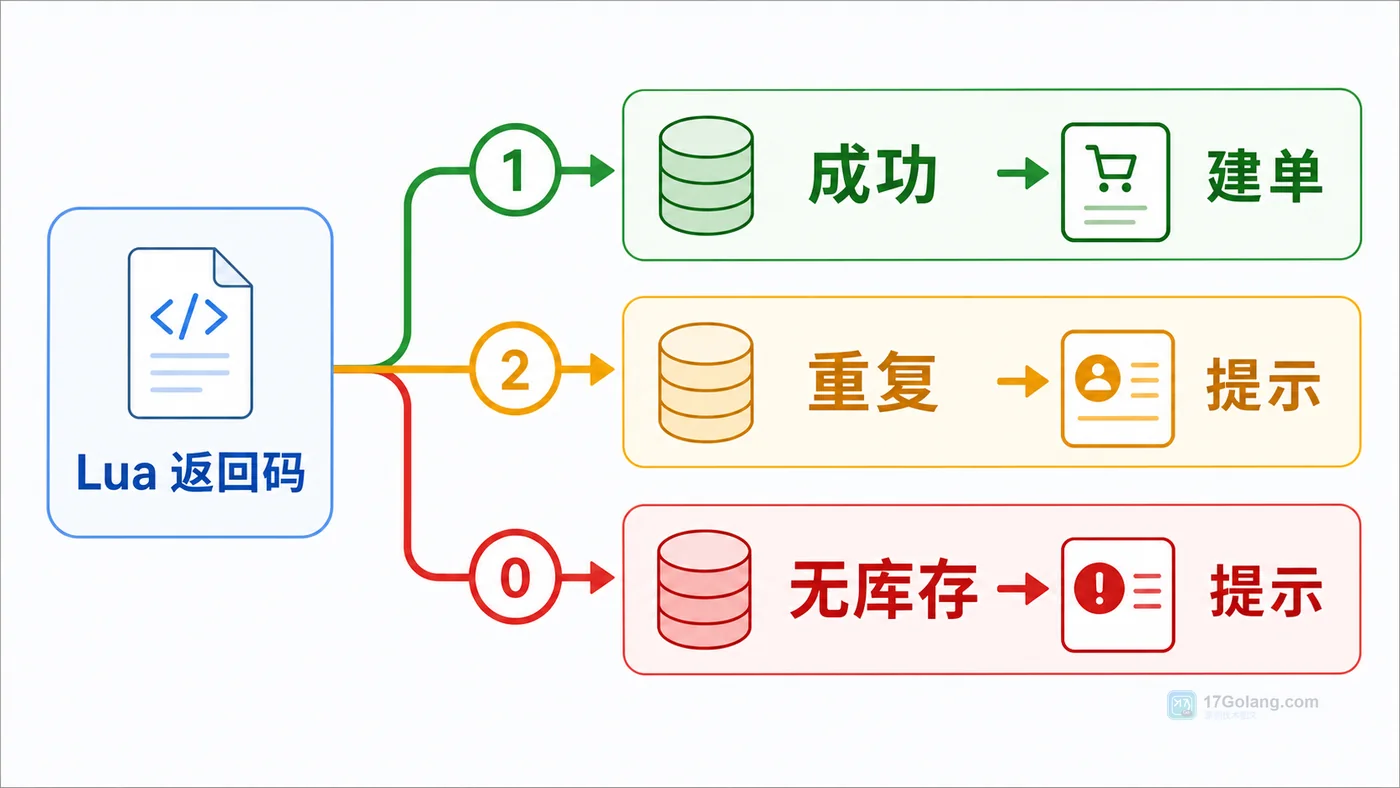 本文用秒杀扣库存场景讲清 Redis Lua 的落地方式:在一个脚本里完成库存校验、重复订单判断、扣减库存和记录订单结果,减少并发下超卖和重复扣减风险。118 收藏
本文用秒杀扣库存场景讲清 Redis Lua 的落地方式:在一个脚本里完成库存校验、重复订单判断、扣减库存和记录订单结果,减少并发下超卖和重复扣减风险。118 收藏 -
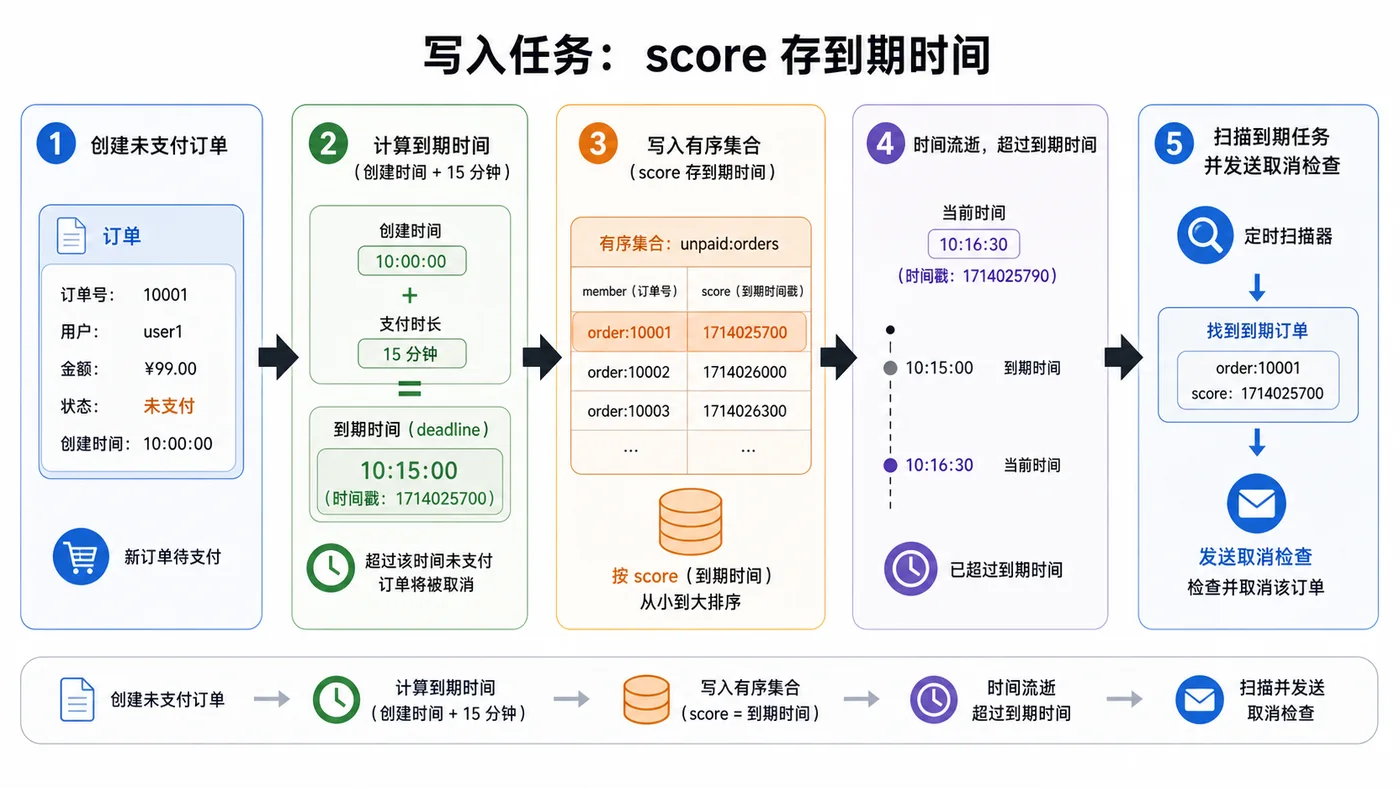 本文用 Redis ZSET 设计一个轻量延迟队列,讲清楚如何写入订单超时任务、按时间扫描到期任务、抢占删除、防重复处理以及失败重试。116 收藏
本文用 Redis ZSET 设计一个轻量延迟队列,讲清楚如何写入订单超时任务、按时间扫描到期任务、抢占删除、防重复处理以及失败重试。116 收藏 -
数据库 · MySQL | 1星期前 | MySQL · 磁盘空间 · 故障复盘 · 临时表 · 报表优化 · mysql 临时表 Created_tmp_disk_tables 磁盘打满 报表接口 故障复盘
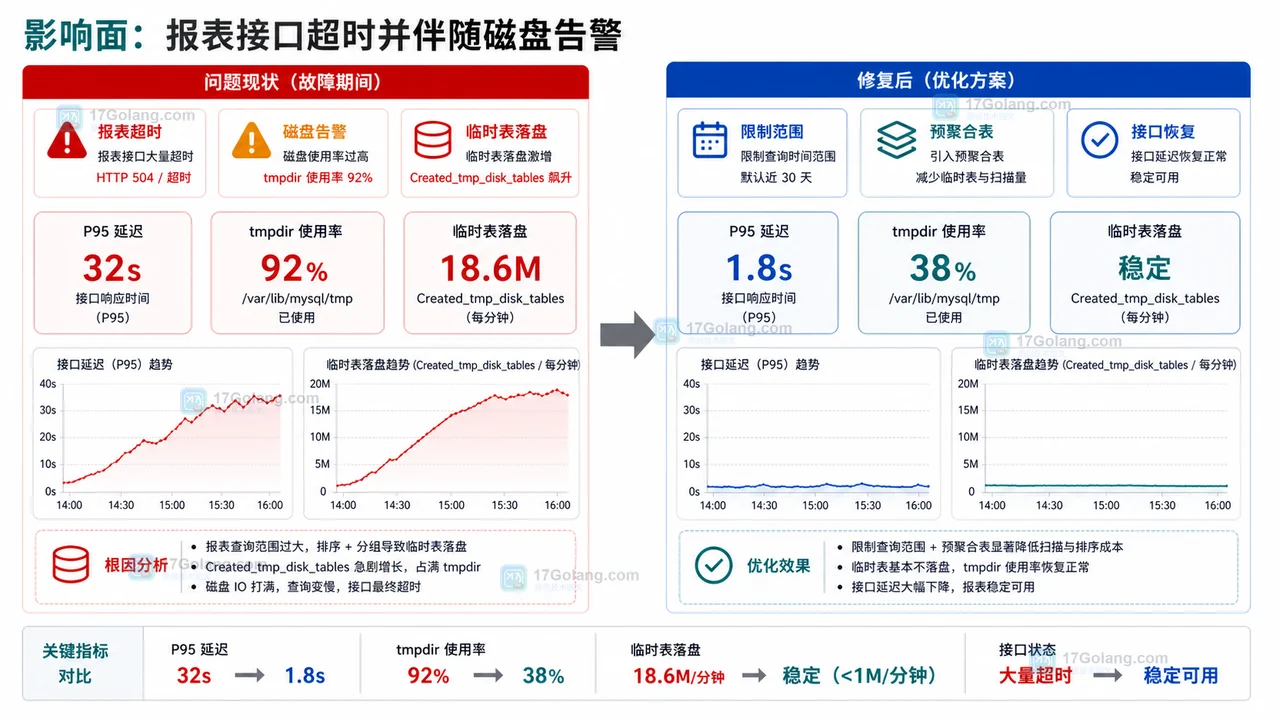 本文用一次报表接口超时故障复盘说明 MySQL 临时表打满磁盘的排查过程:从影响面、时间线、触发 SQL、根因定位到临时止血和防复发措施。114 收藏
本文用一次报表接口超时故障复盘说明 MySQL 临时表打满磁盘的排查过程:从影响面、时间线、触发 SQL、根因定位到临时止血和防复发措施。114 收藏 -
 appendfsyncalways会让Redis卡在磁盘上,因其每条命令都强制调用fsync()等待硬件确认落盘,使QPS被钉死在磁盘IOPS天花板;而everysec通过后台线程批量刷盘解耦主线程与I/O,大幅降低IOPS压力但引入秒级延迟毛刺。112 收藏
appendfsyncalways会让Redis卡在磁盘上,因其每条命令都强制调用fsync()等待硬件确认落盘,使QPS被钉死在磁盘IOPS天花板;而everysec通过后台线程批量刷盘解耦主线程与I/O,大幅降低IOPS压力但引入秒级延迟毛刺。112 收藏 -
 Redis内存爆满主因是业务接口批量生成无TTL垃圾Key,需在防火墙层限流新建连接并绑定127.0.0.1监听,禁用公网暴露与弱密码。112 收藏
Redis内存爆满主因是业务接口批量生成无TTL垃圾Key,需在防火墙层限流新建连接并绑定127.0.0.1监听,禁用公网暴露与弱密码。112 收藏 -
 Pub/Sub是无存储的实时广播机制,消息断连即丢,适合允许丢失的在线通知;Stream是带ACK的持久化消息队列,支持回溯、消费者组和精确控制,但需手动管理XACK与MAXLEN。111 收藏
Pub/Sub是无存储的实时广播机制,消息断连即丢,适合允许丢失的在线通知;Stream是带ACK的持久化消息队列,支持回溯、消费者组和精确控制,但需手动管理XACK与MAXLEN。111 收藏 -
 JedisPool不自动处理主从切换或断连重连,需应用层干预;卡住主因是连接池耗尽或失效连接未剔除,而非未重连。111 收藏
JedisPool不自动处理主从切换或断连重连,需应用层干预;卡住主因是连接池耗尽或失效连接未剔除,而非未重连。111 收藏 -
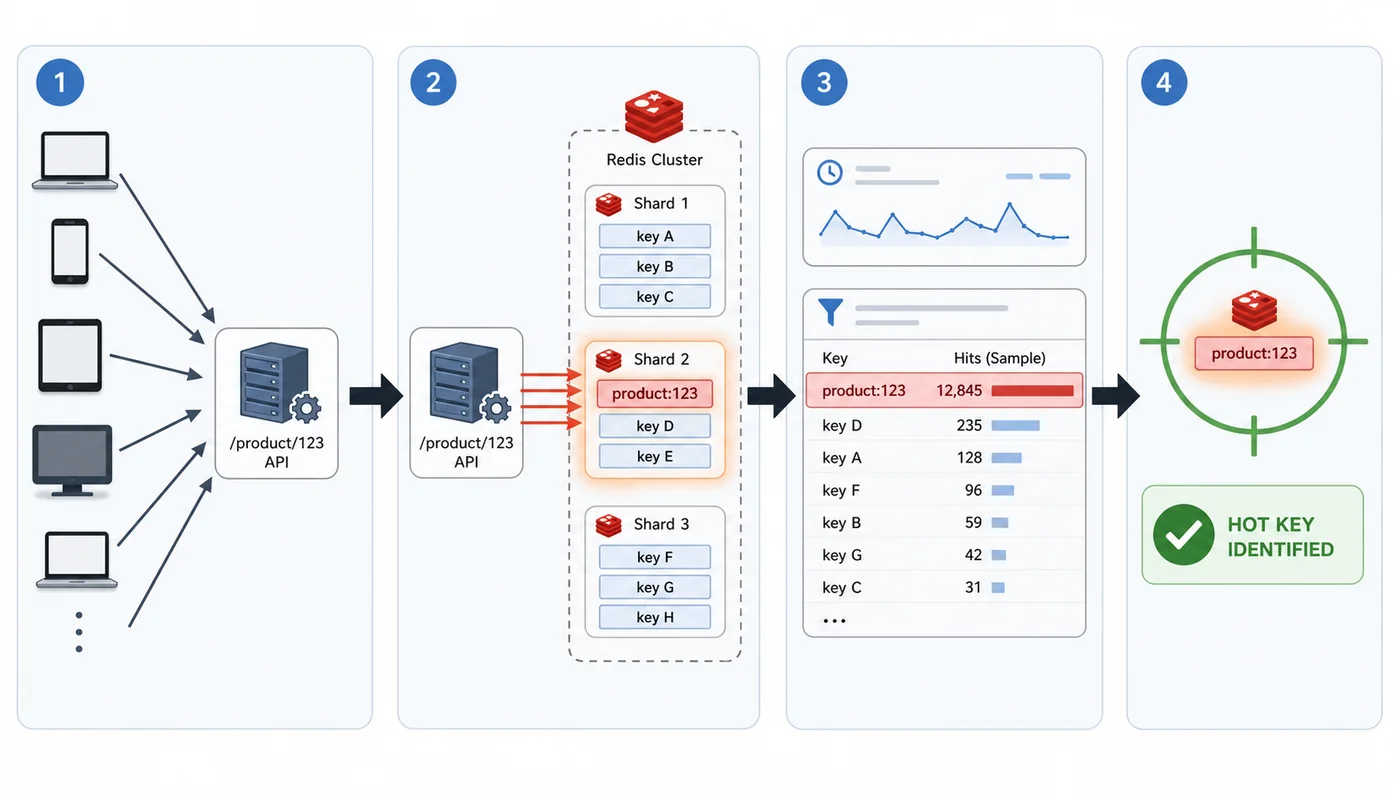 本文从一次商品详情接口抖动出发,演示如何发现 Redis 热 Key、判断访问倾斜,并通过过期时间抖动、本地短缓存、singleflight 合并加载和拆分 Key 降低热点冲击。111 收藏
本文从一次商品详情接口抖动出发,演示如何发现 Redis 热 Key、判断访问倾斜,并通过过期时间抖动、本地短缓存、singleflight 合并加载和拆分 Key 降低热点冲击。111 收藏 -
 SCRIPTKILL只能终止未执行写命令的脚本;一旦调用redis.call('set')等写操作,脚本变为UNKILLABLE,因Redis为保障原子性禁止中途终止,否则可能导致数据不一致。109 收藏
SCRIPTKILL只能终止未执行写命令的脚本;一旦调用redis.call('set')等写操作,脚本变为UNKILLABLE,因Redis为保障原子性禁止中途终止,否则可能导致数据不一致。109 收藏 -
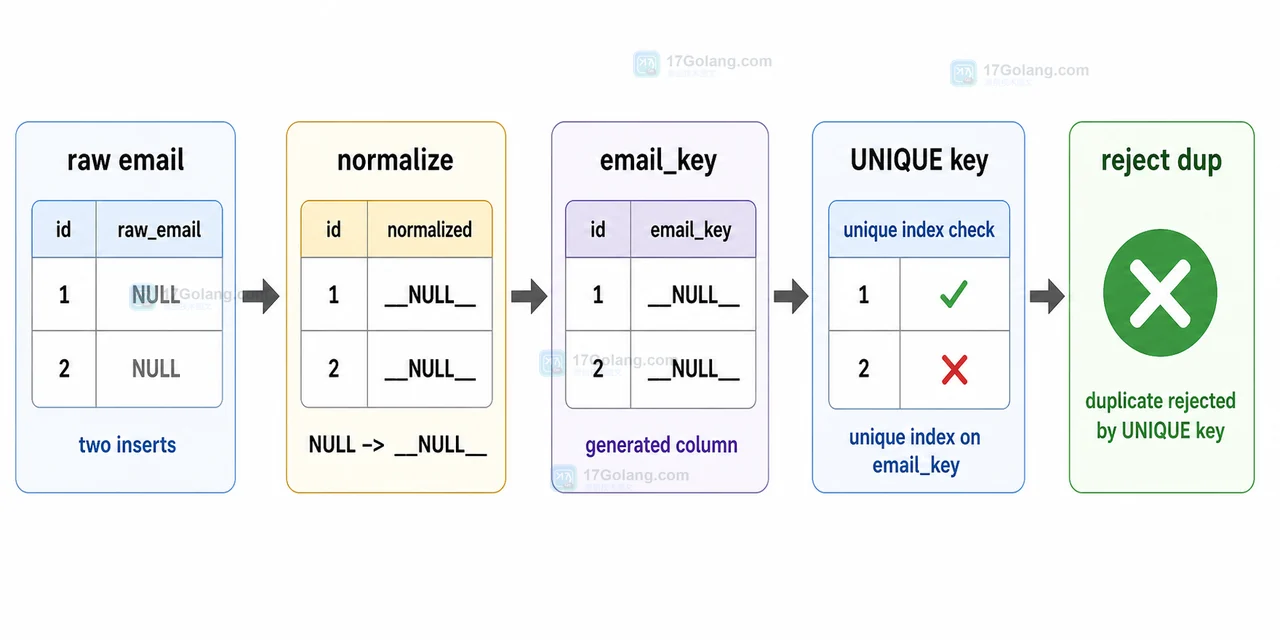 从一个唯一索引没有拦住多条 NULL 数据的现场开始,复现 MySQL 唯一索引与 NULL 的行为,再用 NOT NULL、业务默认值和生成列三种方案修复约束边界。109 收藏
从一个唯一索引没有拦住多条 NULL 数据的现场开始,复现 MySQL 唯一索引与 NULL 的行为,再用 NOT NULL、业务默认值和生成列三种方案修复约束边界。109 收藏 -
 MySQL数据备份的关键方法包括:一、使用mysqldump进行逻辑备份,适合中小型数据库,可通过命令实现全量备份并结合压缩节省空间;二、物理备份通过直接复制数据文件实现,速度快但需停机或使用一致性机制;三、利用binlog实现增量备份,支持时间点恢复,建议定期归档日志以减少数据丢失风险;四、合理策略如每日全量+小时binlog归档、周全量+日增量+binlog、主从复制+定时备份等,同时必须定期验证备份可恢复性。105 收藏
MySQL数据备份的关键方法包括:一、使用mysqldump进行逻辑备份,适合中小型数据库,可通过命令实现全量备份并结合压缩节省空间;二、物理备份通过直接复制数据文件实现,速度快但需停机或使用一致性机制;三、利用binlog实现增量备份,支持时间点恢复,建议定期归档日志以减少数据丢失风险;四、合理策略如每日全量+小时binlog归档、周全量+日增量+binlog、主从复制+定时备份等,同时必须定期验证备份可恢复性。105 收藏