Go语言技术文章
-
 必须配合日期动态生成key,因Bitmap无时间维度,共用key会丢失日期信息且导致单key膨胀、RDB/AOF暴增、主从延迟;用户ID须映射为非负整数offset,避免直接强转;BITCOUNT偏高多因key未清理或offset错位;5000万DAU下Bitmap体积约6.25MB,但需防ID稀疏浪费内存。191 收藏
必须配合日期动态生成key,因Bitmap无时间维度,共用key会丢失日期信息且导致单key膨胀、RDB/AOF暴增、主从延迟;用户ID须映射为非负整数offset,避免直接强转;BITCOUNT偏高多因key未清理或offset错位;5000万DAU下Bitmap体积约6.25MB,但需防ID稀疏浪费内存。191 收藏 -
 INFOkeyspace无法反映淘汰情况,因其仅统计存活key数量,不区分已过期未删除或已被淘汰的key,且不记录evicted_keys等关键淘汰指标。191 收藏
INFOkeyspace无法反映淘汰情况,因其仅统计存活key数量,不区分已过期未删除或已被淘汰的key,且不记录evicted_keys等关键淘汰指标。191 收藏 -
 从 MySQL 8.4 Skip Scan 入手,讲清复合索引没有左前缀条件时优化器为什么仍可能走索引,以及如何用 EXPLAIN ANALYZE 和 optimizer_switch 做生产验证。189 收藏
从 MySQL 8.4 Skip Scan 入手,讲清复合索引没有左前缀条件时优化器为什么仍可能走索引,以及如何用 EXPLAIN ANALYZE 和 optimizer_switch 做生产验证。189 收藏 -
 LPUSH+LPOP无法自动限长,因LPOP删队首而新元素入队尾,导致长度持续增长;唯一可靠方式是LPUSH后立即LTRIM,或用Lua脚本原子执行推入与截断。187 收藏
LPUSH+LPOP无法自动限长,因LPOP删队首而新元素入队尾,导致长度持续增长;唯一可靠方式是LPUSH后立即LTRIM,或用Lua脚本原子执行推入与截断。187 收藏 -
 选择合适的MySQL数据类型能节省存储空间、提升查询性能并确保数据准确性。常见的数据类型分为数值型(如INT、DECIMAL)、字符串型(如CHAR、VARCHAR)和日期时间型(如DATE、DATETIME、TIMESTAMP)。选择时应遵循几个关键点:1.节省存储空间,如状态字段用TINYINT;2.提高查询效率,优先使用定长类型;3.避免精度丢失,金额字段用DECIMAL;4.注意默认行为差异,如TIMESTAMP自动处理时区。常见场景推荐:用户ID用INTUNSIGNED或BIGINT,用户名用V187 收藏
选择合适的MySQL数据类型能节省存储空间、提升查询性能并确保数据准确性。常见的数据类型分为数值型(如INT、DECIMAL)、字符串型(如CHAR、VARCHAR)和日期时间型(如DATE、DATETIME、TIMESTAMP)。选择时应遵循几个关键点:1.节省存储空间,如状态字段用TINYINT;2.提高查询效率,优先使用定长类型;3.避免精度丢失,金额字段用DECIMAL;4.注意默认行为差异,如TIMESTAMP自动处理时区。常见场景推荐:用户ID用INTUNSIGNED或BIGINT,用户名用V187 收藏 -
数据库 · Redis | 2星期前 | Redis · 消息队列 · Stream · 消费组 · redis 消息队列 Redis Stream 消费组 XREADGROUP XACK XPENDING XAUTOCLAIM
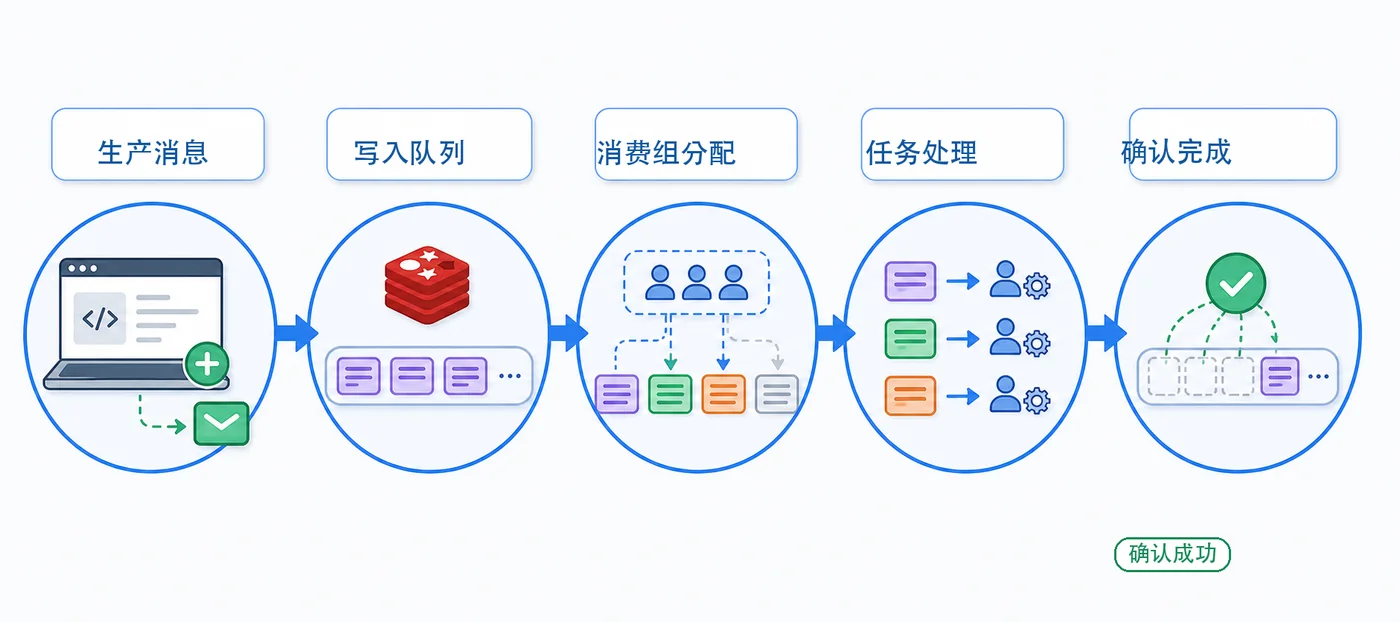 用订单异步处理场景讲清楚 Redis Stream 的实用队列模型:生产者写入消息,消费组分配任务,Worker 处理成功后 ACK,失败或超时的消息进入待确认列表,再通过 XPENDING 和 XAUTOCLAIM 做重投。187 收藏
用订单异步处理场景讲清楚 Redis Stream 的实用队列模型:生产者写入消息,消费组分配任务,Worker 处理成功后 ACK,失败或超时的消息进入待确认列表,再通过 XPENDING 和 XAUTOCLAIM 做重投。187 收藏 -
 Redis自动RDB备份不能仅用crontab调用bgsave,因BGSAVE异步返回OK不保证写入完成,需校验rdb_last_save_time和文件非空,并动态获取路径、加超时、轮转清理。186 收藏
Redis自动RDB备份不能仅用crontab调用bgsave,因BGSAVE异步返回OK不保证写入完成,需校验rdb_last_save_time和文件非空,并动态获取路径、加超时、轮转清理。186 收藏 -
 AOF重写后文件变大是因为重写时仍会写入带过期时间但尚未过期的key,尤其高频短TTL的SET/EXPIREAT等指令堆积且无法压缩,导致AOF体积膨胀。186 收藏
AOF重写后文件变大是因为重写时仍会写入带过期时间但尚未过期的key,尤其高频短TTL的SET/EXPIREAT等指令堆积且无法压缩,导致AOF体积膨胀。186 收藏 -
 Redis内存飙升多因bigkey,应优先在从节点用redis-cli--bigkeys扫描,避免主节点阻塞;它仅返回每类最大key且不反映真实内存,需结合MEMORYUSAGE和访问频次进一步分析。185 收藏
Redis内存飙升多因bigkey,应优先在从节点用redis-cli--bigkeys扫描,避免主节点阻塞;它仅返回每类最大key且不反映真实内存,需结合MEMORYUSAGE和访问频次进一步分析。185 收藏 -
 RedisLua脚本中不能直接执行SET等命令,必须通过redis.call()或redis.pcall()调用;MULTI/EXEC等事务命令禁用;所有key需显式传入,集群下须同slot;返回值类型需手动判断,避免误判false/0。185 收藏
RedisLua脚本中不能直接执行SET等命令,必须通过redis.call()或redis.pcall()调用;MULTI/EXEC等事务命令禁用;所有key需显式传入,集群下须同slot;返回值类型需手动判断,避免误判false/0。185 收藏 -
 ZADD的score不能用时间戳,因同分排序不稳定且时间戳递增违背“分数越高名次越靠前”逻辑;应使用业务分数(如积分)并利用ZADD覆盖更新、ZINCRBY原子累加、ZREM安全删除。183 收藏
ZADD的score不能用时间戳,因同分排序不稳定且时间戳递增违背“分数越高名次越靠前”逻辑;应使用业务分数(如积分)并利用ZADD覆盖更新、ZINCRBY原子累加、ZREM安全删除。183 收藏 -
 RedisPub/Sub不适合异步任务处理,因其无确认机制、无持久化、不支持消费者组与积压缓冲;应选用LPUSH+BRPOP或XADD+XREADGROUP(Stream)实现可靠任务队列。183 收藏
RedisPub/Sub不适合异步任务处理,因其无确认机制、无持久化、不支持消费者组与积压缓冲;应选用LPUSH+BRPOP或XADD+XREADGROUP(Stream)实现可靠任务队列。183 收藏 -
 短连接在Redis中严重伤性能,因其每次需完整TCP握手、认证、DB切换与释放,局域网下单次开销达1–3ms,超GET命令5–10倍,并引发TIME_WAIT端口耗尽。181 收藏
短连接在Redis中严重伤性能,因其每次需完整TCP握手、认证、DB切换与释放,局域网下单次开销达1–3ms,超GET命令5–10倍,并引发TIME_WAIT端口耗尽。181 收藏 -
 主从同步突然变成全量复制,大概率因从节点偏移量超出主节点复制积压缓冲区范围;可通过inforeplication比对master_repl_offset、repl_backlog_first_byte_offset和repl_backlog_size判断是否缓冲区循环覆盖,再结合run_id是否变更、是否首次连接等排查。181 收藏
主从同步突然变成全量复制,大概率因从节点偏移量超出主节点复制积压缓冲区范围;可通过inforeplication比对master_repl_offset、repl_backlog_first_byte_offset和repl_backlog_size判断是否缓冲区循环覆盖,再结合run_id是否变更、是否首次连接等排查。181 收藏 -
 RedisLua脚本不能实现真正的分布式事务回滚,仅能通过条件化原子写入预防性拒绝,失败后需业务层设计补偿机制。180 收藏
RedisLua脚本不能实现真正的分布式事务回滚,仅能通过条件化原子写入预防性拒绝,失败后需业务层设计补偿机制。180 收藏