Go语言技术文章
-
 单纯靠频率限制无法防住缓存穿透,因其无法识别语义非法请求(如user_id=-1),且分布式攻击下单IP低频可绕过;限流仅作为兜底,需与布隆过滤器、空值缓存等联动,并结合多维特征精准识别恶意请求。380 收藏
单纯靠频率限制无法防住缓存穿透,因其无法识别语义非法请求(如user_id=-1),且分布式攻击下单IP低频可绕过;限流仅作为兜底,需与布隆过滤器、空值缓存等联动,并结合多维特征精准识别恶意请求。380 收藏 -
 生产环境必须组合使用RDB和AOF:RDB作冷备快照,AOF负责实时写入;仅用AOF有崩溃导致启动失败、重放慢、数据丢失风险;仅用RDB则丢失窗口大、fork开销高、无法增量修复。379 收藏
生产环境必须组合使用RDB和AOF:RDB作冷备快照,AOF负责实时写入;仅用AOF有崩溃导致启动失败、重放慢、数据丢失风险;仅用RDB则丢失窗口大、fork开销高、无法增量修复。379 收藏 -
 根本原因是sentineldown-after-milliseconds阈值过短,而主库执行耗时Lua脚本导致PING响应超时,哨兵误判为主观下线;典型表现为INFOreplication正常但日志频繁出现+sdown又快速恢复。378 收藏
根本原因是sentineldown-after-milliseconds阈值过短,而主库执行耗时Lua脚本导致PING响应超时,哨兵误判为主观下线;典型表现为INFOreplication正常但日志频繁出现+sdown又快速恢复。378 收藏 -
 RedisLua脚本无法实现SCAN分页,因脚本无状态且无法维护游标;唯一可行方案是客户端驱动SCAN分页,Lua仅负责单次结果的模式匹配与截取。378 收藏
RedisLua脚本无法实现SCAN分页,因脚本无状态且无法维护游标;唯一可行方案是客户端驱动SCAN分页,Lua仅负责单次结果的模式匹配与截取。378 收藏 -
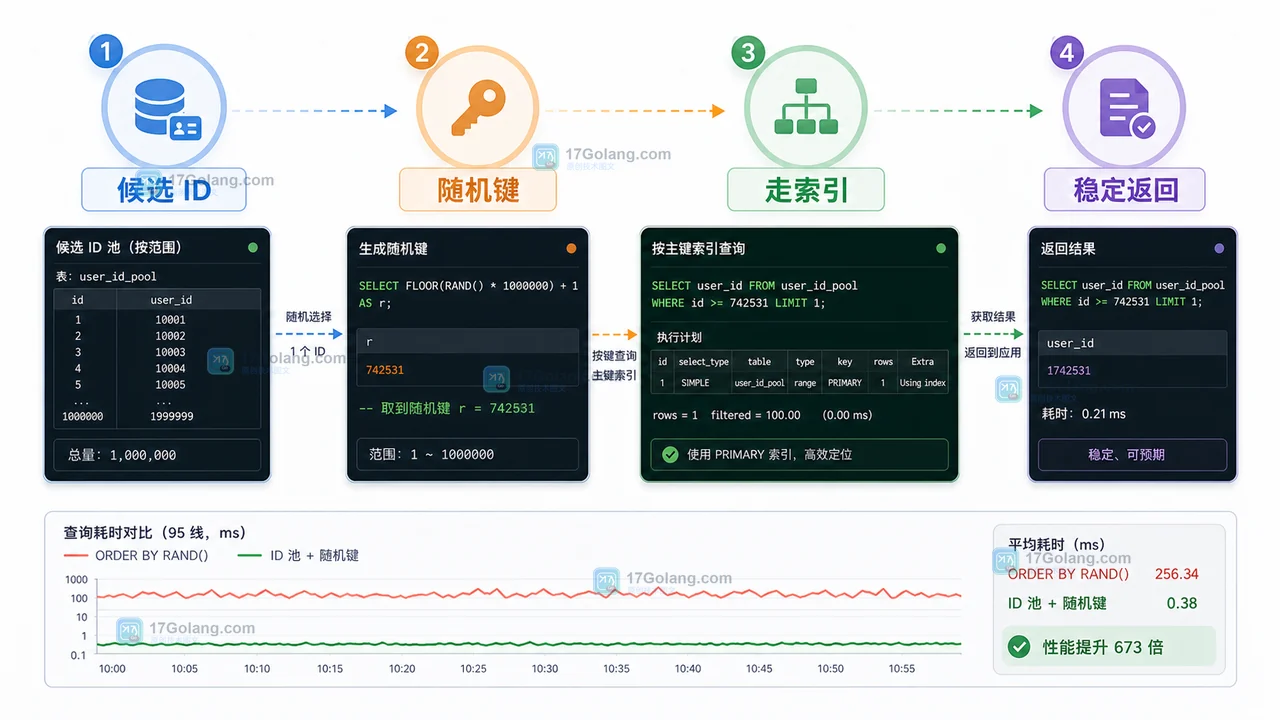 MySQL 里用 ORDER BY RAND() 做随机推荐,小表还能凑合,大表高并发下容易触发全表排序、临时表放大和 CPU 飙升。更稳的做法是先缩小候选集合,再用候选 ID 池、随机键或业务侧抽样把查询控制在索引范围内。378 收藏
MySQL 里用 ORDER BY RAND() 做随机推荐,小表还能凑合,大表高并发下容易触发全表排序、临时表放大和 CPU 飙升。更稳的做法是先缩小候选集合,再用候选 ID 池、随机键或业务侧抽样把查询控制在索引范围内。378 收藏 -
 Redis集群节点宕机是否自动恢复,取决于它是不是主节点、有没有足够多的主节点在线投票,以及从节点是否满足参选资格;不是所有宕机都会触发转移,更不是宕机后立刻切换。377 收藏
Redis集群节点宕机是否自动恢复,取决于它是不是主节点、有没有足够多的主节点在线投票,以及从节点是否满足参选资格;不是所有宕机都会触发转移,更不是宕机后立刻切换。377 收藏 -
 ZREVRANGEBYSCORE不适用于超时任务检测,因其按score降序返回,而超时检测需升序查找score≤当前时间戳的任务;正确做法是用ZRANGEBYSCOREtasks-inf[current_timestamp]配合Lua原子执行扫描与删除,并确保score为高精度到期时间戳以避免排序混乱和堆积性能问题。370 收藏
ZREVRANGEBYSCORE不适用于超时任务检测,因其按score降序返回,而超时检测需升序查找score≤当前时间戳的任务;正确做法是用ZRANGEBYSCOREtasks-inf[current_timestamp]配合Lua原子执行扫描与删除,并确保score为高精度到期时间戳以避免排序混乱和堆积性能问题。370 收藏 -
 redis-cli--clusterinfo仅提供槽位、键数和从节点数的粗粒度分布,无法反映真实CPU/内存负载;需结合INFOmemory、SLOWLOG和INFOstats交叉验证,因slot均匀不等于负载均匀。369 收藏
redis-cli--clusterinfo仅提供槽位、键数和从节点数的粗粒度分布,无法反映真实CPU/内存负载;需结合INFOmemory、SLOWLOG和INFOstats交叉验证,因slot均匀不等于负载均匀。369 收藏 -
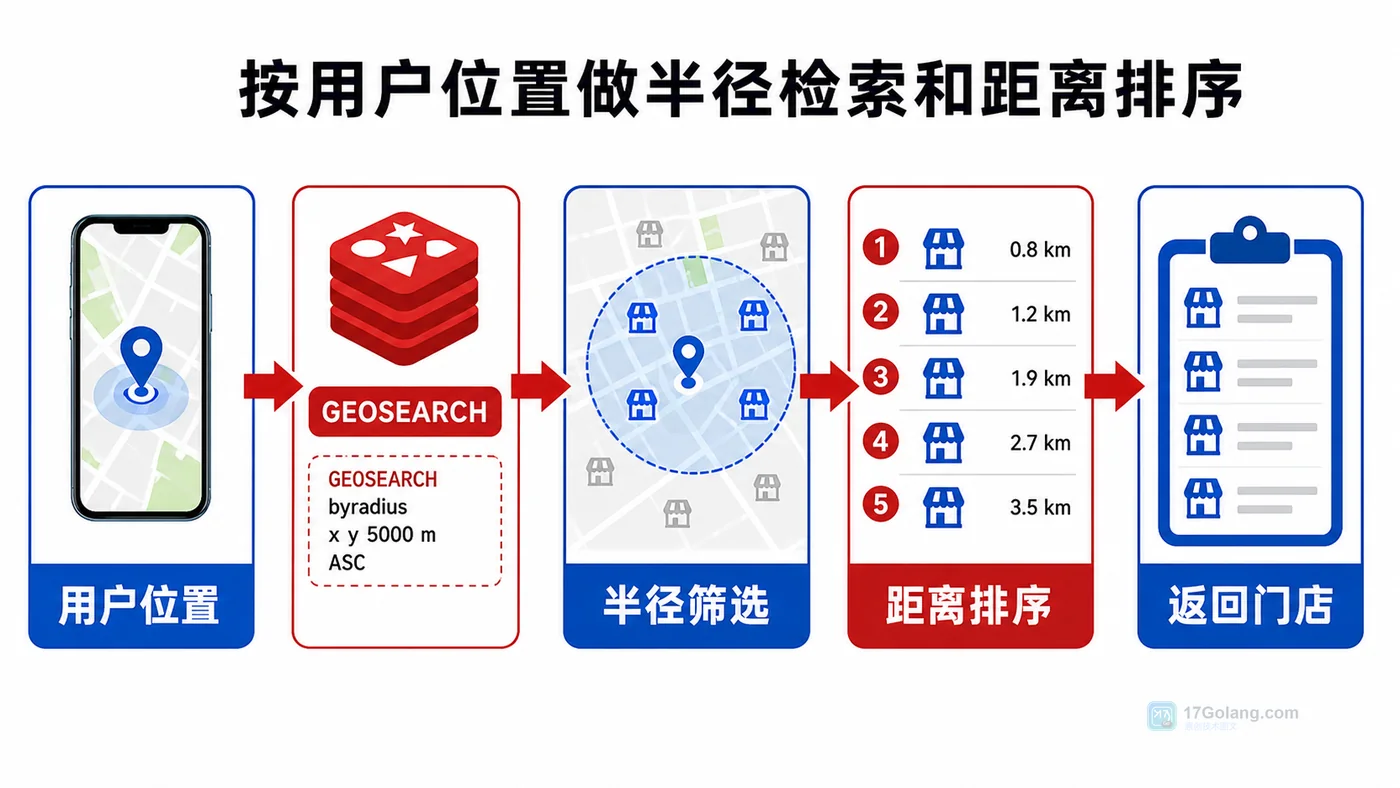 本文用附近门店查询场景讲清 Redis GEO:如何把门店经纬度写入地理索引,如何按用户当前位置做半径检索、距离排序和分页返回,并整理上线时常见的坐标、单位、数据更新问题。368 收藏
本文用附近门店查询场景讲清 Redis GEO:如何把门店经纬度写入地理索引,如何按用户当前位置做半径检索、距离排序和分页返回,并整理上线时常见的坐标、单位、数据更新问题。368 收藏 -
 appendfsyncalways会让Redis卡在磁盘上,因其每条命令都强制调用fsync()等待硬件确认落盘,使QPS被钉死在磁盘IOPS天花板;而everysec通过后台线程批量刷盘解耦主线程与I/O,大幅降低IOPS压力但引入秒级延迟毛刺。367 收藏
appendfsyncalways会让Redis卡在磁盘上,因其每条命令都强制调用fsync()等待硬件确认落盘,使QPS被钉死在磁盘IOPS天花板;而everysec通过后台线程批量刷盘解耦主线程与I/O,大幅降低IOPS压力但引入秒级延迟毛刺。367 收藏 -
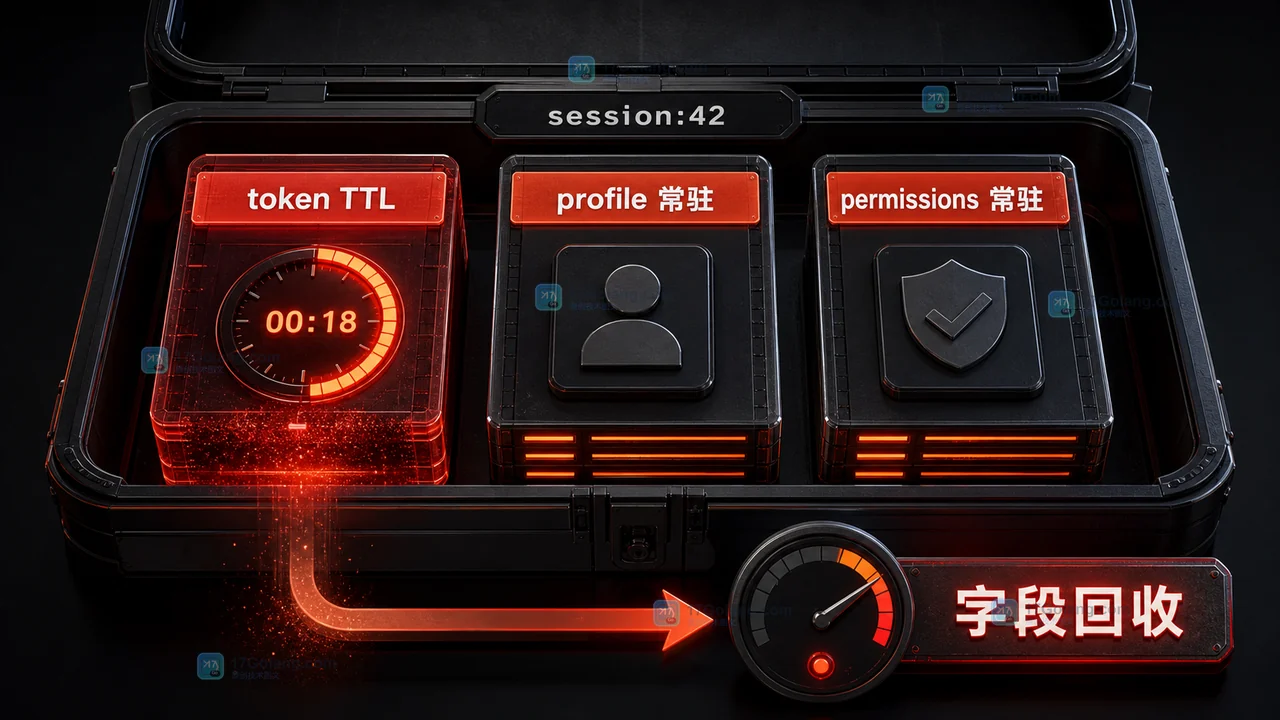 Redis 7.4 起支持给 Hash 的单个字段设置 TTL。本文用会话 token 场景说明 HEXPIRE、HTTL、条件更新和兼容检查,避免为了一个短期字段让整条 Hash 一起过期。366 收藏
Redis 7.4 起支持给 Hash 的单个字段设置 TTL。本文用会话 token 场景说明 HEXPIRE、HTTL、条件更新和兼容检查,避免为了一个短期字段让整条 Hash 一起过期。366 收藏 -
数据库 · Redis | 1星期前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计
 Redis 被直接暴露在公网,靠一个密码或 protected-mode 都不够。更稳妥的方案是让端口只对可信应用网络开放,再用 ACL 分配最小命令和 key 权限、启用所需的传输保护并保留配置审计。本文按 Redis 官方安全文档梳理风险和可验证的检查顺序。364 收藏
Redis 被直接暴露在公网,靠一个密码或 protected-mode 都不够。更稳妥的方案是让端口只对可信应用网络开放,再用 ACL 分配最小命令和 key 权限、启用所需的传输保护并保留配置审计。本文按 Redis 官方安全文档梳理风险和可验证的检查顺序。364 收藏 -
 LPUSH+BRPOP构成FIFO阻塞队列,兼容Redis2.0+;但消费失败会导致消息丢失,适合允许少量丢失的场景,强可靠性需求应改用Stream。363 收藏
LPUSH+BRPOP构成FIFO阻塞队列,兼容Redis2.0+;但消费失败会导致消息丢失,适合允许少量丢失的场景,强可靠性需求应改用Stream。363 收藏 -
 RedisSentinel进程挂了由systemd兜底重启,因其默认可用、配置简洁、日志集成好;需配置Restart=always、明确--sentinel参数、检查端口绑定、配置语法及目录权限,并通过redis-cli验证哨兵实际工作状态。361 收藏
RedisSentinel进程挂了由systemd兜底重启,因其默认可用、配置简洁、日志集成好;需配置Restart=always、明确--sentinel参数、检查端口绑定、配置语法及目录权限,并通过redis-cli验证哨兵实际工作状态。361 收藏 -
 根本原因是COW导致RSS内存暴涨触碰maxmemory上限而被迫淘汰;bgsave时fork子进程触发Copy-On-Write,父进程修改内存页即复制物理页,临近maxmemory时瞬时内存增长直接触发淘汰。360 收藏
根本原因是COW导致RSS内存暴涨触碰maxmemory上限而被迫淘汰;bgsave时fork子进程触发Copy-On-Write,父进程修改内存页即复制物理页,临近maxmemory时瞬时内存增长直接触发淘汰。360 收藏