Go语言技术文章
-
 必须同时启用io-threads和io-threads-do-reads,否则I/O线程不参与读请求处理;io-threads≥2才生效,需configrewrite或重启;推荐值为min(4,CPU核心数×0.7),NUMA架构下必须用server_cpulist绑定同node核心。326 收藏
必须同时启用io-threads和io-threads-do-reads,否则I/O线程不参与读请求处理;io-threads≥2才生效,需configrewrite或重启;推荐值为min(4,CPU核心数×0.7),NUMA架构下必须用server_cpulist绑定同node核心。326 收藏 -
数据库 · MySQL | 1个月前 | InnoDB · 故障排查 · 生产实践 · MySQL教程 · 事务隔离 · mysql innodb Purge Lag History List 长事务 Undo
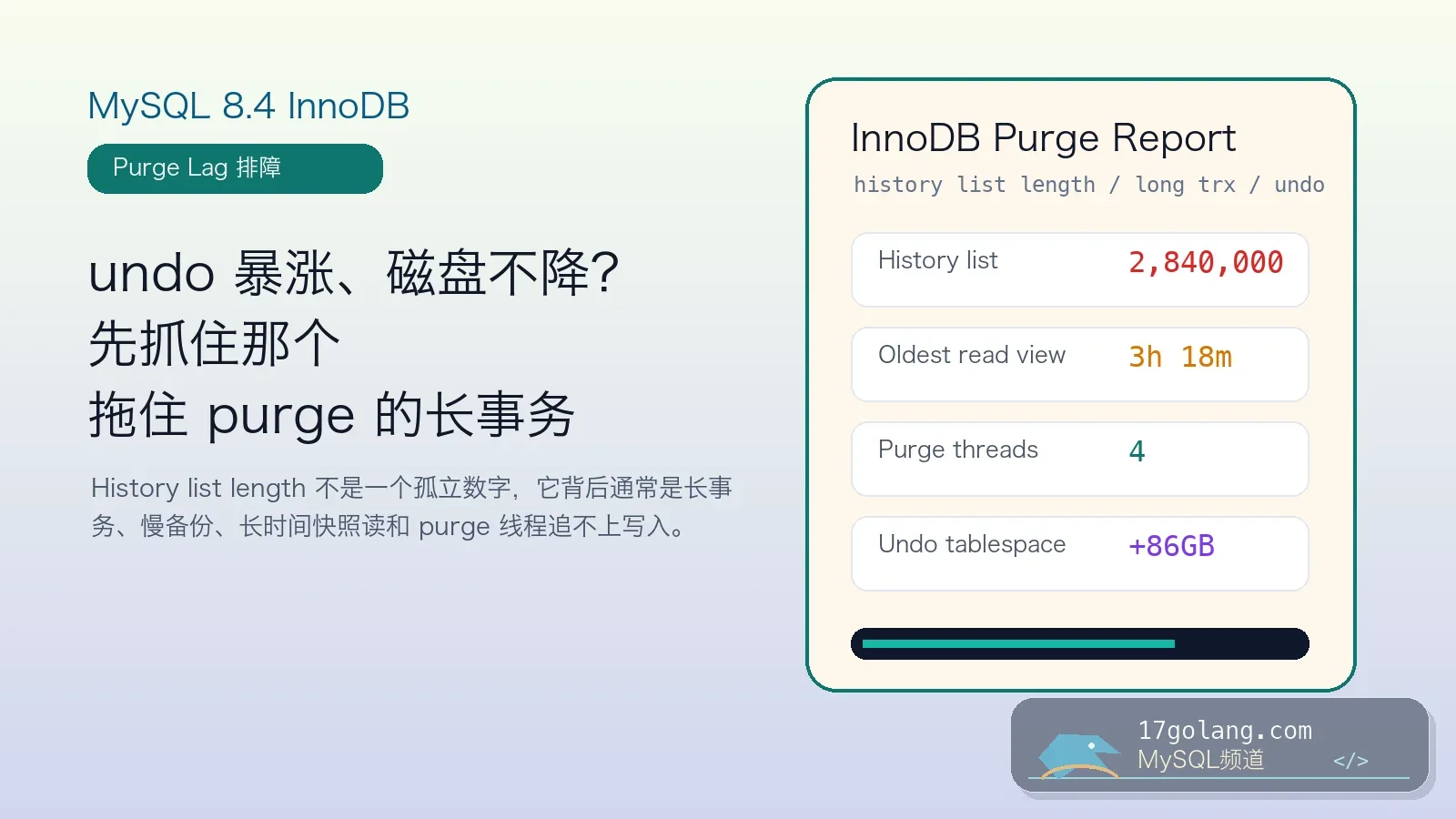 从 MySQL 8.4 InnoDB purge lag 入手,讲清 history list length、长事务、undo 暴涨和 purge 参数的生产排障方法。326 收藏
从 MySQL 8.4 InnoDB purge lag 入手,讲清 history list length、长事务、undo 暴涨和 purge 参数的生产排障方法。326 收藏 -
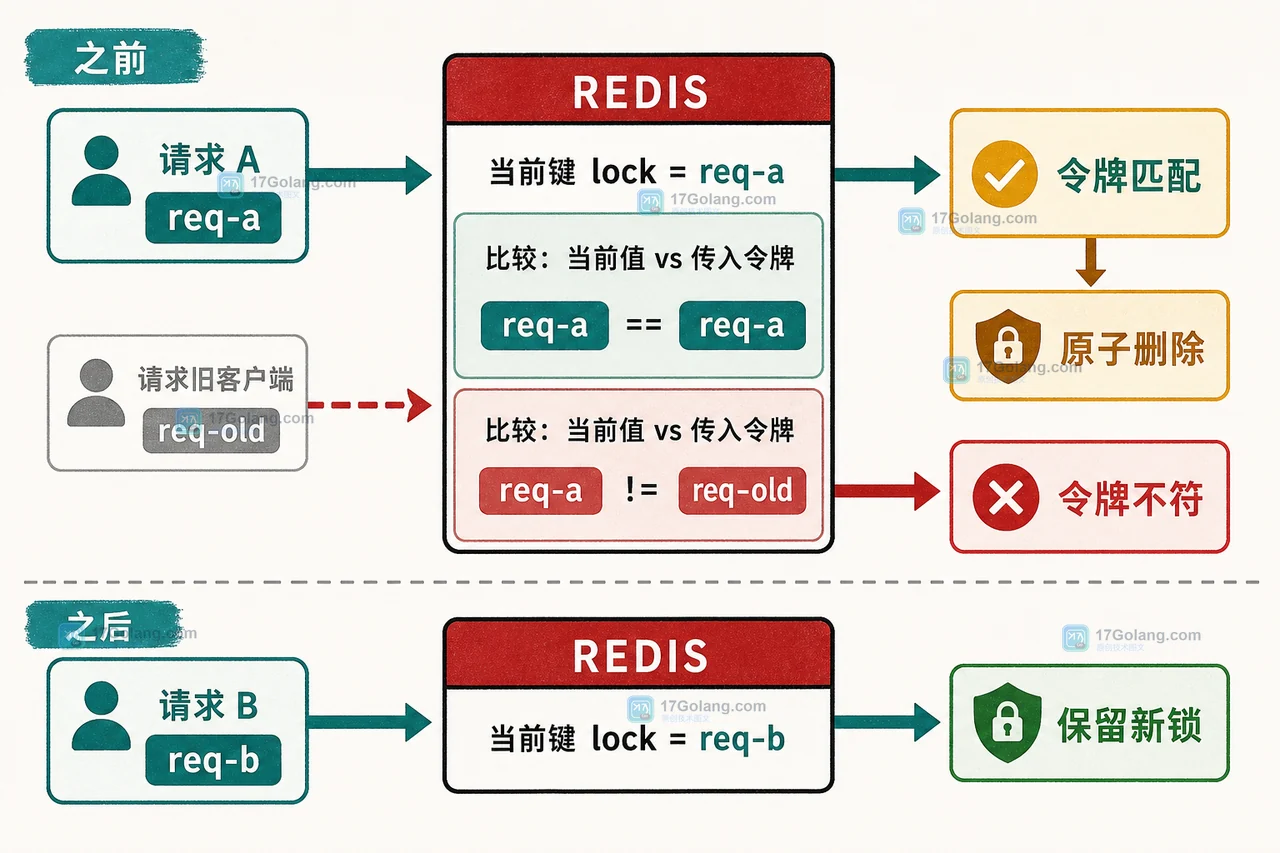 Redis 分布式锁最危险的 bug 不是没加锁,而是释放时删掉了后来持有者的锁。本文从锁过期、业务变慢和重复释放的现场出发,说明唯一令牌如何确认所有权,再用 Redis Lua 脚本把校验与删除放进同一个原子动作,最后补上续期、超时和故障恢复边界。326 收藏
Redis 分布式锁最危险的 bug 不是没加锁,而是释放时删掉了后来持有者的锁。本文从锁过期、业务变慢和重复释放的现场出发,说明唯一令牌如何确认所有权,再用 Redis Lua 脚本把校验与删除放进同一个原子动作,最后补上续期、超时和故障恢复边界。326 收藏 -
数据库 · MySQL | 1个月前 | MySQL教程 · 数据库实战 · 在线DDL · ALTER TABLE · 元数据锁 · mysql innodb MySQL 8 在线 DDL ALTER TABLE MDL 元数据锁 INSTANT
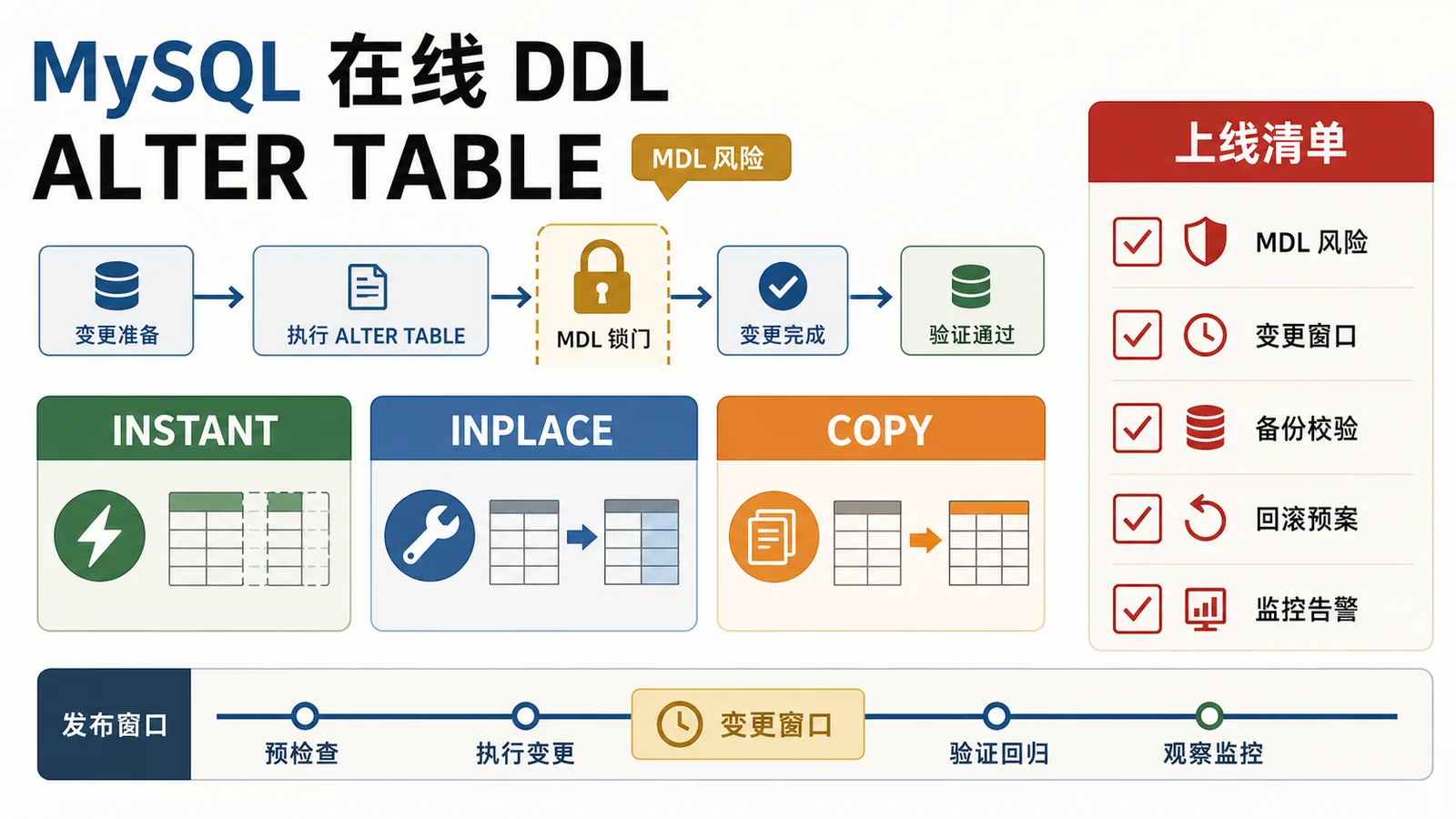 从订单大表加字段出发,讲清 MySQL 8.x 在线 DDL、ALGORITHM=INSTANT/INPLACE/COPY、metadata lock、row version 上限、复制延迟和上线复查。323 收藏
从订单大表加字段出发,讲清 MySQL 8.x 在线 DDL、ALGORITHM=INSTANT/INPLACE/COPY、metadata lock、row version 上限、复制延迟和上线复查。323 收藏 -
 Redis6.0的多线程(io-threads)不参与主从同步,因其复制连接走专用路径,绕过I/O线程调度;真正瓶颈在于RDB生成阻塞、从节点CPU解析、网络带宽及repl-backlog过小导致频繁全量同步。321 收藏
Redis6.0的多线程(io-threads)不参与主从同步,因其复制连接走专用路径,绕过I/O线程调度;真正瓶颈在于RDB生成阻塞、从节点CPU解析、网络带宽及repl-backlog过小导致频繁全量同步。321 收藏 -
 本文按完整工作流讲解 MySQL 慢 SQL 优化:从慢查询日志发现候选 SQL,聚合同类语句,用 EXPLAIN 判断访问方式和扫描行数,再设计联合索引,并通过延迟、扫描行数和业务结果做回归验证。321 收藏
本文按完整工作流讲解 MySQL 慢 SQL 优化:从慢查询日志发现候选 SQL,聚合同类语句,用 EXPLAIN 判断访问方式和扫描行数,再设计联合索引,并通过延迟、扫描行数和业务结果做回归验证。321 收藏 -
 缓存雪崩主因是大量key过期时间高度趋同,需通过扫描TTL、监控expired_keys曲线及检查写入逻辑验证;应采用SETEX或SET...EX原子命令,在基础过期时间上叠加5%–20%随机偏移,并确保所有写入路径(含定时任务、MQ、后台)均覆盖随机化。313 收藏
缓存雪崩主因是大量key过期时间高度趋同,需通过扫描TTL、监控expired_keys曲线及检查写入逻辑验证;应采用SETEX或SET...EX原子命令,在基础过期时间上叠加5%–20%随机偏移,并确保所有写入路径(含定时任务、MQ、后台)均覆盖随机化。313 收藏 -
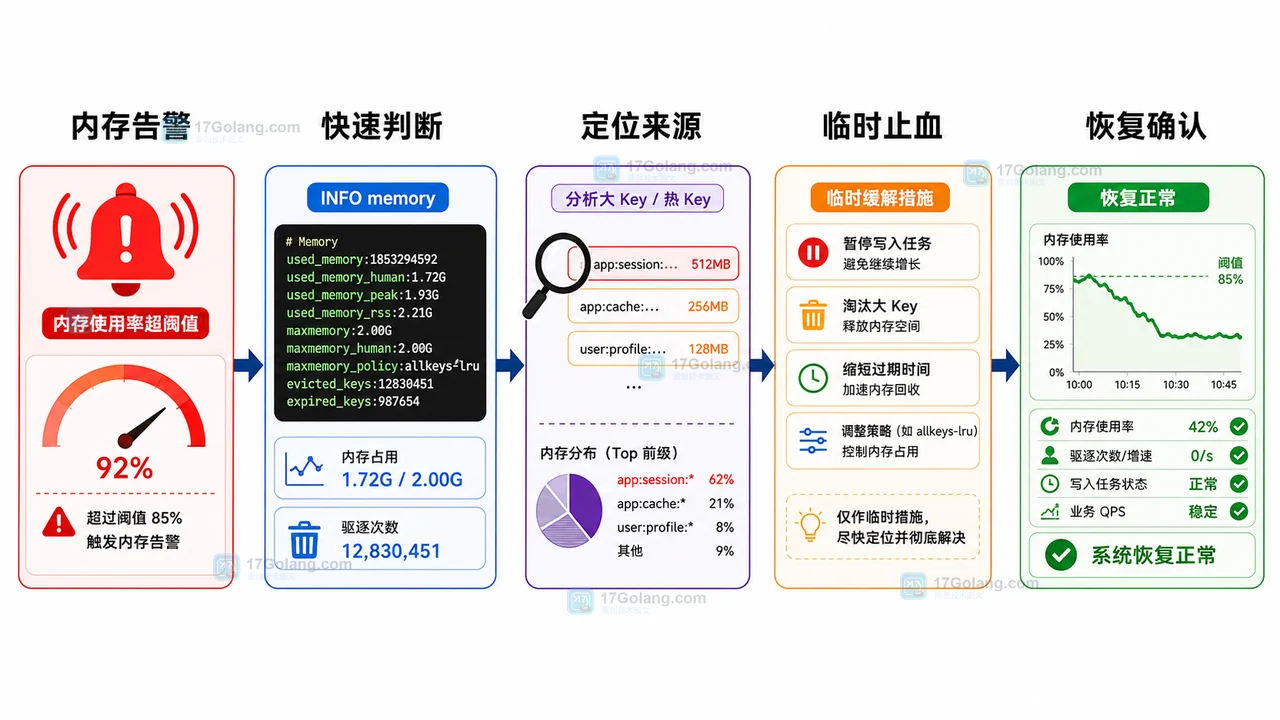 面向线上 Redis 内存告警的运行手册,覆盖触发信号、INFO memory 快速判断、bigkeys 排查、maxmemory 与淘汰策略检查、临时止血、回滚和复盘清单。313 收藏
面向线上 Redis 内存告警的运行手册,覆盖触发信号、INFO memory 快速判断、bigkeys 排查、maxmemory 与淘汰策略检查、临时止血、回滚和复盘清单。313 收藏 -
 replica-priority为0表示从库禁止被选为新主,即使唯一存活也会导致故障转移失败;哨兵依据从库INFOREPLICATION中上报的值决策,而非本地配置。312 收藏
replica-priority为0表示从库禁止被选为新主,即使唯一存活也会导致故障转移失败;哨兵依据从库INFOREPLICATION中上报的值决策,而非本地配置。312 收藏 -
 彻底禁用RDB自动触发需注释或设为save"",重启或CONFIGREWRITE后CONFIGGETsave返回["save",""],且rdb_changes_since_last_save持续增长即生效。311 收藏
彻底禁用RDB自动触发需注释或设为save"",重启或CONFIGREWRITE后CONFIGGETsave返回["save",""],且rdb_changes_since_last_save持续增长即生效。311 收藏 -
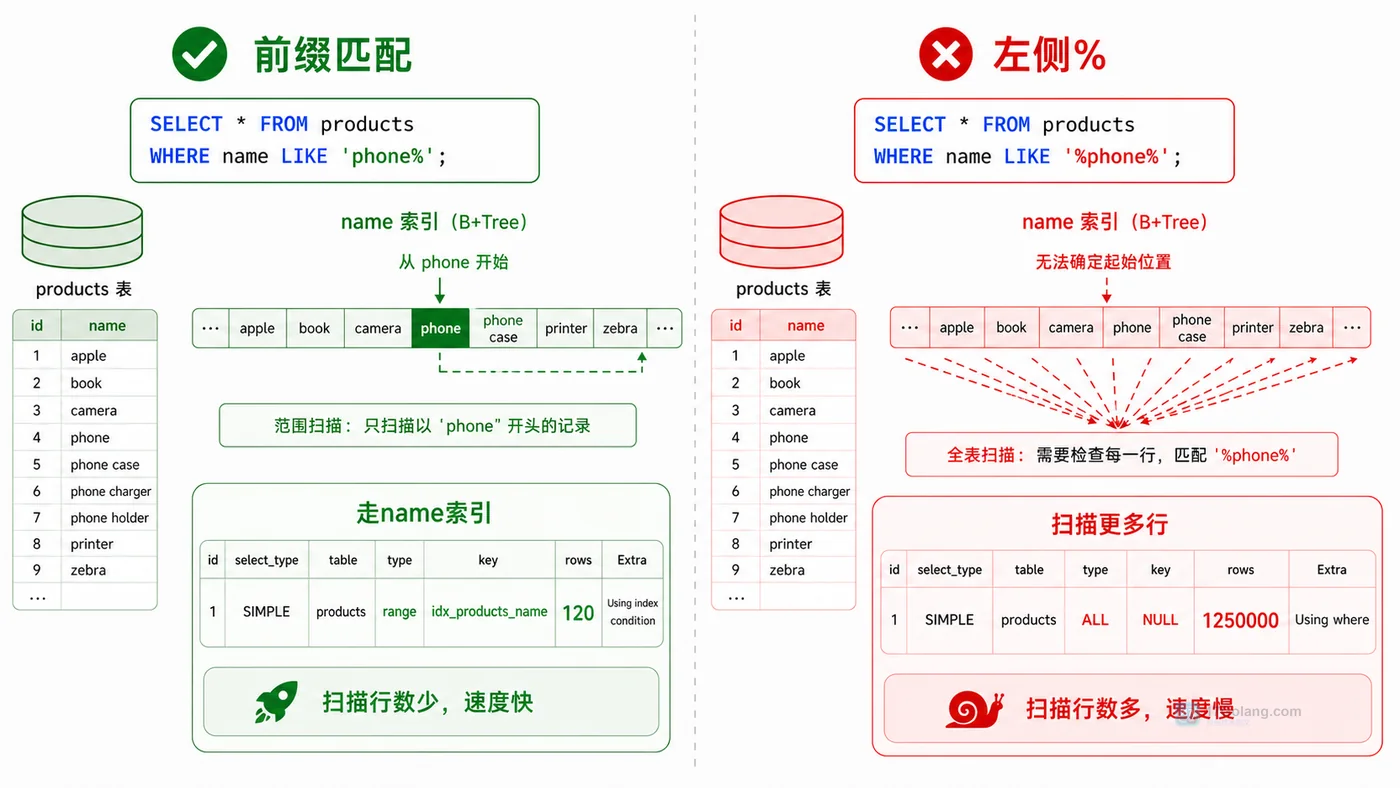 搜索框查询一上线就变慢,很多时候不是数据量突然失控,而是 LIKE 条件写法让索引用不上。本文从慢查询现场开始,逐步验证左通配符、执行计划、前缀匹配和业务改写,整理一套更稳的模糊搜索排查方法。308 收藏
搜索框查询一上线就变慢,很多时候不是数据量突然失控,而是 LIKE 条件写法让索引用不上。本文从慢查询现场开始,逐步验证左通配符、执行计划、前缀匹配和业务改写,整理一套更稳的模糊搜索排查方法。308 收藏 -
 扩容易触发缓存雪崩主因是reshard迁移打破key分布与失效节奏,导致大量key集中过期及请求穿透;须在写入阶段强制采用setex+随机TTL(base_ttl±15%~25%variance),禁用固定TTL与热点key长TTL,迁移期改maxmemory-policy为noeviction,并用--threshold1细粒度迁移。306 收藏
扩容易触发缓存雪崩主因是reshard迁移打破key分布与失效节奏,导致大量key集中过期及请求穿透;须在写入阶段强制采用setex+随机TTL(base_ttl±15%~25%variance),禁用固定TTL与热点key长TTL,迁移期改maxmemory-policy为noeviction,并用--threshold1细粒度迁移。306 收藏 -
 Redis卡顿主因是内存满时同步驱逐bigkey,导致主线程阻塞;应启用lazyfree-lazy-eviction、改DEL为UNLINK、用--bigkeys定位大key,并依访问模式选allkeys-random或allkeys-lfu淘汰策略。306 收藏
Redis卡顿主因是内存满时同步驱逐bigkey,导致主线程阻塞;应启用lazyfree-lazy-eviction、改DEL为UNLINK、用--bigkeys定位大key,并依访问模式选allkeys-random或allkeys-lfu淘汰策略。306 收藏 -
 Redis3.0的evictionpool是一个固定长度为16的数组,用于淘汰前暂存采样键的近似空闲时间和键名,通过多轮随机采样、保序插入与top-K筛选,提升冷热识别鲁棒性,避免单次采样误驱逐热点key。303 收藏
Redis3.0的evictionpool是一个固定长度为16的数组,用于淘汰前暂存采样键的近似空闲时间和键名,通过多轮随机采样、保序插入与top-K筛选,提升冷热识别鲁棒性,避免单次采样误驱逐热点key。303 收藏 -
 哨兵通过“客观下线”(ODOWN)判断主节点真挂了:单个哨兵连不上仅为主观下线(SDOWN),需至少quorum个哨兵达成一致才触发ODOWN;哨兵间用SENTINELis-master-down-by-addr命令确认,非心跳广播,网络分区可能导致结论不一。297 收藏
哨兵通过“客观下线”(ODOWN)判断主节点真挂了:单个哨兵连不上仅为主观下线(SDOWN),需至少quorum个哨兵达成一致才触发ODOWN;哨兵间用SENTINELis-master-down-by-addr命令确认,非心跳广播,网络分区可能导致结论不一。297 收藏