Go语言技术文章
-
数据库 · MySQL | 1天前 | MySQL · 权限管理 · 备份 · mysqldump · 数据库安全 · 最小权限 mysqldump备份账号 MySQL角色 partial_revokes 备份权限
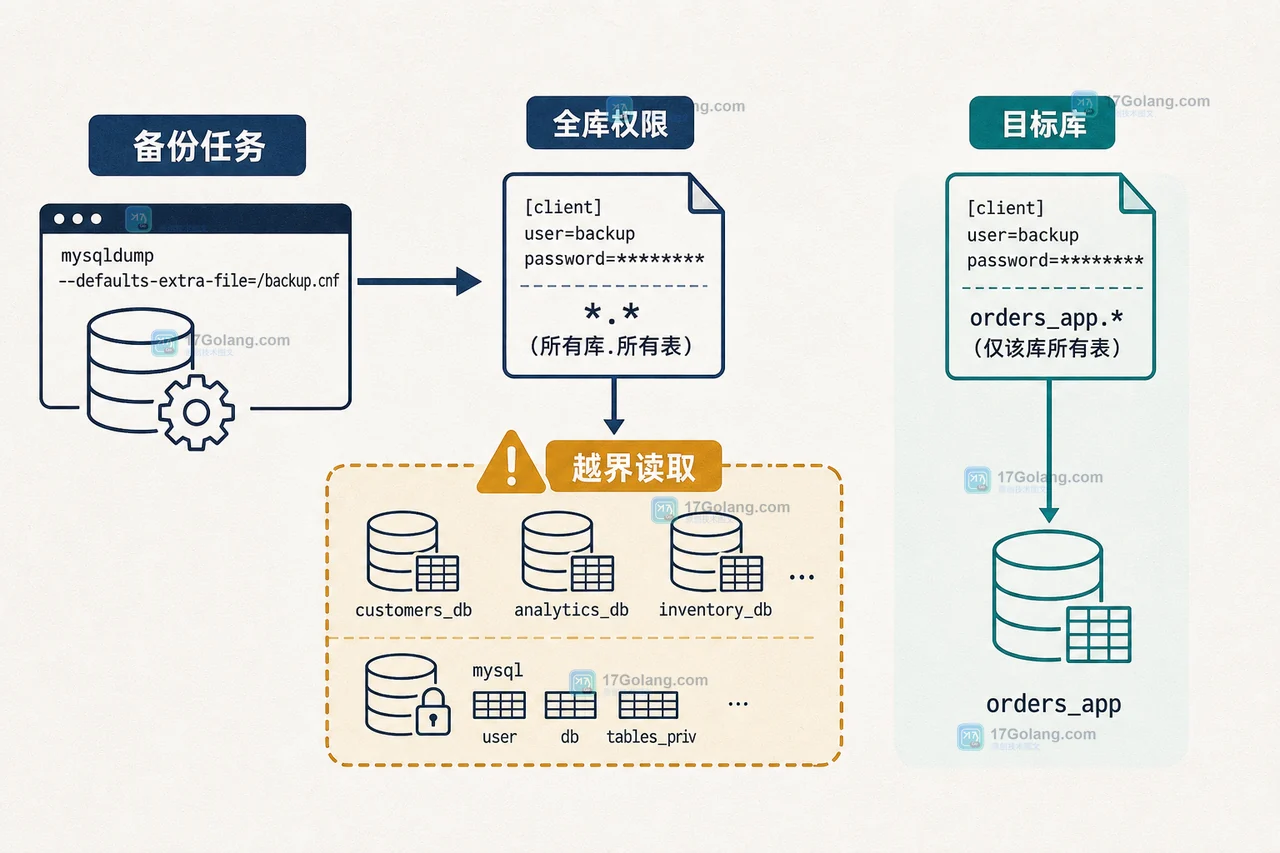 给线上备份任务单独建角色,先用数据库级权限限制范围,再用 partial_revokes 阻断 mysql 系统库访问,最后通过 SHOW GRANTS 和只读验证确认边界。本文用 orders_app 与 audit_db 两个库演示权限收紧、审计检查和回退方法。413 收藏
给线上备份任务单独建角色,先用数据库级权限限制范围,再用 partial_revokes 阻断 mysql 系统库访问,最后通过 SHOW GRANTS 和只读验证确认边界。本文用 orders_app 与 audit_db 两个库演示权限收紧、审计检查和回退方法。413 收藏 -
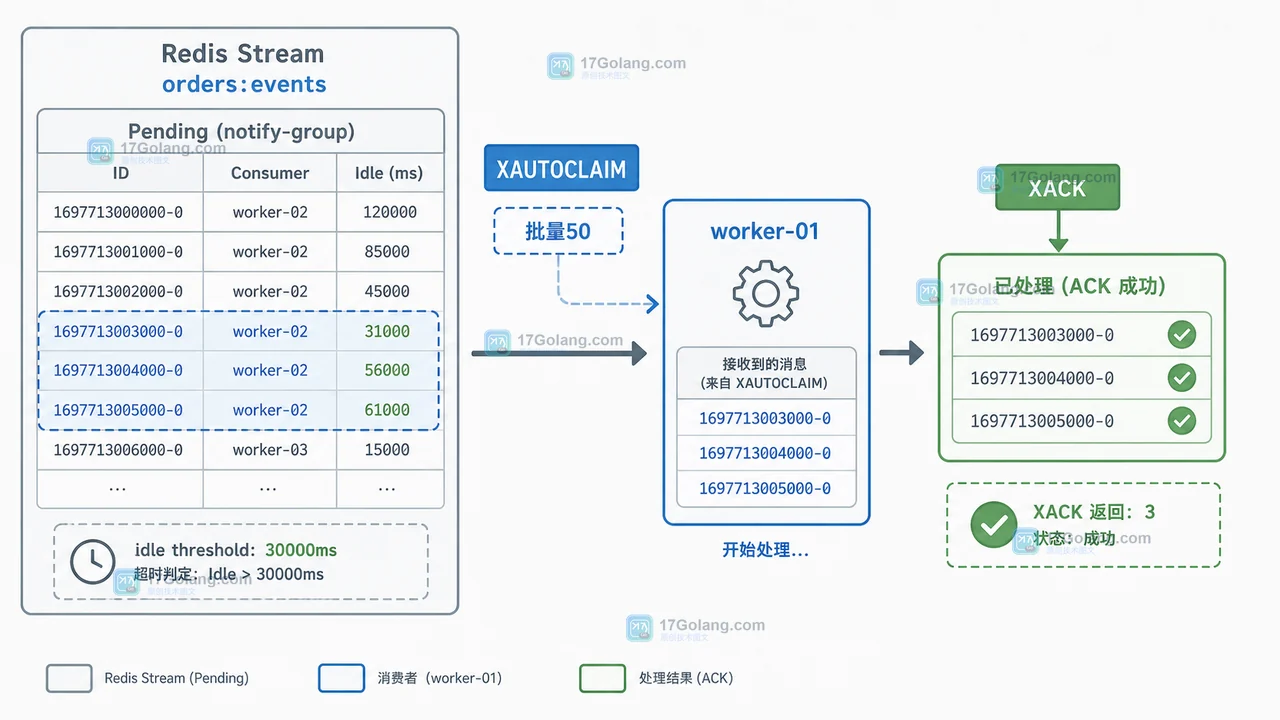 Redis Stream 消费者组出现积压时,先用 XPENDING 区分未分配消息和已分配未确认消息,再按 idle 时间和重试次数决定 XAUTOCLAIM、人工核查还是进入重试队列。本文用可复现的订单事件示例梳理定位、接管与回滚边界。422 收藏
Redis Stream 消费者组出现积压时,先用 XPENDING 区分未分配消息和已分配未确认消息,再按 idle 时间和重试次数决定 XAUTOCLAIM、人工核查还是进入重试队列。本文用可复现的订单事件示例梳理定位、接管与回滚边界。422 收藏 -
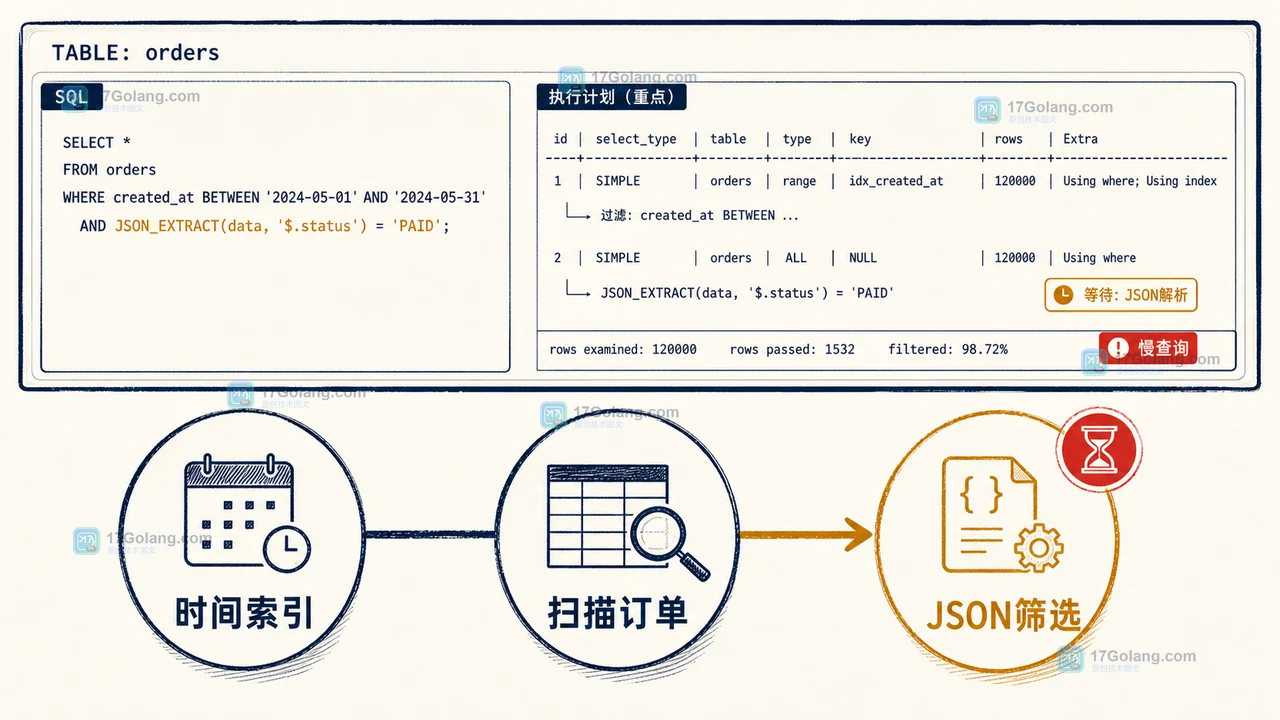 订单表把地区和渠道放在 JSON 字段后,JSON_EXTRACT 条件常常无法直接利用普通索引。本文用一张 orders 表复现慢查询,再通过生成列与联合索引让 EXPLAIN 和实际耗时同时给出可核对的变化。278 收藏
订单表把地区和渠道放在 JSON 字段后,JSON_EXTRACT 条件常常无法直接利用普通索引。本文用一张 orders 表复现慢查询,再通过生成列与联合索引让 EXPLAIN 和实际耗时同时给出可核对的变化。278 收藏 -
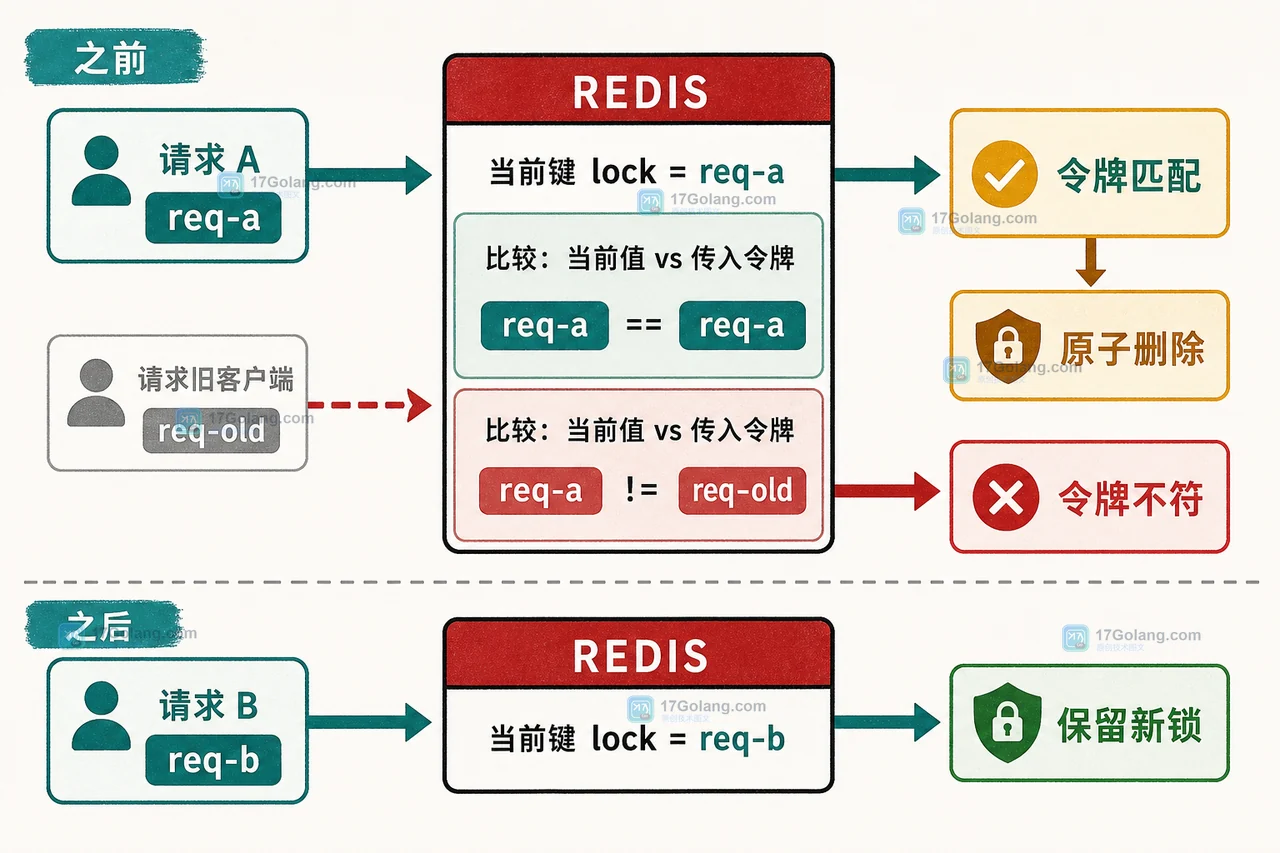 Redis 分布式锁最危险的 bug 不是没加锁,而是释放时删掉了后来持有者的锁。本文从锁过期、业务变慢和重复释放的现场出发,说明唯一令牌如何确认所有权,再用 Redis Lua 脚本把校验与删除放进同一个原子动作,最后补上续期、超时和故障恢复边界。326 收藏
Redis 分布式锁最危险的 bug 不是没加锁,而是释放时删掉了后来持有者的锁。本文从锁过期、业务变慢和重复释放的现场出发,说明唯一令牌如何确认所有权,再用 Redis Lua 脚本把校验与删除放进同一个原子动作,最后补上续期、超时和故障恢复边界。326 收藏 -
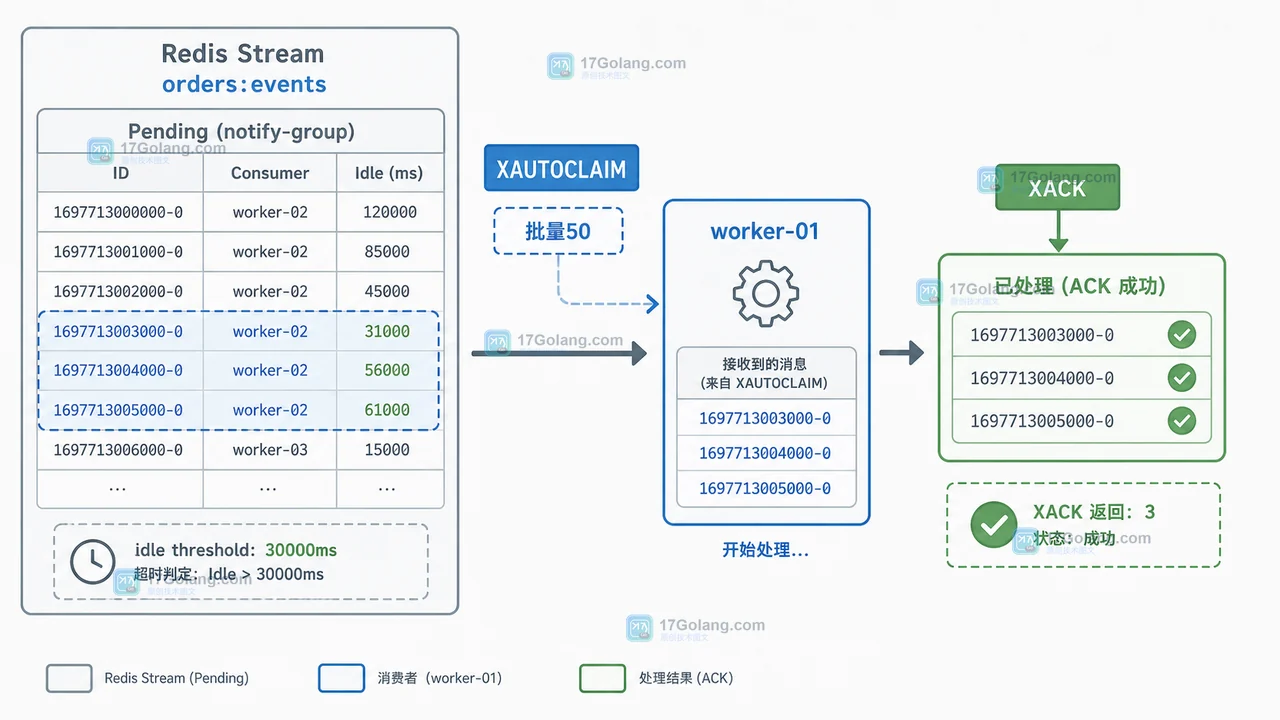 Redis Stream 消费组出现 pending 积压时,先用 XPENDING 看数量和空闲时间,再用 XAUTOCLAIM 接管超时消息,最后通过幂等、分批和回滚把积压安全排空。494 收藏
Redis Stream 消费组出现 pending 积压时,先用 XPENDING 看数量和空闲时间,再用 XAUTOCLAIM 接管超时消息,最后通过幂等、分批和回滚把积压安全排空。494 收藏 -
数据库 · MySQL | 2天前 | MySQL · JSON · 索引 · 数据库 · 查询优化 · 生成列 · json_extract 索引优化 列表筛选 生成列 MySQL JSON JSON索引
 订单列表把渠道、会员等级放进 JSON 后,筛选条件容易变成逐行计算。本文用 MySQL 生成列和索引把 JSON 路径变成可核对的查询字段,同时处理缺失键、空字符串、类型转换和写入成本。351 收藏
订单列表把渠道、会员等级放进 JSON 后,筛选条件容易变成逐行计算。本文用 MySQL 生成列和索引把 JSON 路径变成可核对的查询字段,同时处理缺失键、空字符串、类型转换和写入成本。351 收藏 -
数据库 · Redis | 2天前 | Redis · 缓存 · 限流 · Redis 8.8 · INCREX · Redis 8.8 INCREX Redis窗口限流 Redis计数器 ENX UBOUND
 Redis 8.8 新增 INCREX,把计数、上限和过期时间放进一个原子命令。文章用 redis-cli 演示 60 秒窗口限流,解释 UBOUND、ENX、SATURATE 的差别,并给出旧版本回退方案与检查边界。123 收藏
Redis 8.8 新增 INCREX,把计数、上限和过期时间放进一个原子命令。文章用 redis-cli 演示 60 秒窗口限流,解释 UBOUND、ENX、SATURATE 的差别,并给出旧版本回退方案与检查边界。123 收藏 -
数据库 · MySQL | 3天前 | MySQL · 认证 · MySQL 8.4 · 数据库升级 · caching_sha2_password mysql_native_password 账号认证 MySQL 8.4 升级迁移
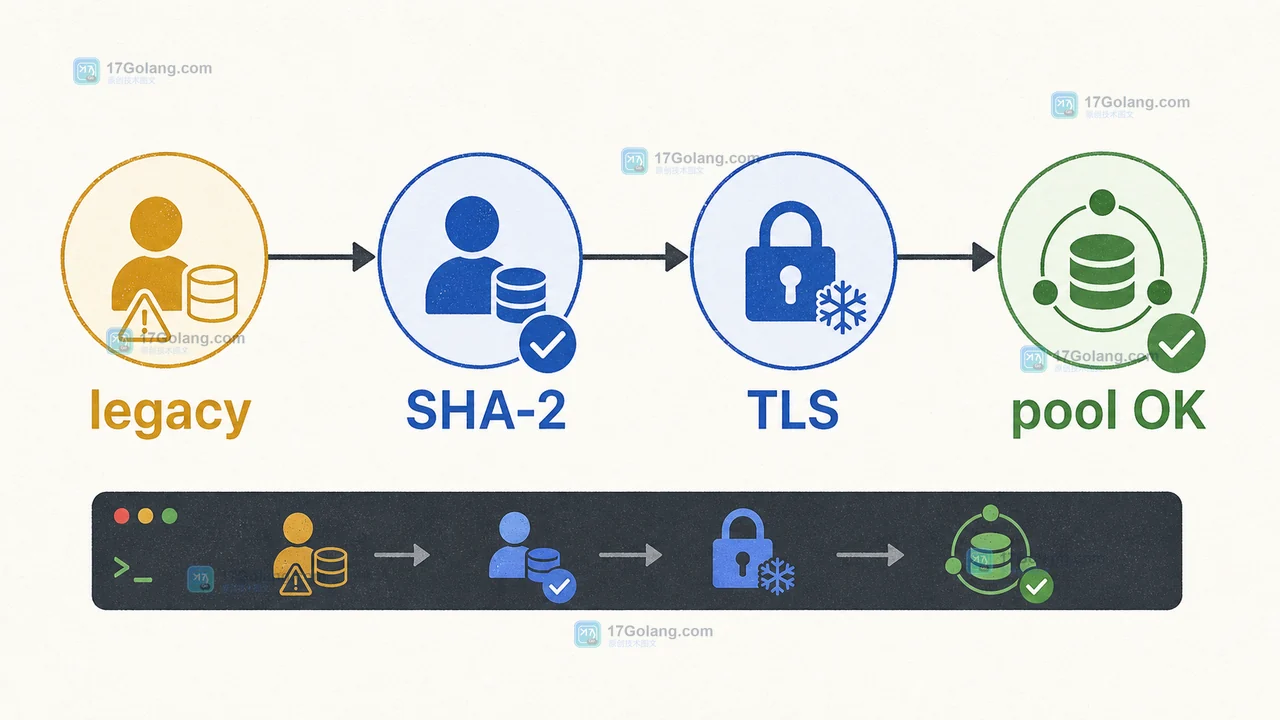 MySQL 8.4 默认不再启用 mysql_native_password,老应用可能在发版后出现账号认证失败。本文用账号盘点、灰度改造、TLS 连通性检查和回退边界,讲清迁移到 caching_sha2_password 的可靠做法。236 收藏
MySQL 8.4 默认不再启用 mysql_native_password,老应用可能在发版后出现账号认证失败。本文用账号盘点、灰度改造、TLS 连通性检查和回退边界,讲清迁移到 caching_sha2_password 的可靠做法。236 收藏 -
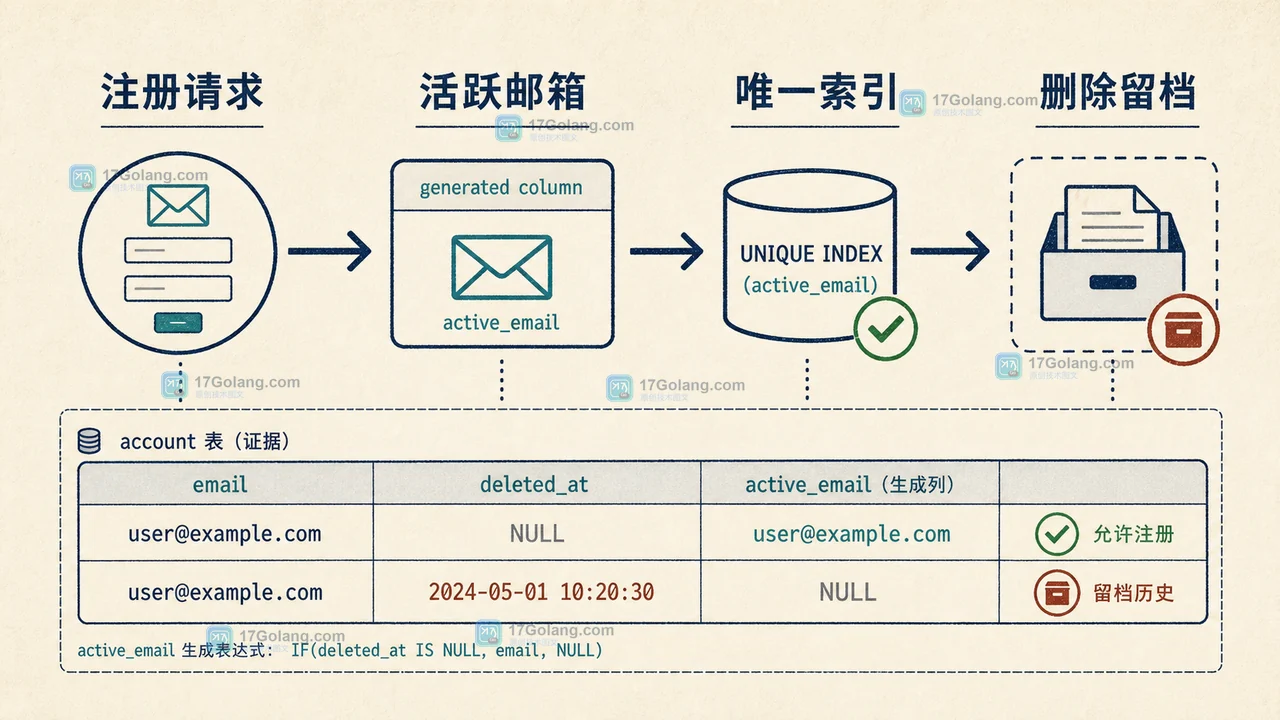 账号表用了软删除后,旧用户数据需要保留,新用户却可能再次使用同一邮箱。本文从真实注册冲突现场出发,说明复合唯一索引为何失效,以及如何用生成列把活跃账号约束、删除留档和恢复校验收进一条稳定的数据链路。471 收藏
账号表用了软删除后,旧用户数据需要保留,新用户却可能再次使用同一邮箱。本文从真实注册冲突现场出发,说明复合唯一索引为何失效,以及如何用生成列把活跃账号约束、删除留档和恢复校验收进一条稳定的数据链路。471 收藏 -
数据库 · Redis | 4天前 | Redis · 缓存 · go · Redis Cluster · 排错 · Redis Cluster CROSSSLOT Hash Tag MGET CLUSTER KEYSLOT
 商品详情页把库存、价格和活动状态合成一次 MGET 后,在 Redis Cluster 里突然报 CROSSSLOT,根因往往不是客户端,而是同一业务实体的 Key 没有落到同一个槽位。本文用 CLUSTER KEYSLOT、Hash Tag 和迁移期检查拆出一条可复查的修复路径。259 收藏
商品详情页把库存、价格和活动状态合成一次 MGET 后,在 Redis Cluster 里突然报 CROSSSLOT,根因往往不是客户端,而是同一业务实体的 Key 没有落到同一个槽位。本文用 CLUSTER KEYSLOT、Hash Tag 和迁移期检查拆出一条可复查的修复路径。259 收藏 -
 线上 Redis 里堆积了过期业务前缀或历史缓存时,不能直接用 KEYS 和 DEL 硬删。用 SCAN 分批遍历、先记录样本、按速率提交 UNLINK,并保留停止开关和统计结果,能把清理风险压到可控范围。183 收藏
线上 Redis 里堆积了过期业务前缀或历史缓存时,不能直接用 KEYS 和 DEL 硬删。用 SCAN 分批遍历、先记录样本、按速率提交 UNLINK,并保留停止开关和统计结果,能把清理风险压到可控范围。183 收藏 -
 热点商品详情被每个接口实例重复读取时,可以用 Redis 的 CLIENT TRACKING 把副本留在进程内存,同时接收键变更失效消息。文章给出 BCAST 前缀划分、失效处理和断线回收的实战流程。413 收藏
热点商品详情被每个接口实例重复读取时,可以用 Redis 的 CLIENT TRACKING 把副本留在进程内存,同时接收键变更失效消息。文章给出 BCAST 前缀划分、失效处理和断线回收的实战流程。413 收藏 -
数据库 · MySQL | 5天前 | MySQL · 数据库 · SQL · ON DUPLICATE KEY UPDATE · VALUES · 行别名 · MySQL VALUES() 弃用 ON DUPLICATE KEY UPDATE MySQL 行别名 INSERT AS new MySQL upsert INSERT SELECT
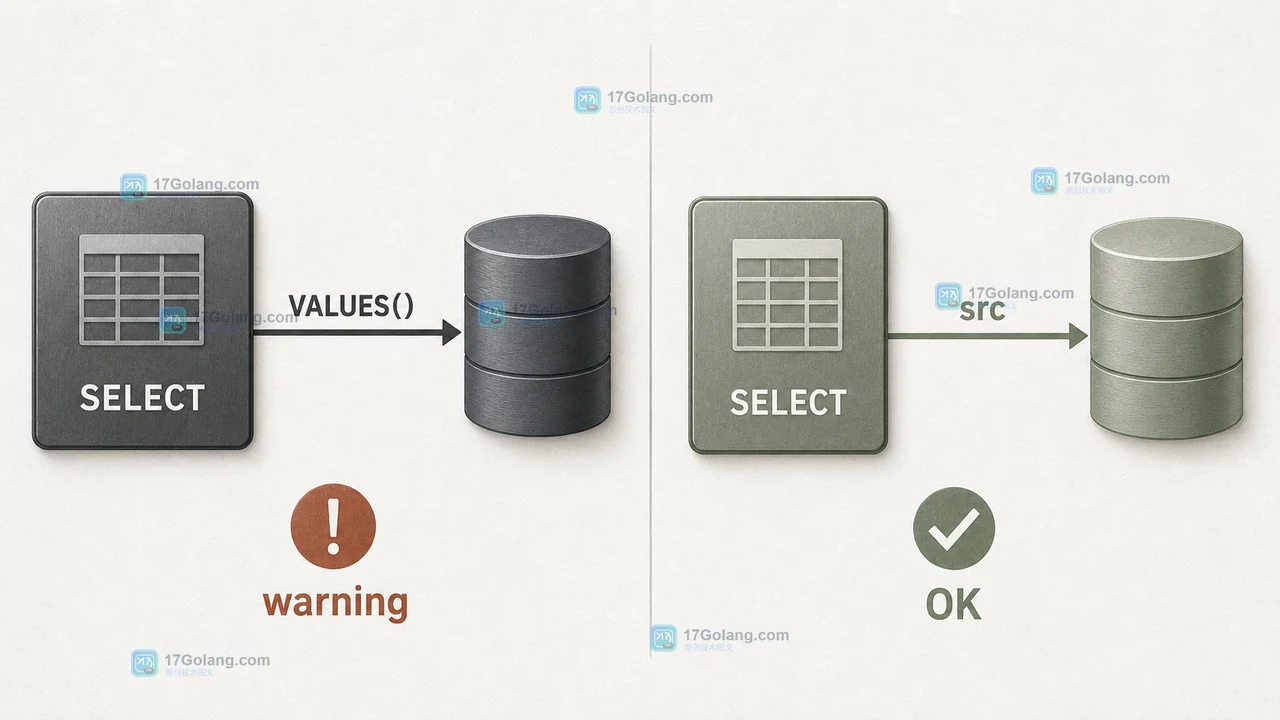 MySQL 已将 ON DUPLICATE KEY UPDATE 中用 VALUES() 读取新行字段的写法标记为弃用。本文从库存快照写入场景出发,给出行别名 AS new 的最小改写、INSERT ... SELECT 的不同处理方式,以及上线前应核对的兼容边界。117 收藏
MySQL 已将 ON DUPLICATE KEY UPDATE 中用 VALUES() 读取新行字段的写法标记为弃用。本文从库存快照写入场景出发,给出行别名 AS new 的最小改写、INSERT ... SELECT 的不同处理方式,以及上线前应核对的兼容边界。117 收藏 -
数据库 · MySQL | 6天前 | MySQL · 索引 · limit · explain · sql优化 · ORDER BY · mysql order by explain limit 复合索引 filesort
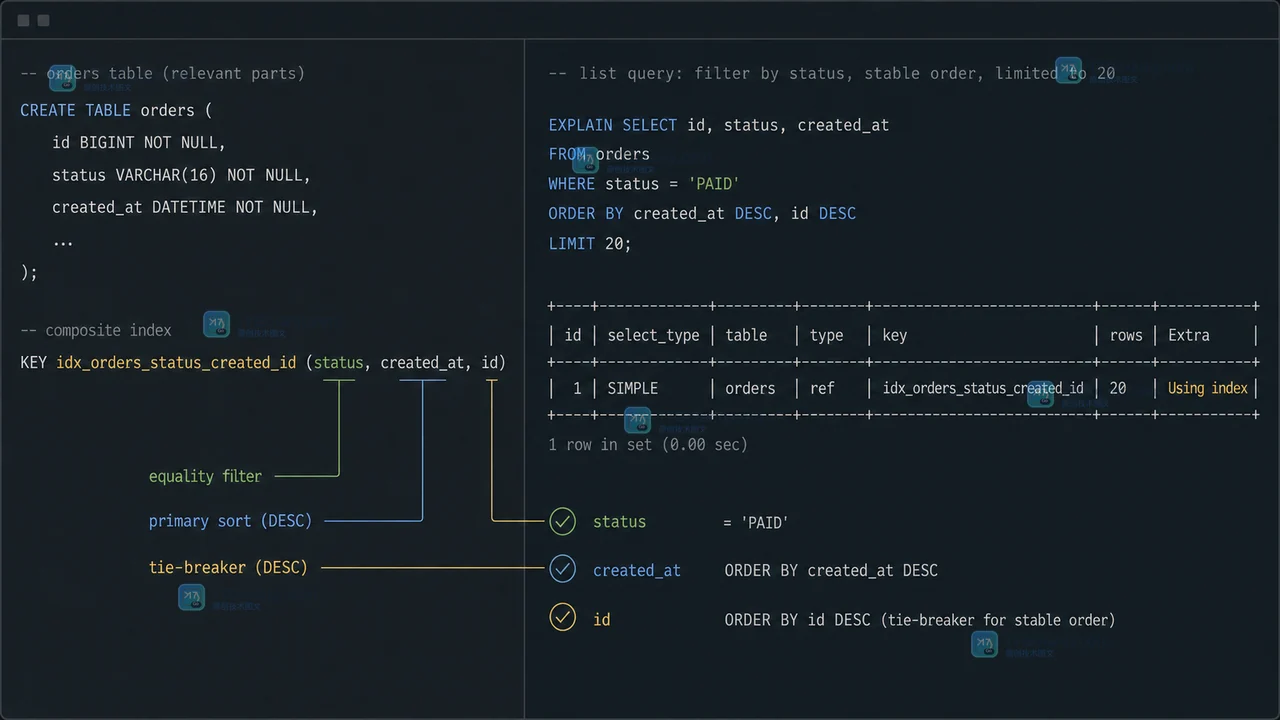 一条只取 20 行的订单查询,EXPLAIN 却可能放弃看似更贴近 WHERE 条件的索引,改走排序索引并在途中筛选。原因是 LIMIT 同时改变了排序、过滤和回表的成本取舍。通过读懂 key、rows 和 Extra,给等值条件与排序字段设计复合索引,再用受控对比核实实际读行,才能避免把 filesort 或某个索引名称当成唯一结论。279 收藏
一条只取 20 行的订单查询,EXPLAIN 却可能放弃看似更贴近 WHERE 条件的索引,改走排序索引并在途中筛选。原因是 LIMIT 同时改变了排序、过滤和回表的成本取舍。通过读懂 key、rows 和 Extra,给等值条件与排序字段设计复合索引,再用受控对比核实实际读行,才能避免把 filesort 或某个索引名称当成唯一结论。279 收藏 -
数据库 · Redis | 6天前 | Redis · 安全配置 · 数据库运维 · ACL · 网络隔离 · Redis公网暴露 Redis protected-mode Redis ACL Redis安全配置 Redis审计
 Redis 被直接暴露在公网,靠一个密码或 protected-mode 都不够。更稳妥的方案是让端口只对可信应用网络开放,再用 ACL 分配最小命令和 key 权限、启用所需的传输保护并保留配置审计。本文按 Redis 官方安全文档梳理风险和可验证的检查顺序。364 收藏
Redis 被直接暴露在公网,靠一个密码或 protected-mode 都不够。更稳妥的方案是让端口只对可信应用网络开放,再用 ACL 分配最小命令和 key 权限、启用所需的传输保护并保留配置审计。本文按 Redis 官方安全文档梳理风险和可验证的检查顺序。364 收藏