Go语言技术文章
-
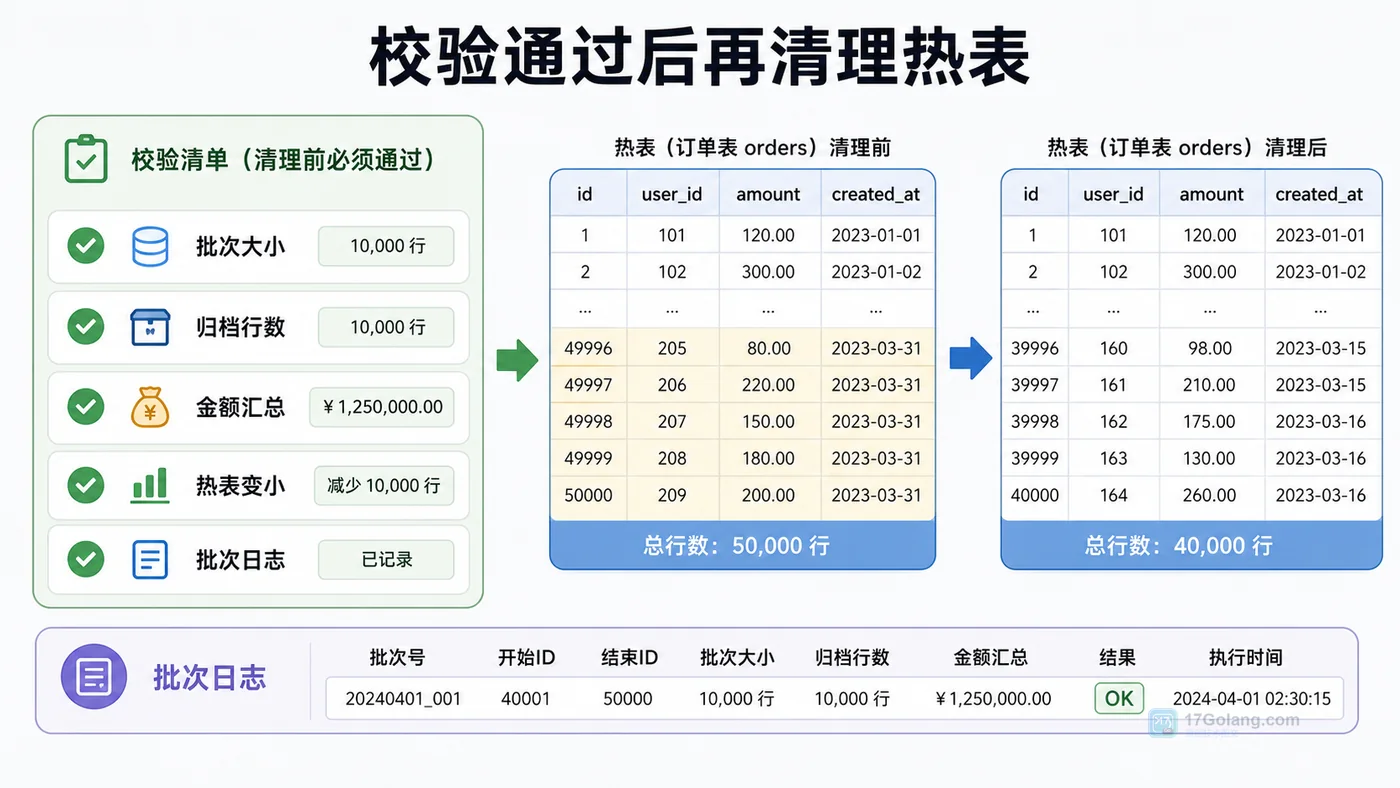 本文用订单表归档为例,讲清 MySQL 历史数据如何按时间窗口分批搬迁:先确定归档边界,再批量写入归档表,校验数量和金额,最后小批量清理热表,降低锁等待和慢查询风险。261 收藏
本文用订单表归档为例,讲清 MySQL 历史数据如何按时间窗口分批搬迁:先确定归档边界,再批量写入归档表,校验数量和金额,最后小批量清理热表,降低锁等待和慢查询风险。261 收藏 -
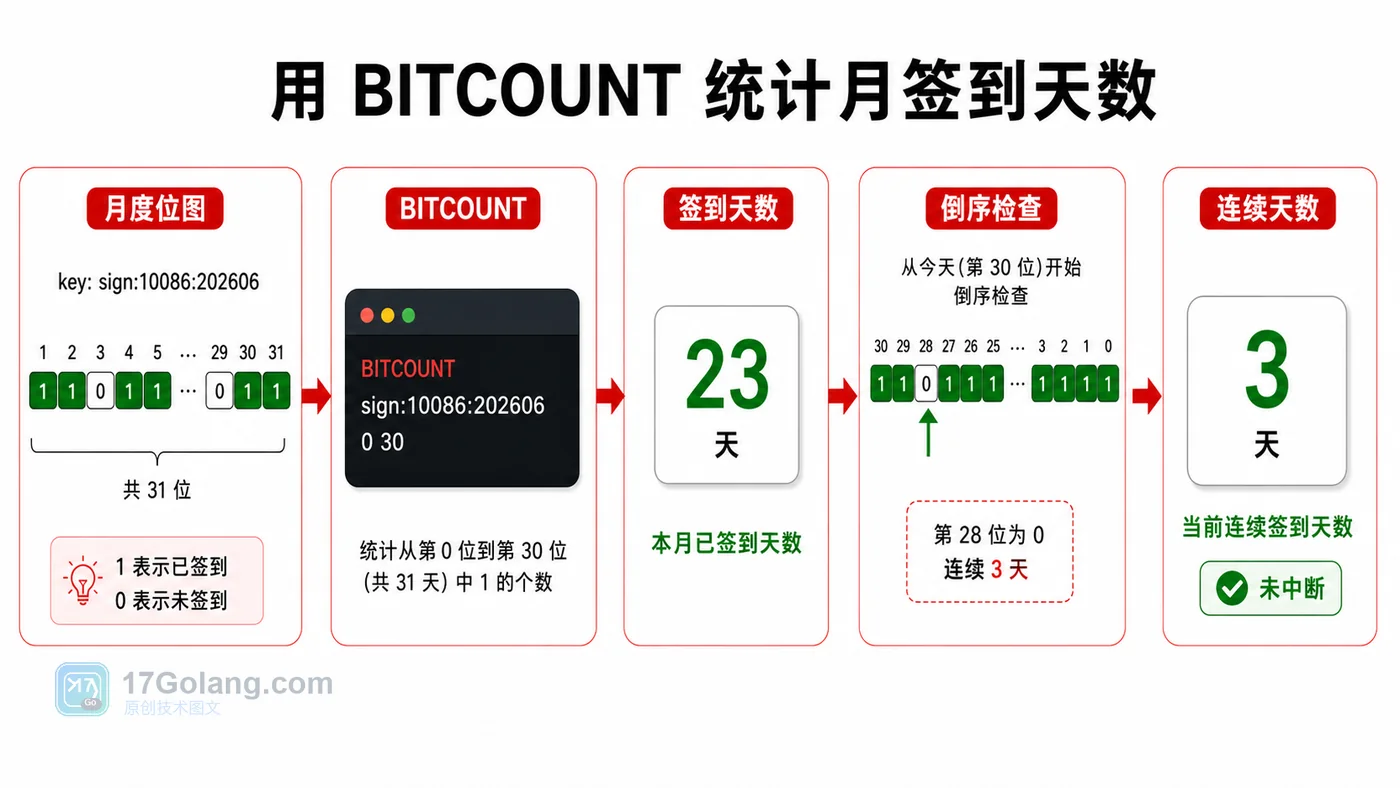 本文用 Redis Bitmap 实现用户签到:用 SETBIT 写入每天状态,用 GETBIT 查询当天是否签到,用 BITCOUNT 快速统计月签到天数,并补充连续签到和键设计建议。464 收藏
本文用 Redis Bitmap 实现用户签到:用 SETBIT 写入每天状态,用 GETBIT 查询当天是否签到,用 BITCOUNT 快速统计月签到天数,并补充连续签到和键设计建议。464 收藏 -
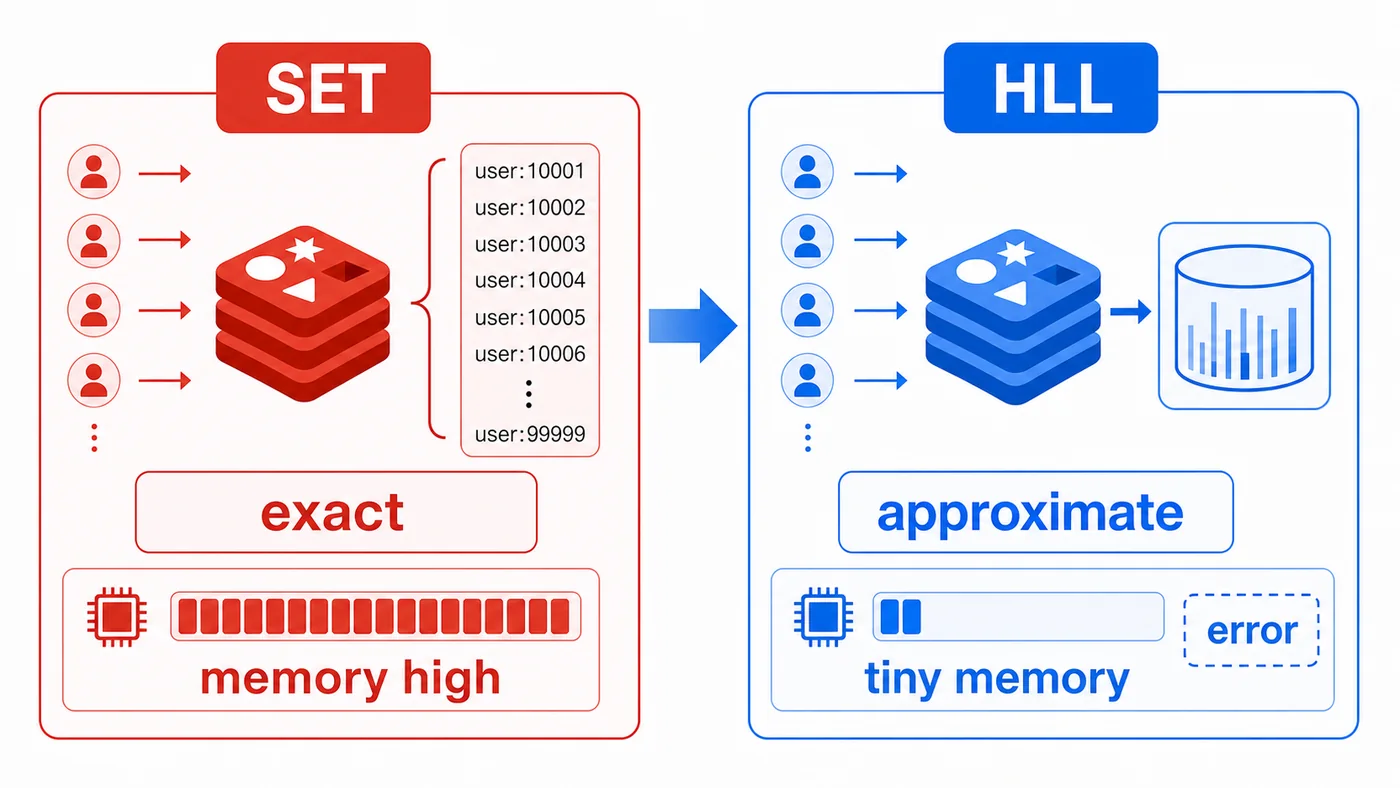 用 Redis HyperLogLog 做站点 UV 统计:通过 PFADD 写入用户标识,用 PFCOUNT 读取近似去重人数,对比 Set 精确去重的内存成本,并说明适用场景和误差边界。180 收藏
用 Redis HyperLogLog 做站点 UV 统计:通过 PFADD 写入用户标识,用 PFCOUNT 读取近似去重人数,对比 Set 精确去重的内存成本,并说明适用场景和误差边界。180 收藏 -
数据库 · Redis | 1个月前 | Redis · 消息队列 · Stream · 消费组 · redis 消息队列 Redis Stream 消费组 XREADGROUP XACK XPENDING XAUTOCLAIM
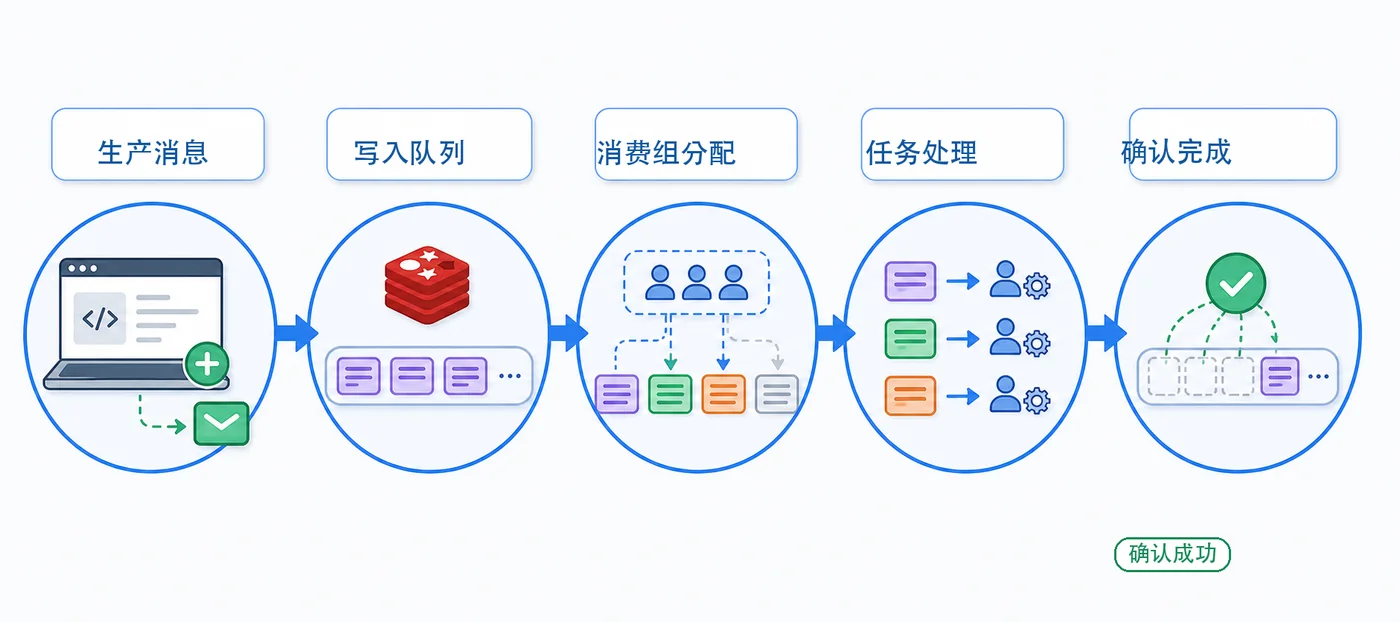 用订单异步处理场景讲清楚 Redis Stream 的实用队列模型:生产者写入消息,消费组分配任务,Worker 处理成功后 ACK,失败或超时的消息进入待确认列表,再通过 XPENDING 和 XAUTOCLAIM 做重投。187 收藏
用订单异步处理场景讲清楚 Redis Stream 的实用队列模型:生产者写入消息,消费组分配任务,Worker 处理成功后 ACK,失败或超时的消息进入待确认列表,再通过 XPENDING 和 XAUTOCLAIM 做重投。187 收藏 -
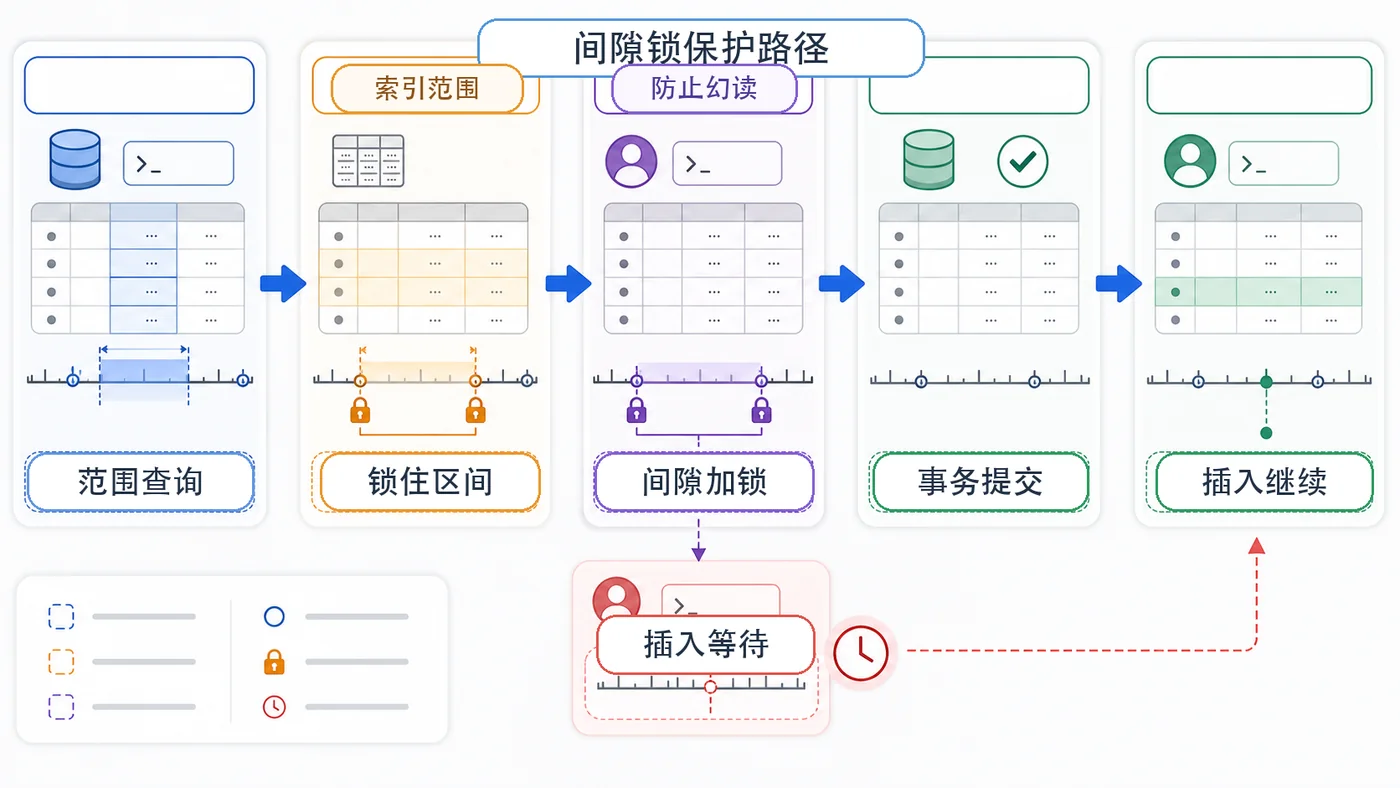 本文用两个 MySQL 会话复现可重复读和幻读场景,解释快照读、当前读、范围查询和间隙锁的关系,帮助排查线上并发写入问题。455 收藏
本文用两个 MySQL 会话复现可重复读和幻读场景,解释快照读、当前读、范围查询和间隙锁的关系,帮助排查线上并发写入问题。455 收藏 -
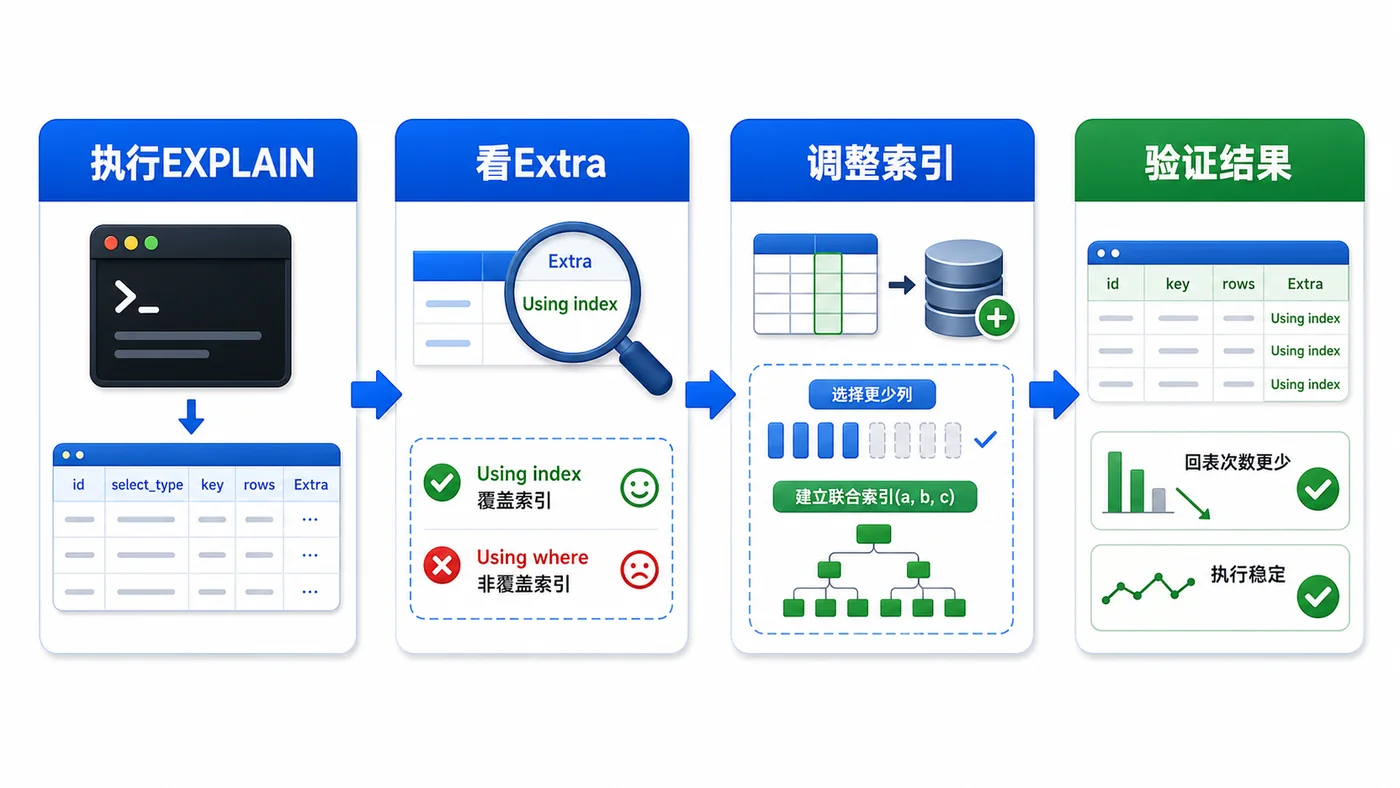 本文用订单列表查询场景,演示普通二级索引为什么需要回表,以及如何通过覆盖索引减少回表,并用 EXPLAIN 的 Extra 验证优化结果。381 收藏
本文用订单列表查询场景,演示普通二级索引为什么需要回表,以及如何通过覆盖索引减少回表,并用 EXPLAIN 的 Extra 验证优化结果。381 收藏 -
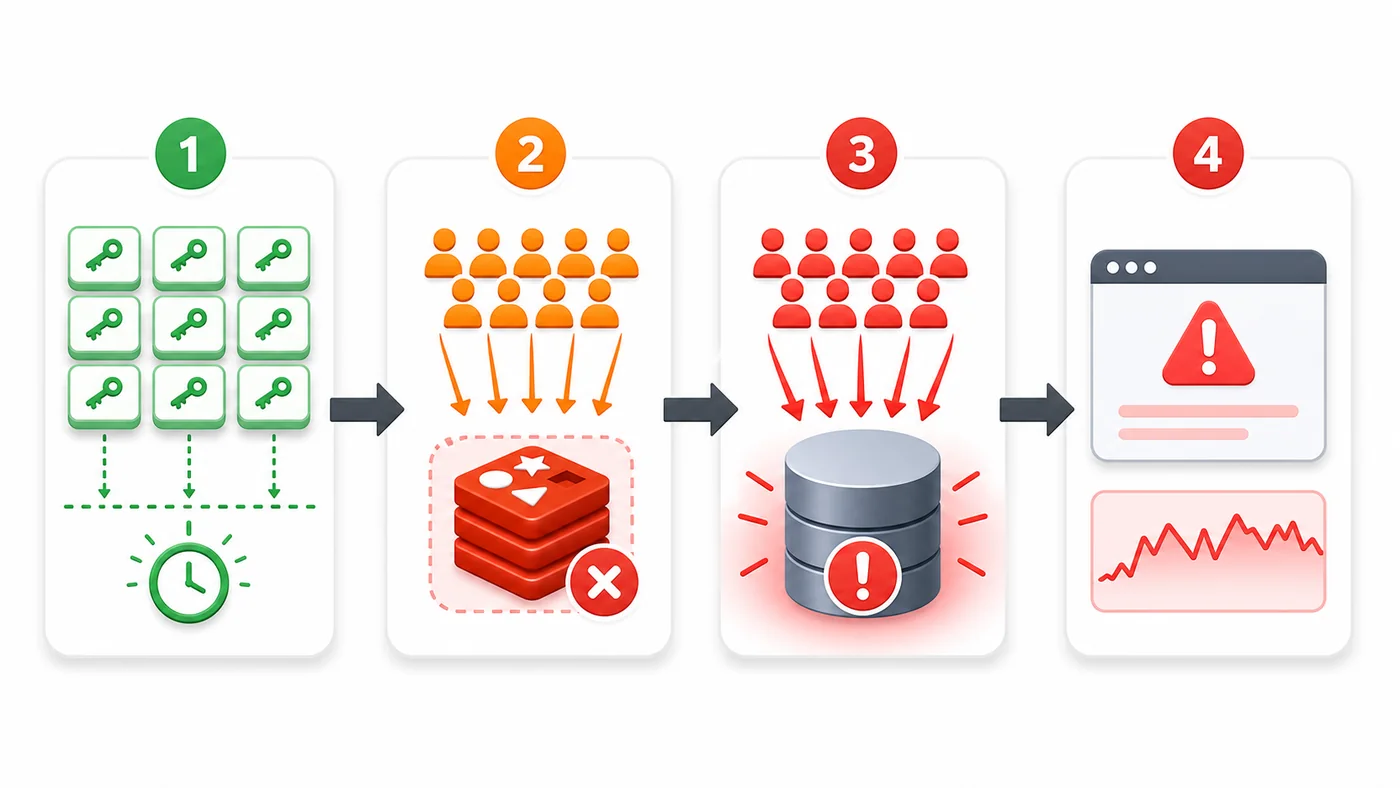 本文用商品详情缓存同时过期的场景,演示 Redis 缓存雪崩的形成过程,并给出 TTL 抖动、热点预热、互斥重建和降级保护的落地方案。139 收藏
本文用商品详情缓存同时过期的场景,演示 Redis 缓存雪崩的形成过程,并给出 TTL 抖动、热点预热、互斥重建和降级保护的落地方案。139 收藏 -
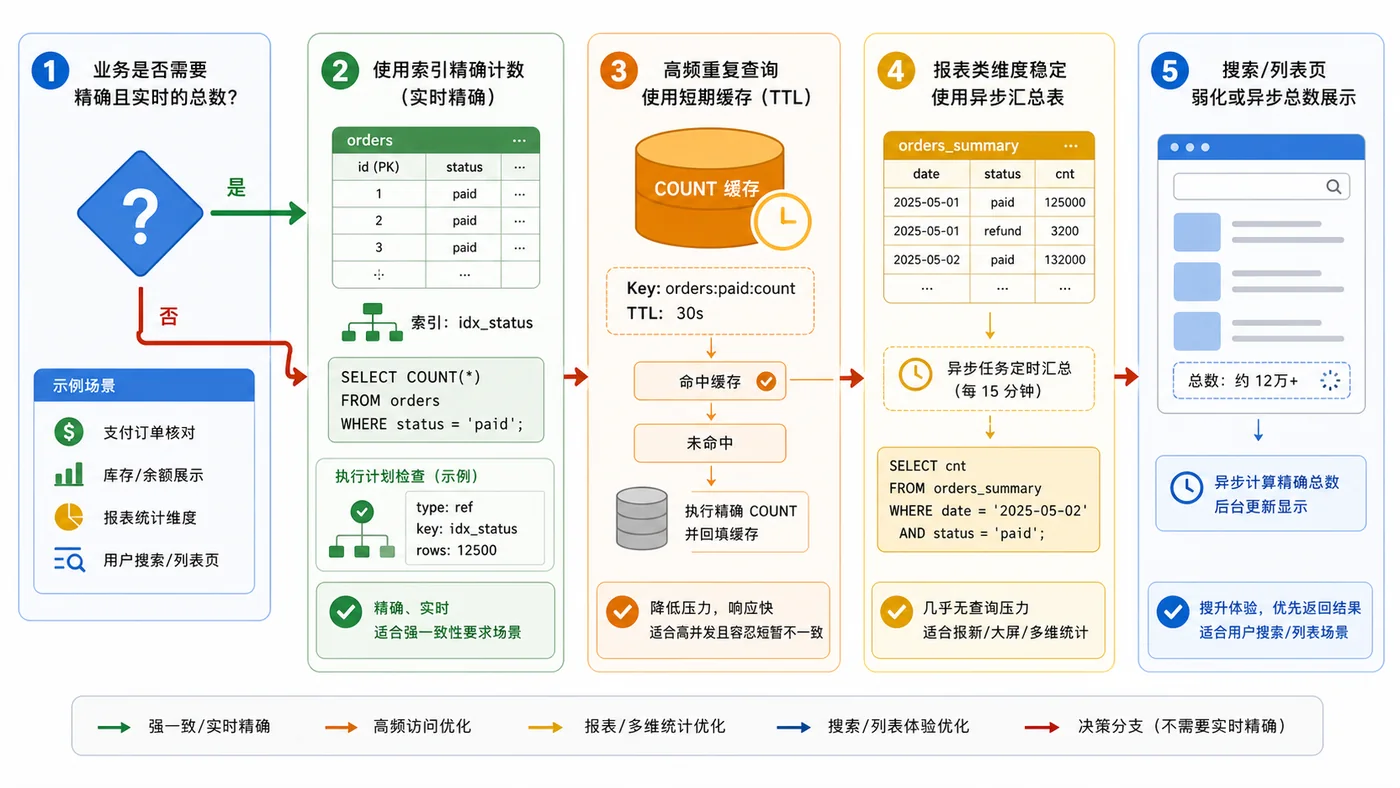 本文用后台订单列表总数统计场景,演示为什么大表每次 COUNT 会拖慢接口,并按精确总数、条件筛选、缓存和汇总表给出优化方案。336 收藏
本文用后台订单列表总数统计场景,演示为什么大表每次 COUNT 会拖慢接口,并按精确总数、条件筛选、缓存和汇总表给出优化方案。336 收藏 -
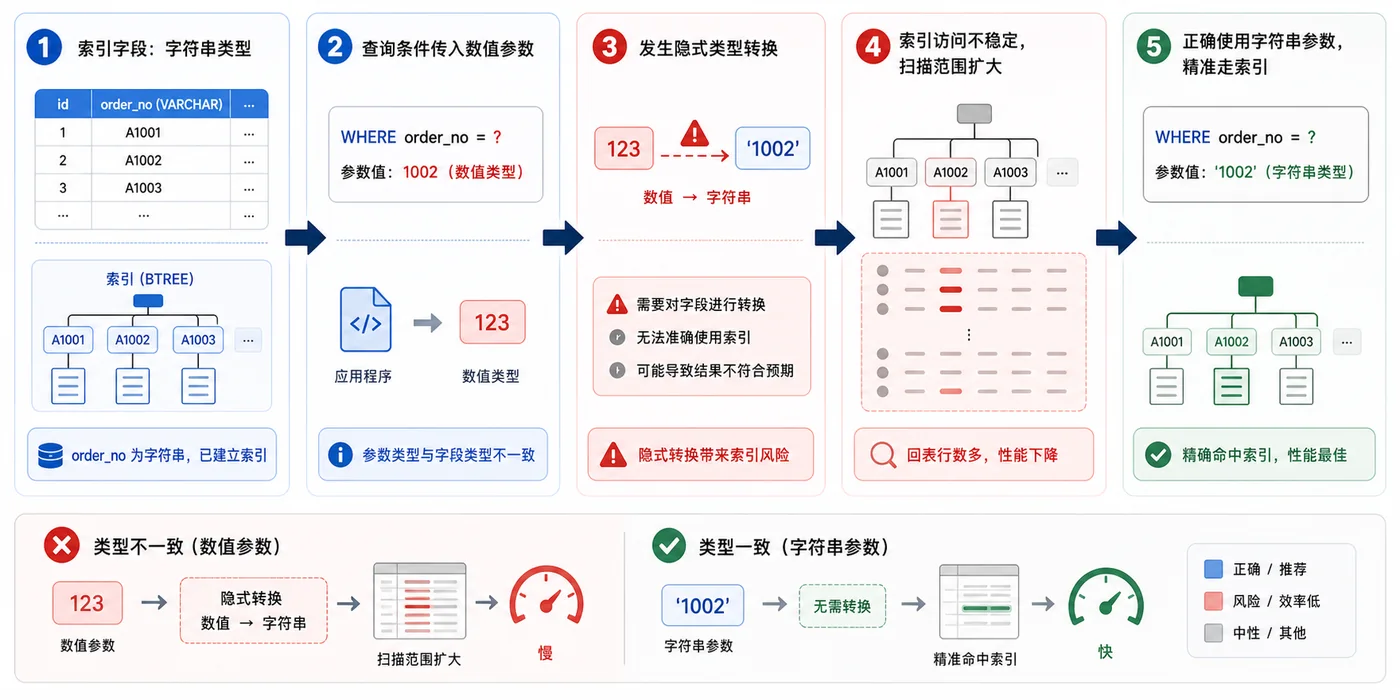 本文用订单号查询变慢的场景,演示 MySQL 隐式转换如何导致索引无法稳定命中,并给出字段类型统一、参数绑定和上线检查方案。152 收藏
本文用订单号查询变慢的场景,演示 MySQL 隐式转换如何导致索引无法稳定命中,并给出字段类型统一、参数绑定和上线检查方案。152 收藏 -
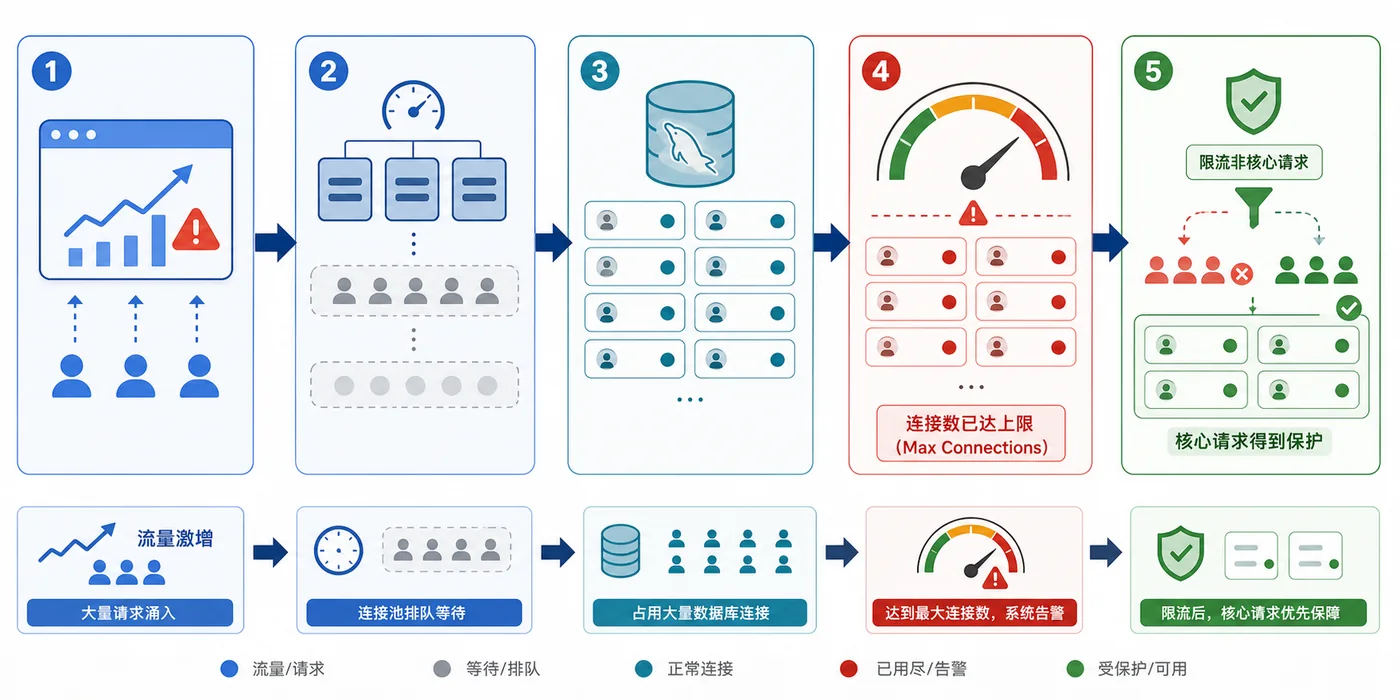 本文用一次 MySQL 连接数告警场景,演示如何区分连接池突增、慢 SQL 堵塞和长事务占用,并给出排查命令和上线兜底建议。404 收藏
本文用一次 MySQL 连接数告警场景,演示如何区分连接池突增、慢 SQL 堵塞和长事务占用,并给出排查命令和上线兜底建议。404 收藏 -
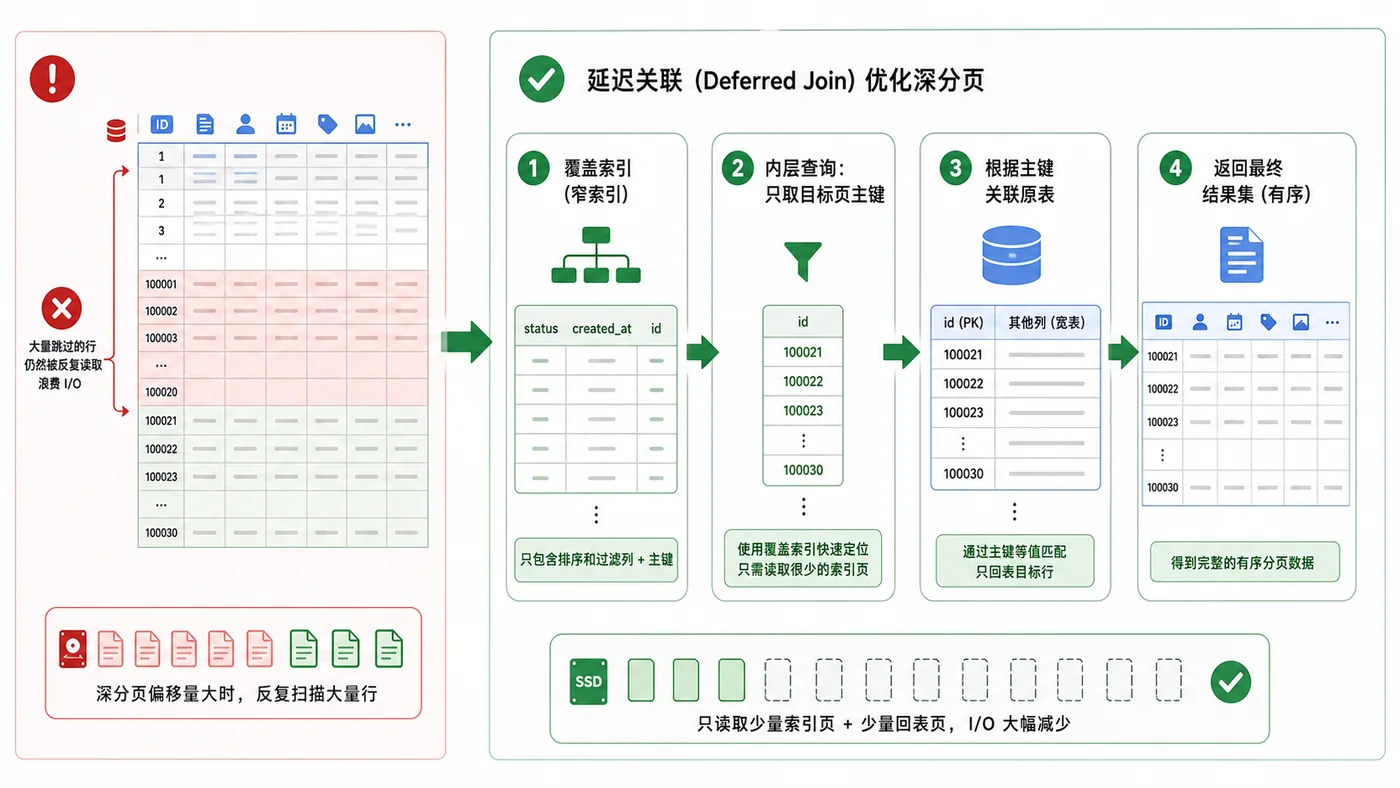 本文用订单列表深分页场景,演示为什么 LIMIT 大偏移会变慢,并通过覆盖索引、延迟关联和游标式分页减少无效扫描。339 收藏
本文用订单列表深分页场景,演示为什么 LIMIT 大偏移会变慢,并通过覆盖索引、延迟关联和游标式分页减少无效扫描。339 收藏 -
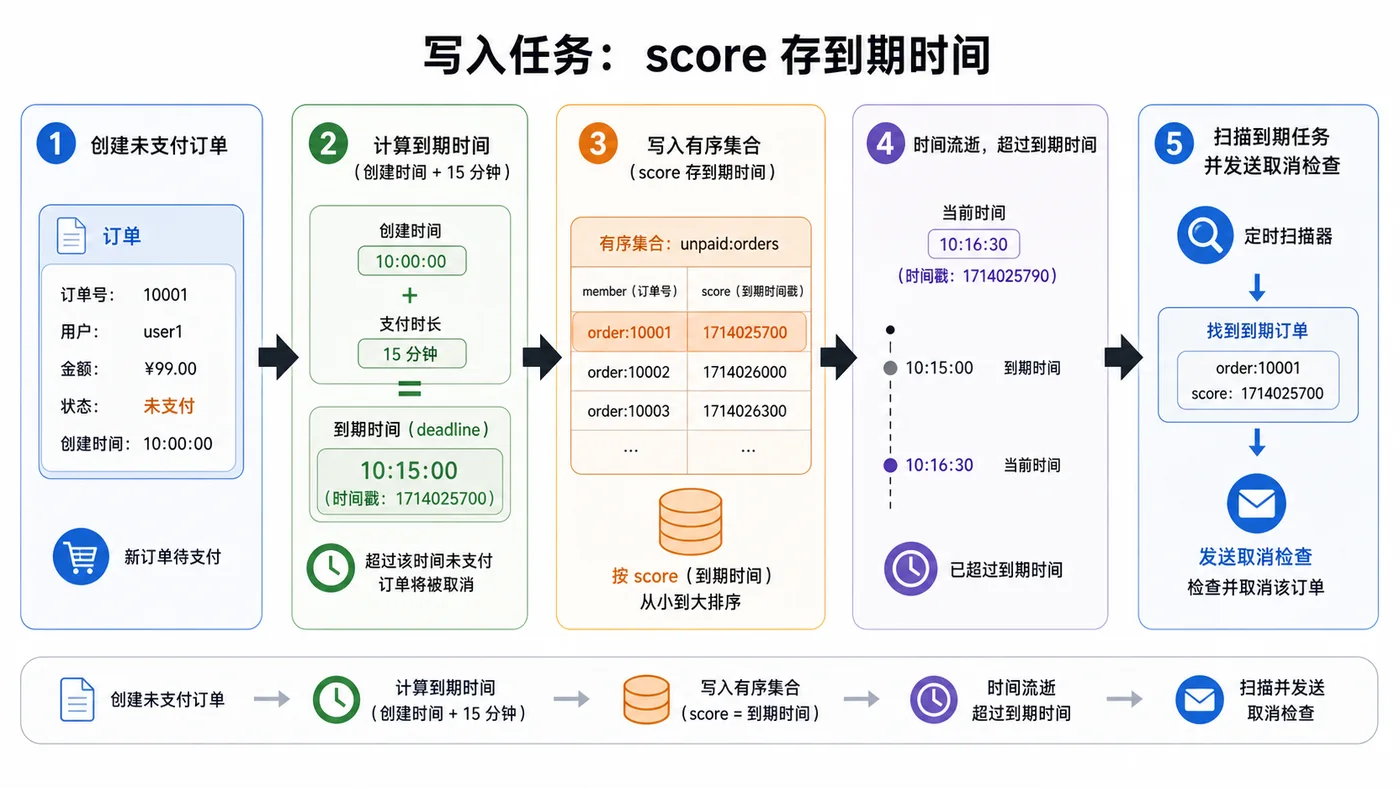 本文用 Redis ZSET 设计一个轻量延迟队列,讲清楚如何写入订单超时任务、按时间扫描到期任务、抢占删除、防重复处理以及失败重试。116 收藏
本文用 Redis ZSET 设计一个轻量延迟队列,讲清楚如何写入订单超时任务、按时间扫描到期任务、抢占删除、防重复处理以及失败重试。116 收藏 -
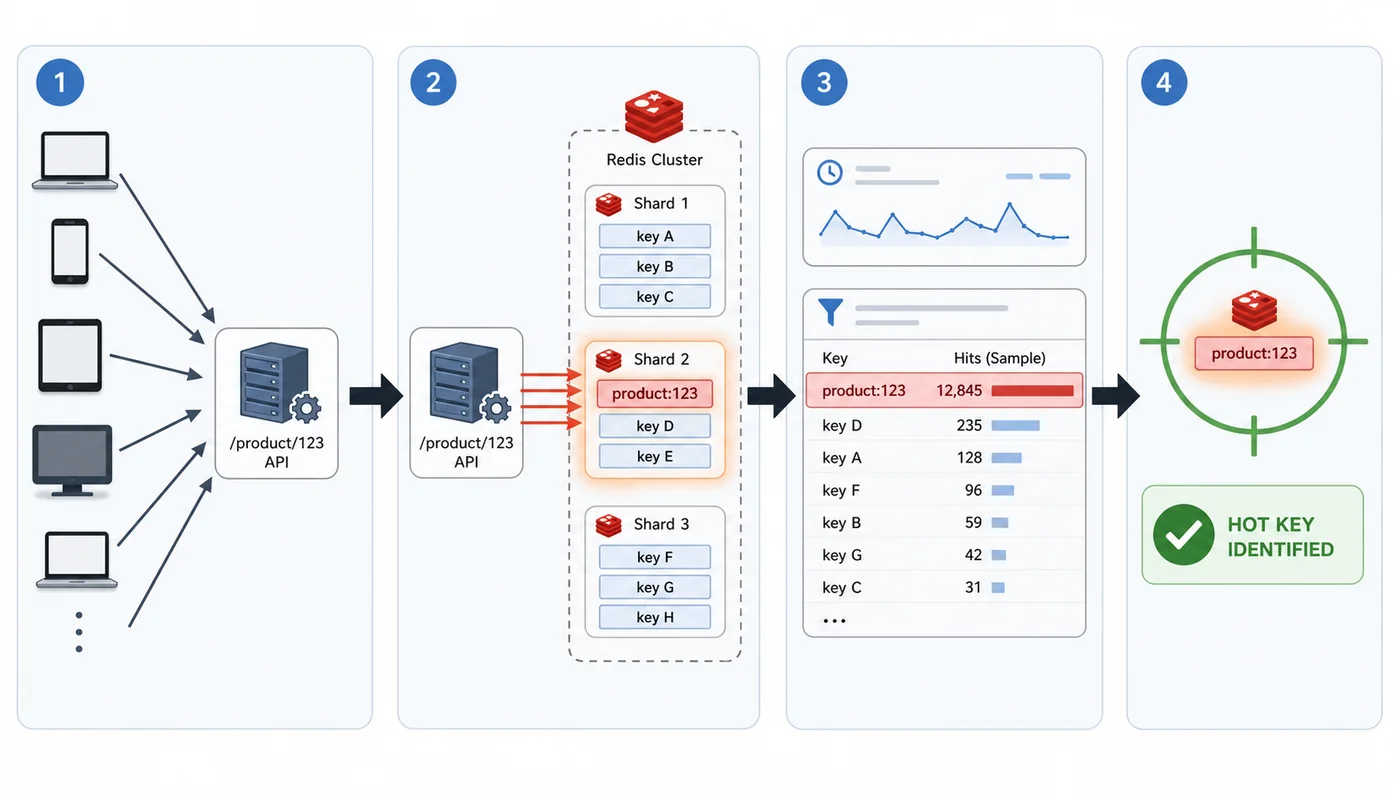 本文从一次商品详情接口抖动出发,演示如何发现 Redis 热 Key、判断访问倾斜,并通过过期时间抖动、本地短缓存、singleflight 合并加载和拆分 Key 降低热点冲击。111 收藏
本文从一次商品详情接口抖动出发,演示如何发现 Redis 热 Key、判断访问倾斜,并通过过期时间抖动、本地短缓存、singleflight 合并加载和拆分 Key 降低热点冲击。111 收藏 -
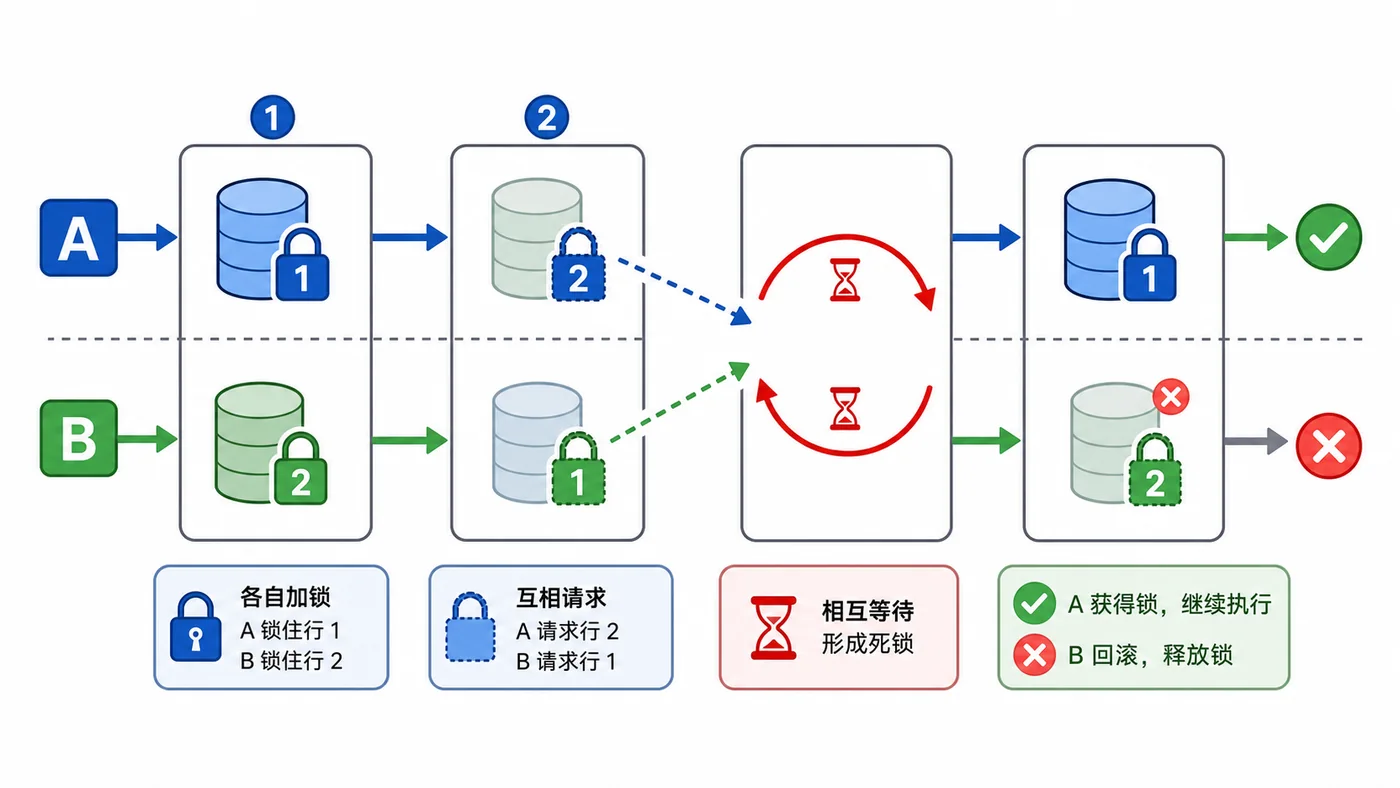 通过转账场景复现 MySQL InnoDB 死锁,演示如何查看死锁信息、理解反向加锁原因,并用固定加锁顺序、缩短事务和重试机制降低问题概率。429 收藏
通过转账场景复现 MySQL InnoDB 死锁,演示如何查看死锁信息、理解反向加锁原因,并用固定加锁顺序、缩短事务和重试机制降低问题概率。429 收藏 -
 通过订单列表慢查询案例,演示如何阅读 EXPLAIN 的 type、key、rows、Extra 字段,并设计联合索引优化 WHERE、ORDER BY 和 LIMIT 分页。159 收藏
通过订单列表慢查询案例,演示如何阅读 EXPLAIN 的 type、key、rows、Extra 字段,并设计联合索引优化 WHERE、ORDER BY 和 LIMIT 分页。159 收藏