MySQL技术文章
-
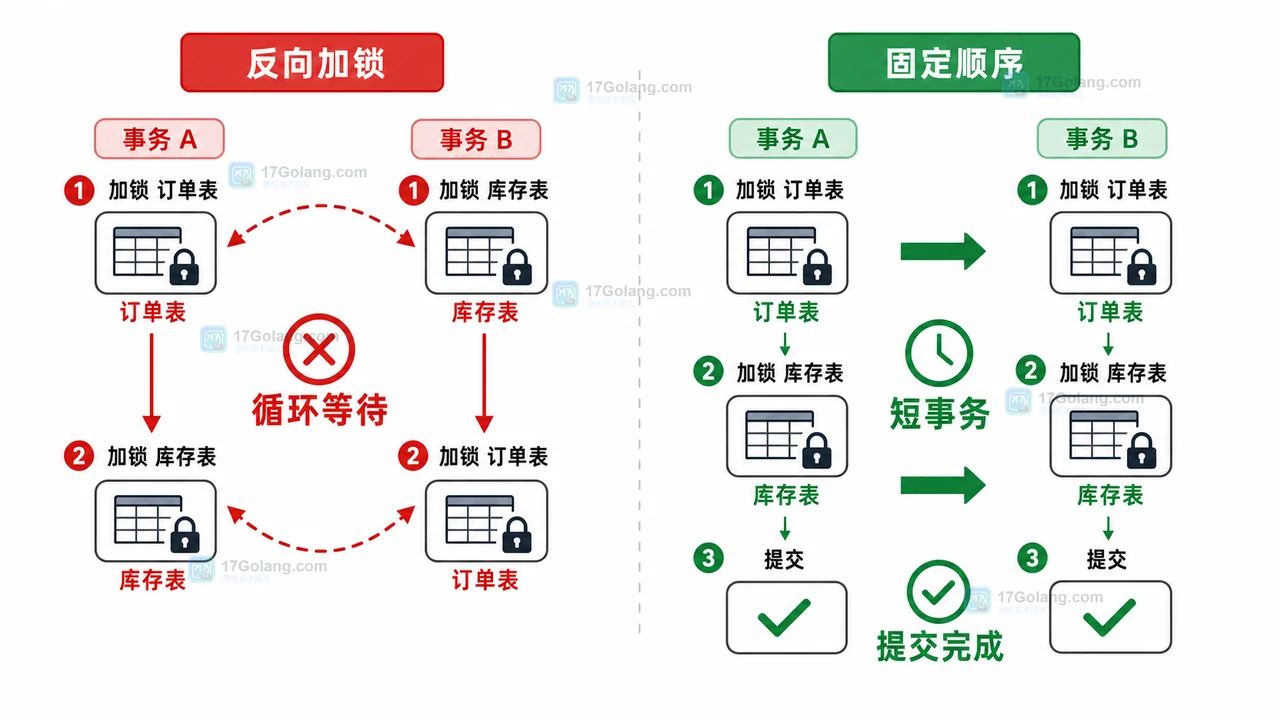 本文整理一套 MySQL InnoDB 死锁排查工作流:从应用报错开始,查看 InnoDB 状态,定位锁等待环,统一事务加锁顺序,缩短锁持有时间,并在业务侧加入有限重试保护。392 收藏
本文整理一套 MySQL InnoDB 死锁排查工作流:从应用报错开始,查看 InnoDB 状态,定位锁等待环,统一事务加锁顺序,缩短锁持有时间,并在业务侧加入有限重试保护。392 收藏 -
数据库 · MySQL | 1个月前 | 执行计划 · MySQL教程 · 慢查询治理 · 索引优化 · 数据库实战 · mysql 执行计划 慢查询 索引优化 MySQL 8 EXPLAIN ANALYZE
 从订单慢查询复现出发,讲清 MySQL 8.x EXPLAIN ANALYZE、估算行数与真实行数、loops、Using filesort、复合索引和上线复查。389 收藏
从订单慢查询复现出发,讲清 MySQL 8.x EXPLAIN ANALYZE、估算行数与真实行数、loops、Using filesort、复合索引和上线复查。389 收藏 -
 从 MySQL Invisible Indexes 入手,讲清如何用不可见索引灰度验证删索引风险,避免直接 DROP INDEX 带来的线上慢查询和回滚成本。388 收藏
从 MySQL Invisible Indexes 入手,讲清如何用不可见索引灰度验证删索引风险,避免直接 DROP INDEX 带来的线上慢查询和回滚成本。388 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · InnoDB · 生产实践 · MySQL教程 · 数据库运维 · mysql redo log innodb 性能优化 innodb_redo_log_capacity
 从 MySQL 8.4 的 innodb_redo_log_capacity 入手,讲清 redo log 容量、检查点压力、写入抖动和崩溃恢复时间之间的取舍,并给出上线检查清单。382 收藏
从 MySQL 8.4 的 innodb_redo_log_capacity 入手,讲清 redo log 容量、检查点压力、写入抖动和崩溃恢复时间之间的取舍,并给出上线检查清单。382 收藏 -
 从手机号后四位和日期函数查询变慢切入,讲清 MySQL 8.x 函数索引、生成列、表达式匹配、EXPLAIN 验证、DDL 风险和上线检查。381 收藏
从手机号后四位和日期函数查询变慢切入,讲清 MySQL 8.x 函数索引、生成列、表达式匹配、EXPLAIN 验证、DDL 风险和上线检查。381 收藏 -
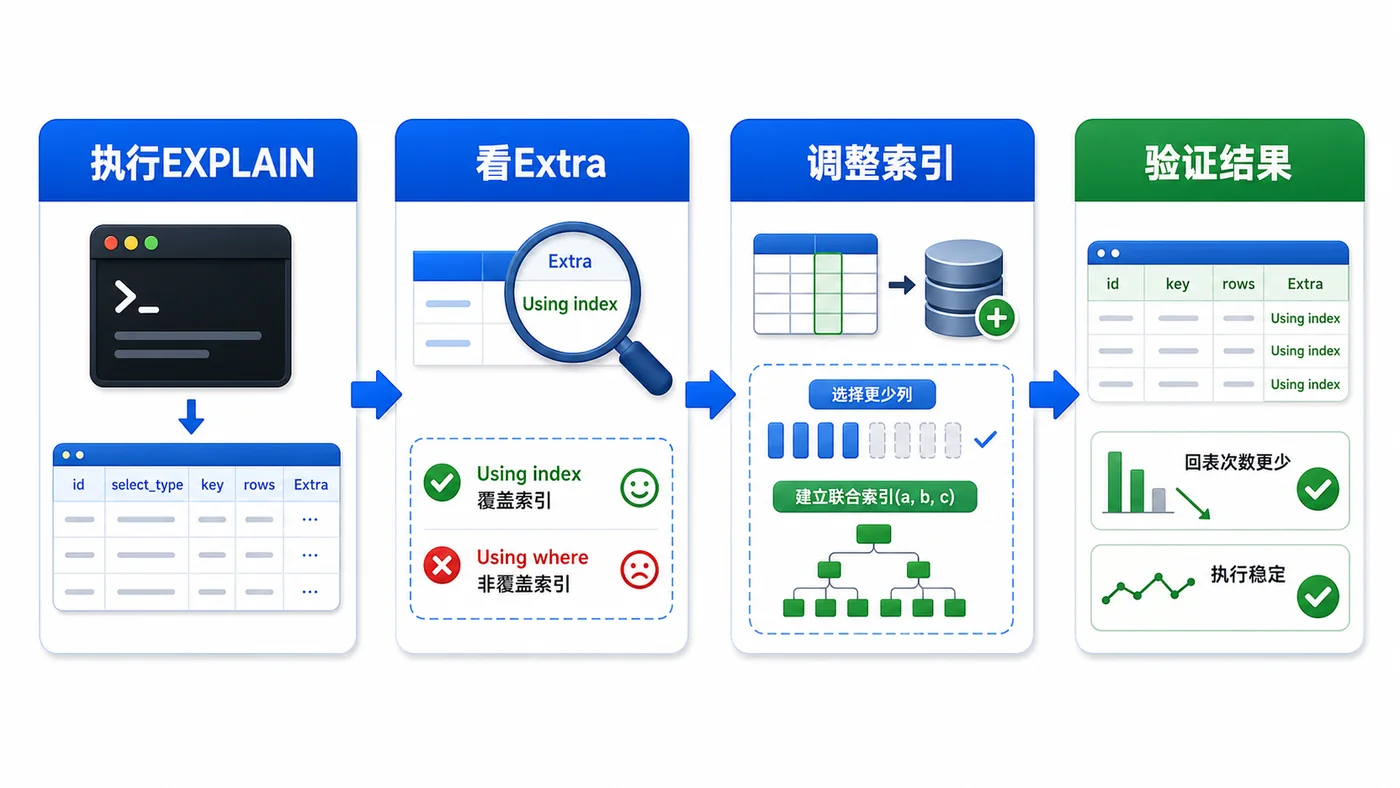 本文用订单列表查询场景,演示普通二级索引为什么需要回表,以及如何通过覆盖索引减少回表,并用 EXPLAIN 的 Extra 验证优化结果。381 收藏
本文用订单列表查询场景,演示普通二级索引为什么需要回表,以及如何通过覆盖索引减少回表,并用 EXPLAIN 的 Extra 验证优化结果。381 收藏 -
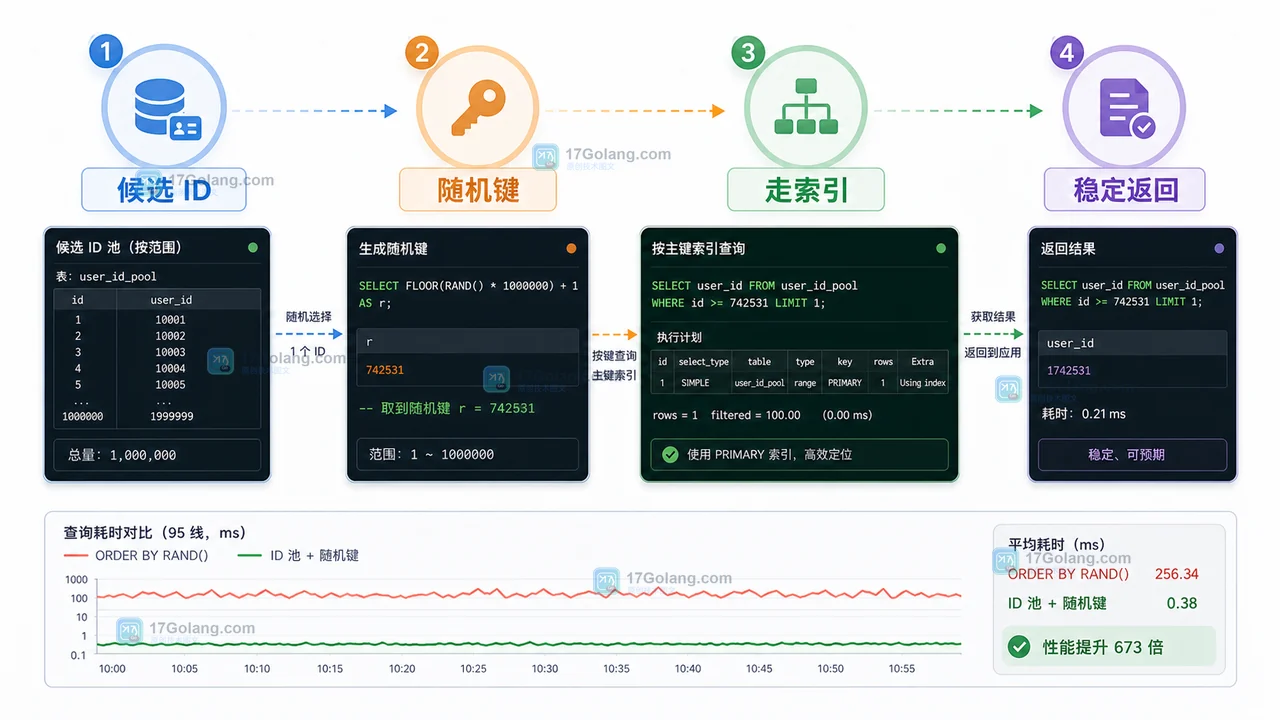 MySQL 里用 ORDER BY RAND() 做随机推荐,小表还能凑合,大表高并发下容易触发全表排序、临时表放大和 CPU 飙升。更稳的做法是先缩小候选集合,再用候选 ID 池、随机键或业务侧抽样把查询控制在索引范围内。378 收藏
MySQL 里用 ORDER BY RAND() 做随机推荐,小表还能凑合,大表高并发下容易触发全表排序、临时表放大和 CPU 飙升。更稳的做法是先缩小候选集合,再用候选 ID 池、随机键或业务侧抽样把查询控制在索引范围内。378 收藏 -
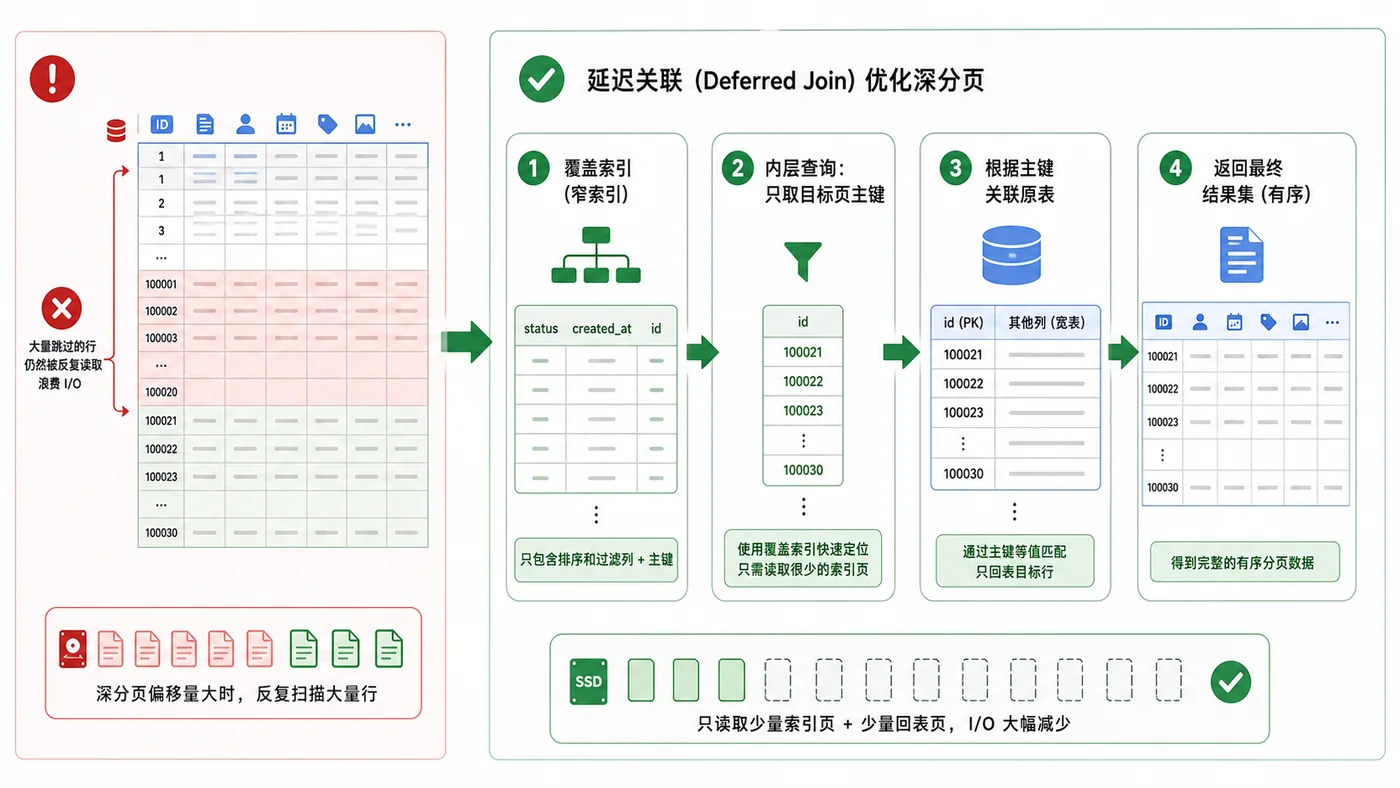 本文用订单列表深分页场景,演示为什么 LIMIT 大偏移会变慢,并通过覆盖索引、延迟关联和游标式分页减少无效扫描。339 收藏
本文用订单列表深分页场景,演示为什么 LIMIT 大偏移会变慢,并通过覆盖索引、延迟关联和游标式分页减少无效扫描。339 收藏 -
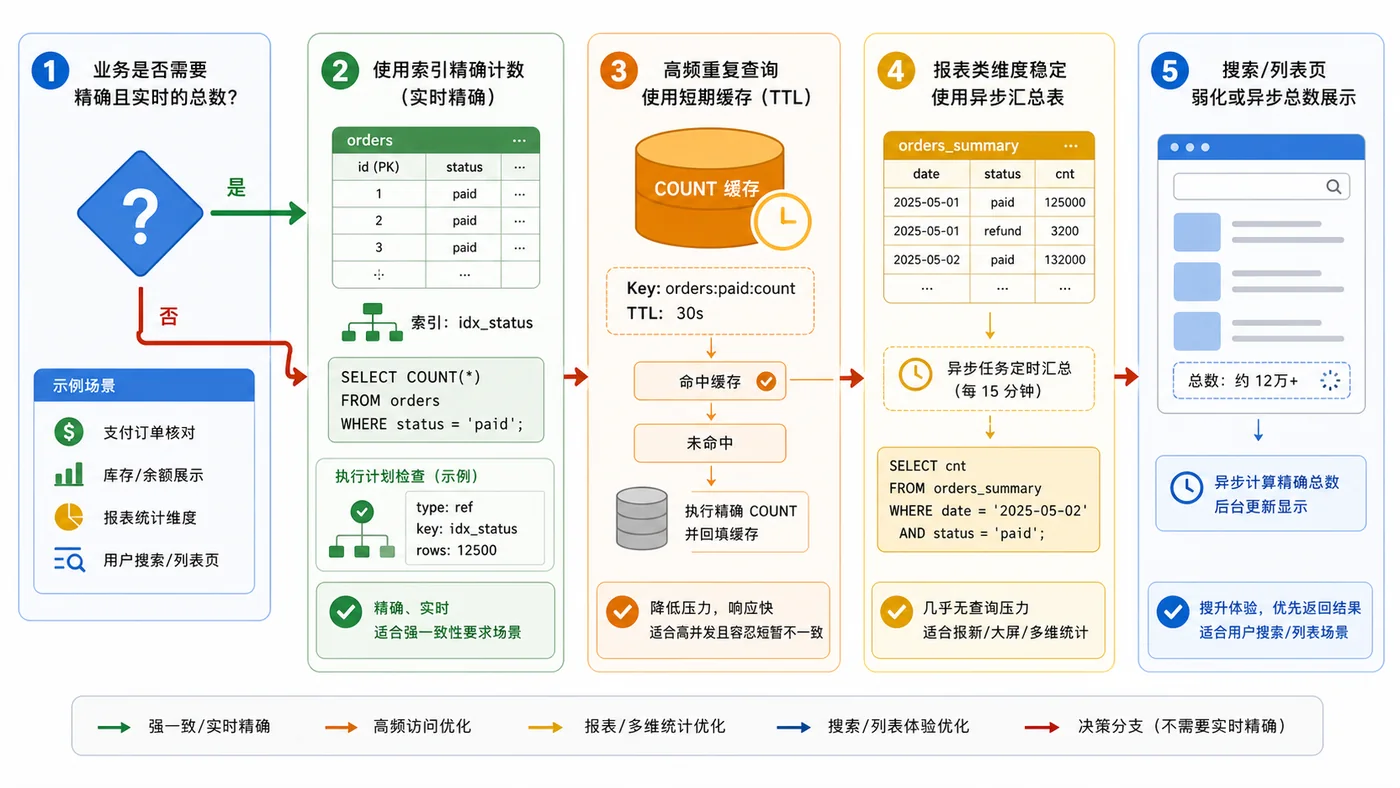 本文用后台订单列表总数统计场景,演示为什么大表每次 COUNT 会拖慢接口,并按精确总数、条件筛选、缓存和汇总表给出优化方案。336 收藏
本文用后台订单列表总数统计场景,演示为什么大表每次 COUNT 会拖慢接口,并按精确总数、条件筛选、缓存和汇总表给出优化方案。336 收藏 -
 MySQL 读写分离不是简单把 SELECT 丢到从库。它适合读多写少、查询压力明显大于写入压力的业务,但会带来复制延迟、读己之写、路由规则和故障切换问题。上线前要先确认读写比例、数据一致性要求和回主策略。334 收藏
MySQL 读写分离不是简单把 SELECT 丢到从库。它适合读多写少、查询压力明显大于写入压力的业务,但会带来复制延迟、读己之写、路由规则和故障切换问题。上线前要先确认读写比例、数据一致性要求和回主策略。334 收藏 -
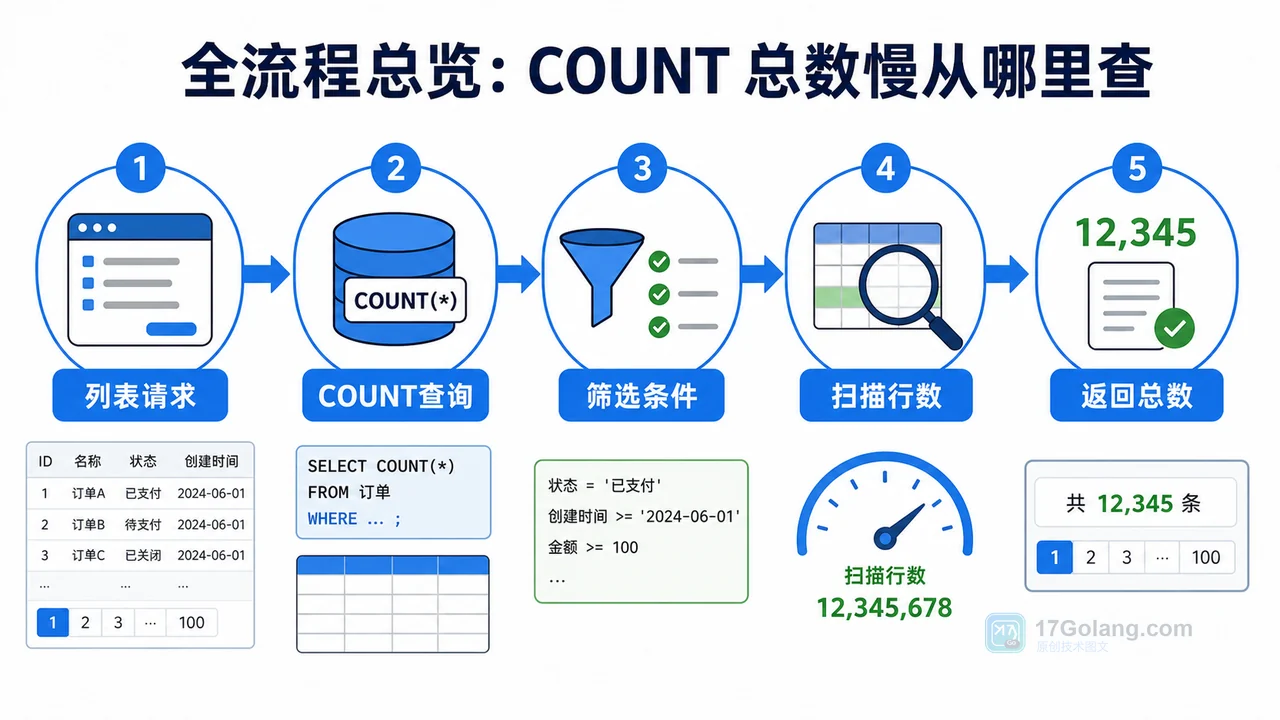 列表页分页常常要查总数,但 COUNT(*) 一慢,整个页面都会被拖住。本文按完整工作流拆解:先确认筛选条件和扫描行数,再选择联合索引、缓存总数或汇总表,最后给出上线检查清单。329 收藏
列表页分页常常要查总数,但 COUNT(*) 一慢,整个页面都会被拖住。本文按完整工作流拆解:先确认筛选条件和扫描行数,再选择联合索引、缓存总数或汇总表,最后给出上线检查清单。329 收藏 -
数据库 · MySQL | 1个月前 | InnoDB · 故障排查 · 生产实践 · MySQL教程 · 事务隔离 · mysql innodb Purge Lag History List 长事务 Undo
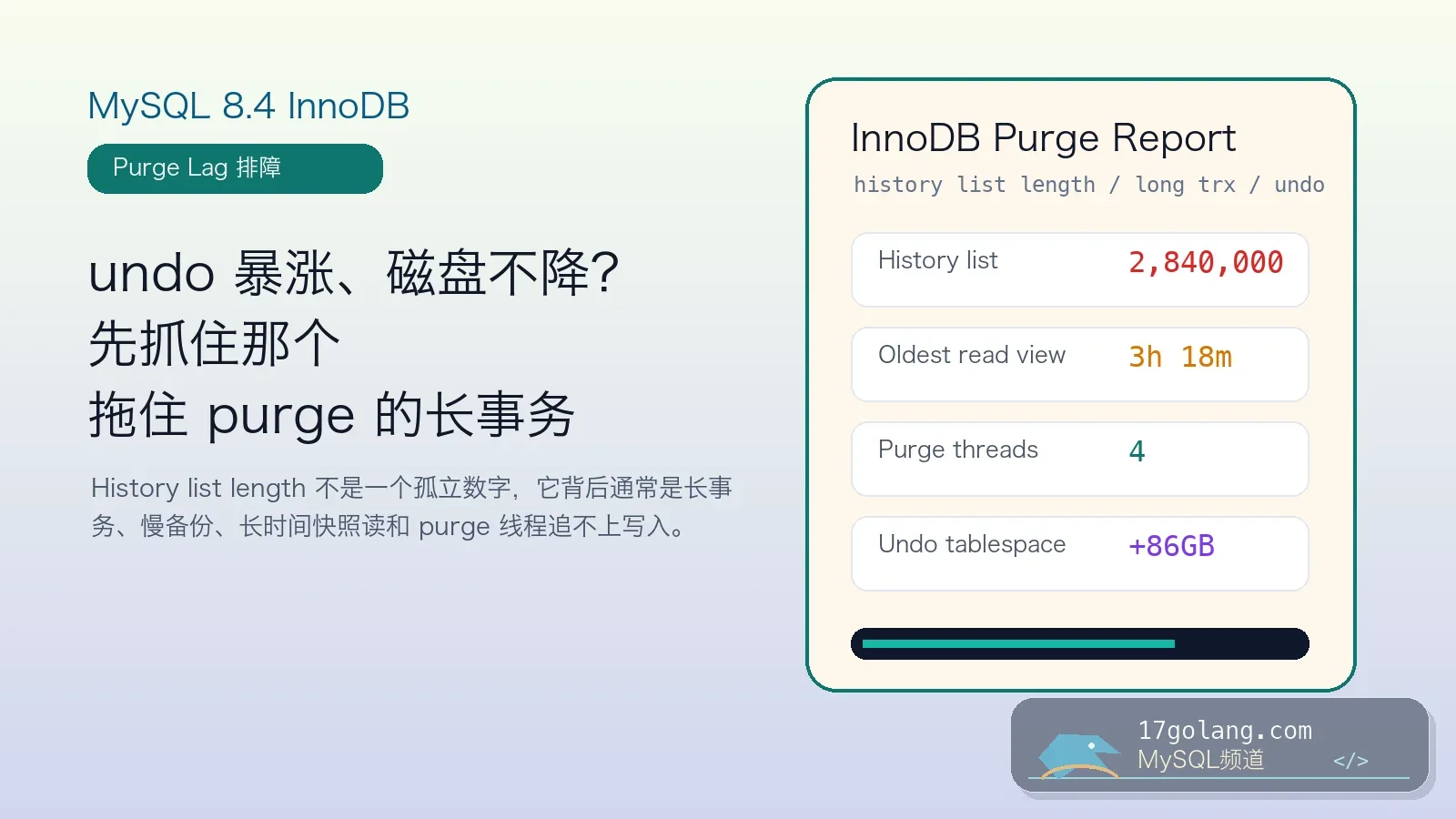 从 MySQL 8.4 InnoDB purge lag 入手,讲清 history list length、长事务、undo 暴涨和 purge 参数的生产排障方法。326 收藏
从 MySQL 8.4 InnoDB purge lag 入手,讲清 history list length、长事务、undo 暴涨和 purge 参数的生产排障方法。326 收藏 -
数据库 · MySQL | 1个月前 | MySQL教程 · 数据库实战 · 在线DDL · ALTER TABLE · 元数据锁 · mysql innodb MySQL 8 在线 DDL ALTER TABLE MDL 元数据锁 INSTANT
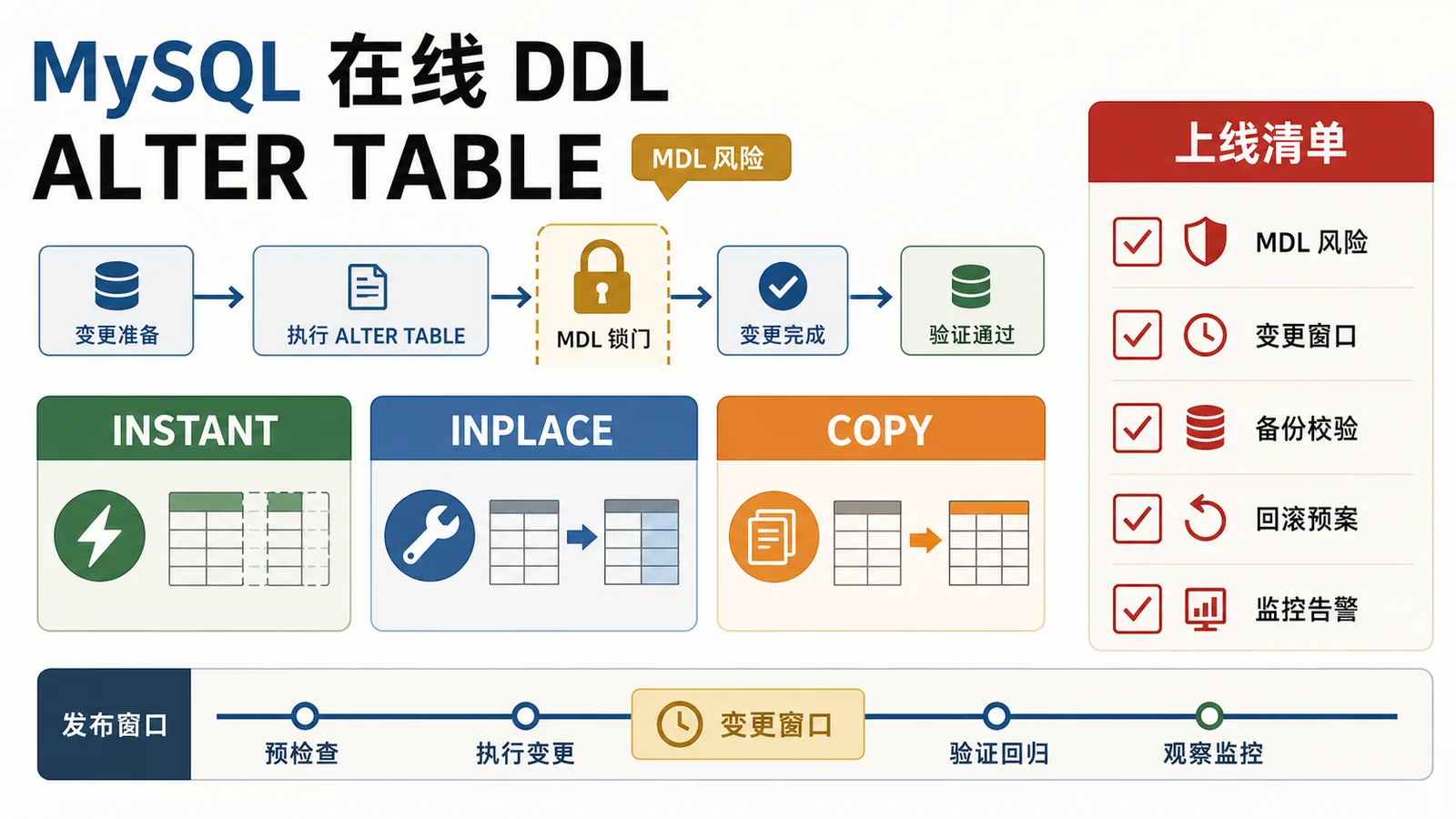 从订单大表加字段出发,讲清 MySQL 8.x 在线 DDL、ALGORITHM=INSTANT/INPLACE/COPY、metadata lock、row version 上限、复制延迟和上线复查。323 收藏
从订单大表加字段出发,讲清 MySQL 8.x 在线 DDL、ALGORITHM=INSTANT/INPLACE/COPY、metadata lock、row version 上限、复制延迟和上线复查。323 收藏 -
 本文按完整工作流讲解 MySQL 慢 SQL 优化:从慢查询日志发现候选 SQL,聚合同类语句,用 EXPLAIN 判断访问方式和扫描行数,再设计联合索引,并通过延迟、扫描行数和业务结果做回归验证。321 收藏
本文按完整工作流讲解 MySQL 慢 SQL 优化:从慢查询日志发现候选 SQL,聚合同类语句,用 EXPLAIN 判断访问方式和扫描行数,再设计联合索引,并通过延迟、扫描行数和业务结果做回归验证。321 收藏 -
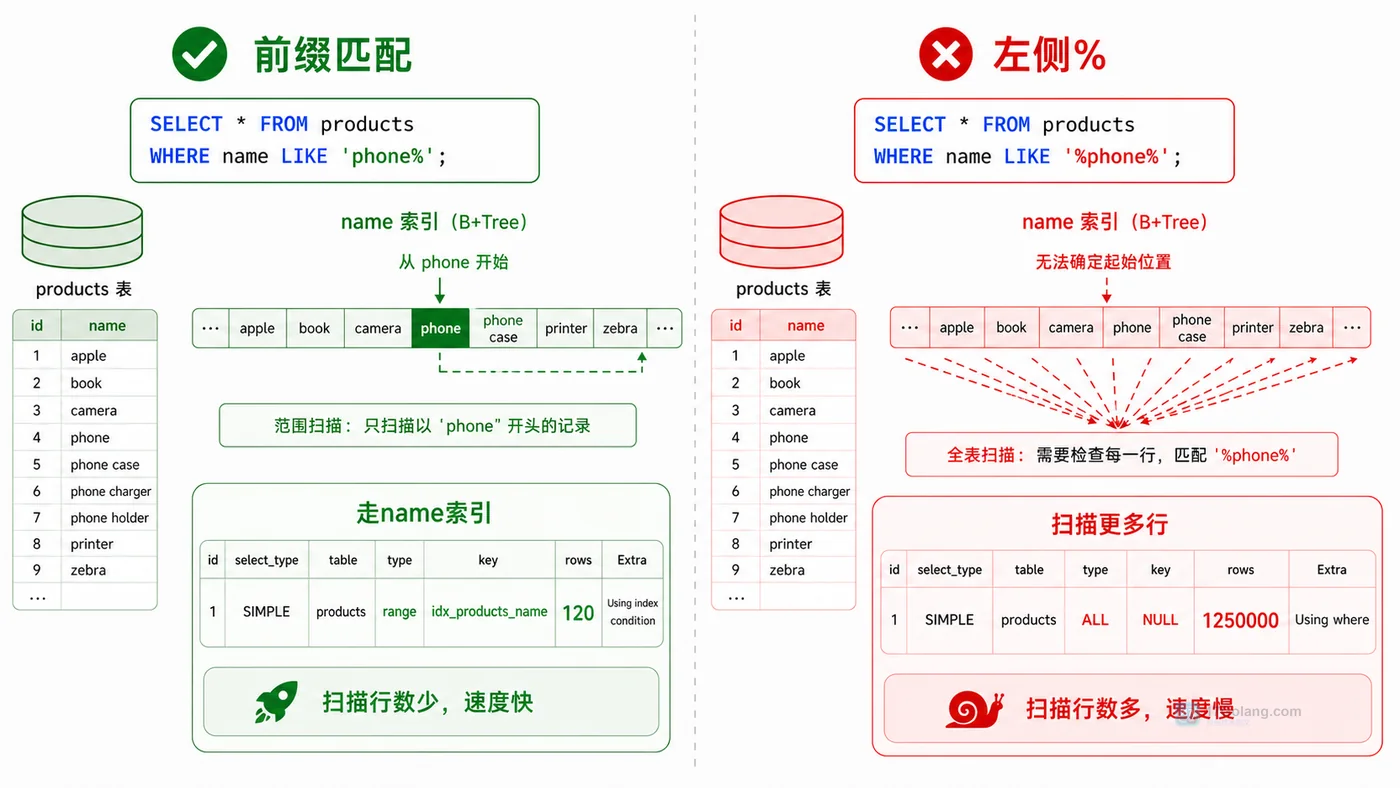 搜索框查询一上线就变慢,很多时候不是数据量突然失控,而是 LIKE 条件写法让索引用不上。本文从慢查询现场开始,逐步验证左通配符、执行计划、前缀匹配和业务改写,整理一套更稳的模糊搜索排查方法。308 收藏
搜索框查询一上线就变慢,很多时候不是数据量突然失控,而是 LIKE 条件写法让索引用不上。本文从慢查询现场开始,逐步验证左通配符、执行计划、前缀匹配和业务改写,整理一套更稳的模糊搜索排查方法。308 收藏