-

Redis启动后无法访问的原因主要包括配置文件问题、网络问题、防火墙设置和内存不足。解决方案如下:1.调整配置文件,确保绑定地址和端口正确;2.修复网络连接,确保Redis服务器和客户端连接正常;3.调整防火墙规则,允许Redis端口访问;4.增加内存或调整Redis配置,确保内存充足。
-

Redis是一个高效、开源的内存数据库,具有高速的读写速度和持久化存储功能。它被广泛应用于缓存、会话管理和消息队列等场景。本文将从Redis的基本概念和使用方法开始,深入探讨其在实际项目中的应用和优化技巧。Redis基本概念Redis是一个基于内存的键值对存储系统,与传统的关系型数据库相比,Redis更加适用于存储和处理大规模数据,并且能够支持多种数据结构和
-
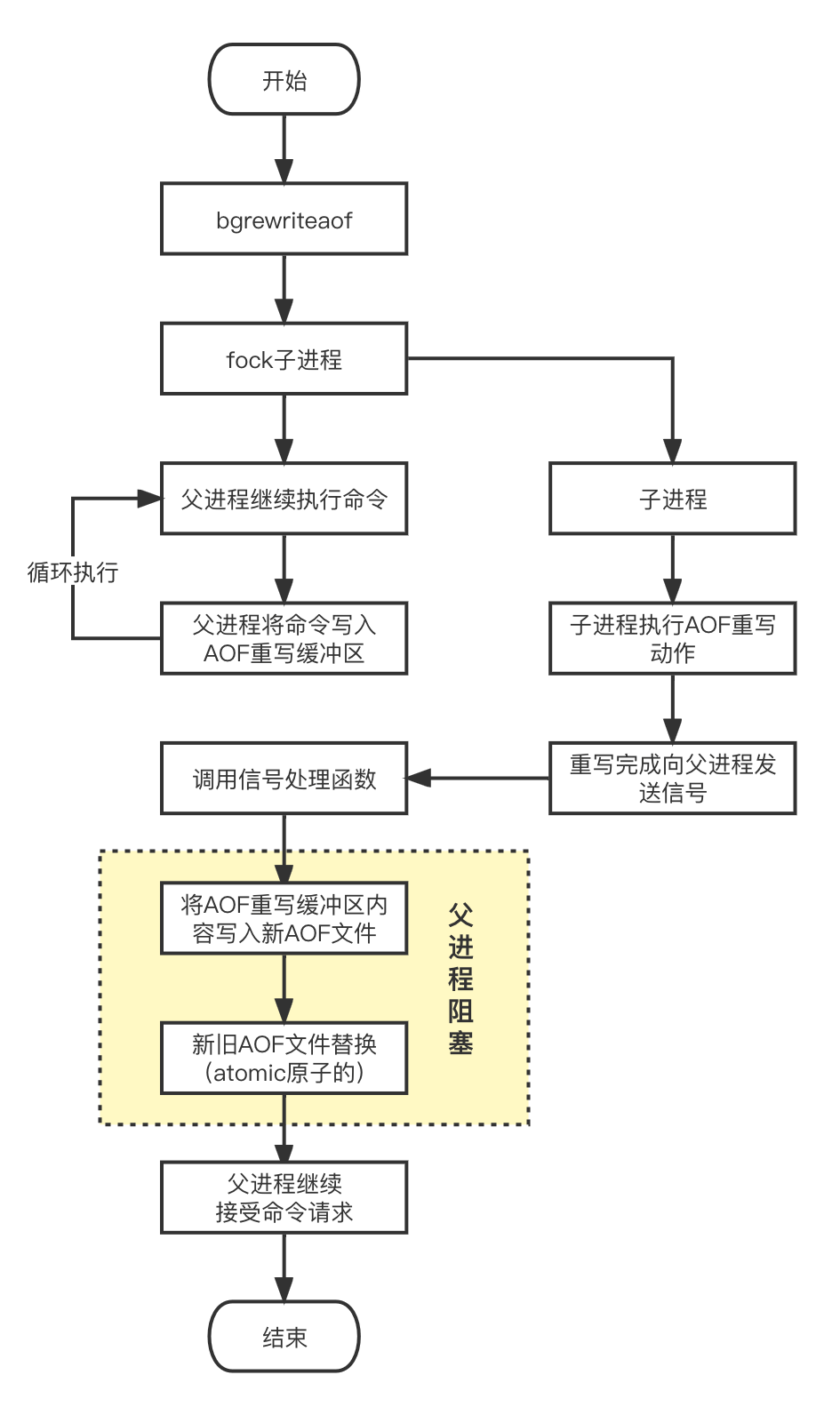
1.RDB持久化
首先,RDB持久化方式会产生一个经过压缩的二进制文件,Redis服务器在启动之初,通过这个文件可以还原数据库的状态。那么我们接下来看下RDB文件是如何实现保存和载入的。
1.1
-
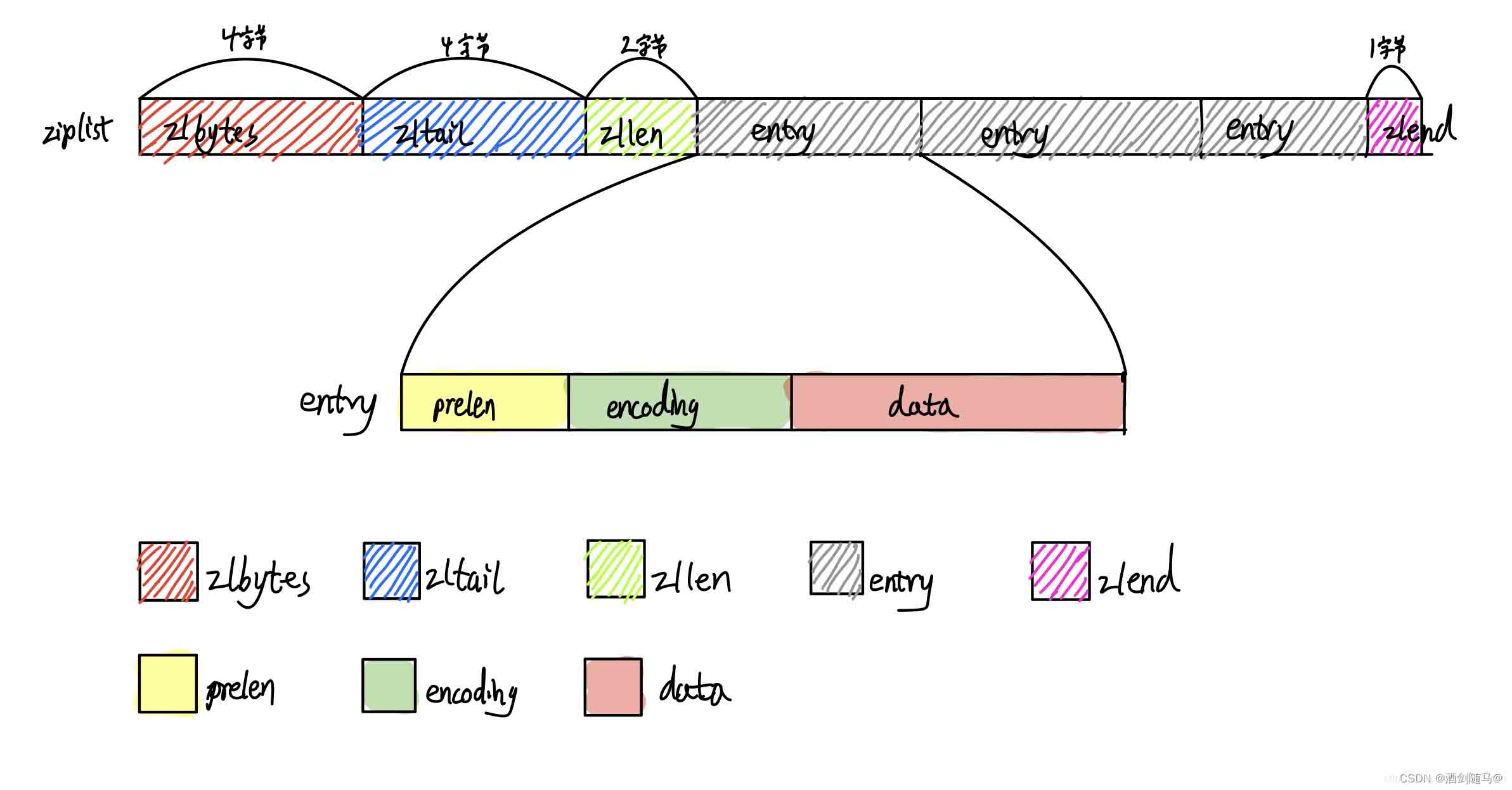
hash的数据结构
hash底层数据结构的实现包括两种:ziplist和字典当保存的所有键值对字符串长度小于 64 字节并且键值对数量小于 512 时使用ziplist ,否则使用字典的方式
ziplist底层实现
ziplist是为
-
随着系统访问量的提高,复杂度的提升,响应性能成为一个重点的关注点。而缓存的使用成为一个重点。redis 作为缓存中间件的一个佼佼者,成为了面试必问项目。本文分享一下Redis几道常见的
-

Redis主从复制卡顿延迟飙升的典型表现是master_repl_offset与slave_repl_offset差值持续扩大、sync_full_ok频发,根本原因是fork子进程阻塞主线程,尤其内存大时fork耗时长导致repl-backlog溢出。
-

Redis和Kafka可以集成使用,发挥各自优势。1.用户行为数据先存储在Redis中,确保实时性。2.通过定时任务或触发器将数据推送到Kafka,保证数据的顺序和可靠性。3.后端系统从Kafka消费数据进行实时分析和处理,实现高效的消息队列系统。
-

通过调整Redis的配置参数可以显著提高其读写性能。1.内存管理:设置maxmemory为10GB,maxmemory-policy为allkeys-lru。2.网络通信:调整tcp-backlog为511,timeout为0。3.持久化:设置RDB快照频率为save9001、save30010、save6010000,AOF的appendfsync为everysec。
-

解决Redis启动时内存分配不足问题的方法包括:1.检查系统内存使用情况,必要时增加物理内存或调整Redis配置;2.修改redis.conf文件中的maxmemory参数,限制Redis内存使用;3.配置maxmemory-policy参数,选择合适的内存回收策略;4.增加swap空间或禁用Redis的swap使用;5.通过RedisCluster分散数据存储,降低单节点内存压力;6.使用MEMORYUSAGE命令查找并处理大key。
-

简单来说redis就是一个数据库,不过与传统数据库不同的是redis的数据是存在内存中的,所以读写速度非常快,因此redis被广泛应用于缓存方向。安装下载,解压,编译:$wgethttp://download.redis.io/releases/redis-4.0.10.tar.gz$tarxzfredis-4.0.10.tar.gz$mvredis-4.0.10/usr/local/redis$cd/usr/local/redis$make二进制文件是编译完成后在src目录下$ll-asrc|grepr
-

Redis是一种高性能的内存缓存数据库,常用于处理数据量较大且对响应速度有较高要求的场景下。由于Redis是基于内存存储,因此每次重启都会导致缓存数据的丢失,为了解决这个问题,Redis提供了主从同步的功能。Redis主从同步是为了保证Redis的高可用性而设计的。当Redis的主节点出现故障时,从节点会自动接管主节点的角色,从而保证了系统
-

背景使用业务场景:1.利用数据库自增主键生成唯一ID,无法满足各个系统独自生成自增的唯一ID需求。在分布式系统,需要生成唯一ID的系统不止一个,这些ID的生成在各自业务内是独立的
-

通过redis-cli、RedisInsight、Prometheus和Grafana等工具,以及关注内存使用率、连接数、集群节点状态、数据一致性和性能指标,可以有效监控Redis集群的健康状态。
-

最佳实践是使用Docker部署Redis时,应注意数据持久化、配置管理、网络配置和性能优化。1.使用Docker命令启动Redis容器:dockerrun--namemy-redis-p6379:6379-dredis。2.配置数据持久化:dockerrun--namemy-redis-p6379:6379-v/path/to/host/data:/data-dredis。3.定制Redis配置:dockerrun--namemy-redis-p6379:6379-v/path/to/host/conf/
-

1.Redis的5种数据类型redis是一种高级的key-value的存储系统,其中value支持五种数据类型:Redis支持的键值数据类型string字符串类型hash表类型list列表类型set集合类型zset有序集合类型关于key的定义,注意如下几点:不建议key名字太长,通常不超过1024,如果太长会影响查询的速度。不建议太短,太短会降低可读性。一般在公司,都有统一命名规范。2.字符串类型string2.1概述字符串类型是Redis中最为基础的数据存储类型,它在Redis中以二进制保存,没有编码和