Redis技术文章
-
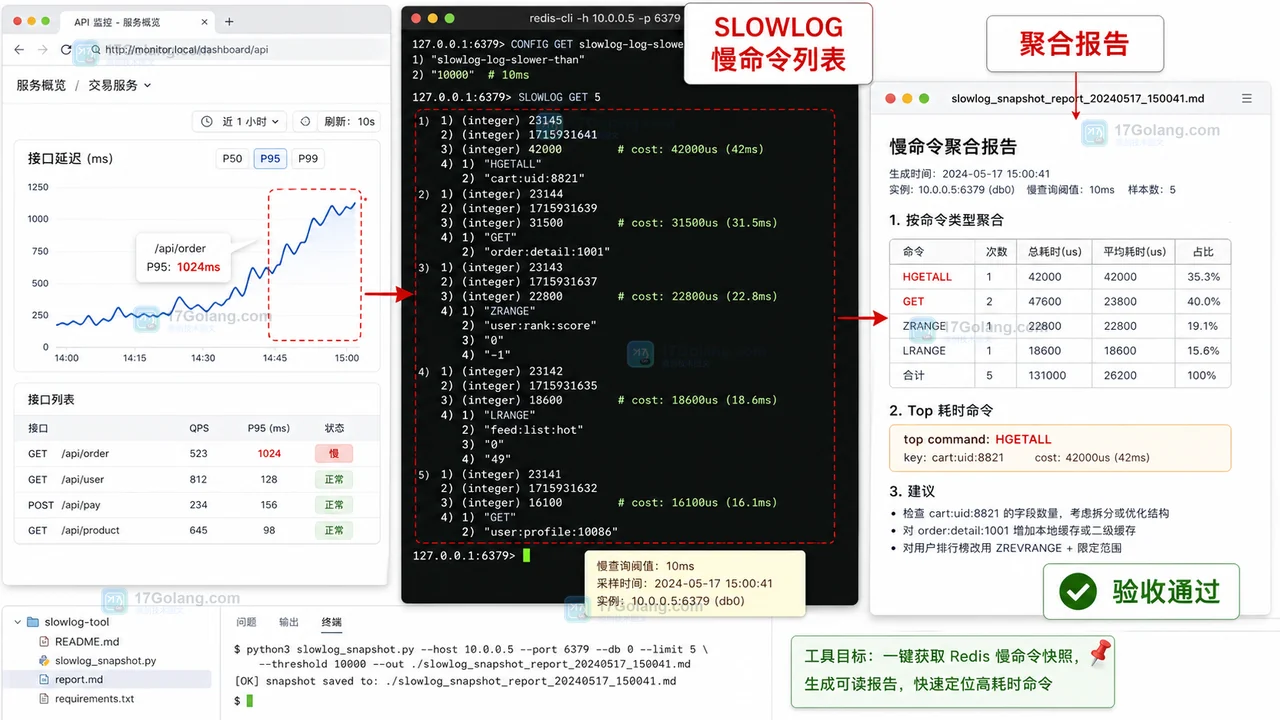 从零做一个 Redis 慢命令快照小工具,采集 SLOWLOG 样本,解析命令耗时和 Key 线索,按命令类型聚合成 Markdown 报告,用于接口延迟排查和上线前验收。501 收藏
从零做一个 Redis 慢命令快照小工具,采集 SLOWLOG 样本,解析命令耗时和 Key 线索,按命令类型聚合成 Markdown 报告,用于接口延迟排查和上线前验收。501 收藏 -
 @Cacheable默认不设过期时间,若统一配置TTL则所有key同步过期易引发雪崩;需通过RedisTemplate手动写入并添加随机偏移(如10分钟±60秒)来缓解。498 收藏
@Cacheable默认不设过期时间,若统一配置TTL则所有key同步过期易引发雪崩;需通过RedisTemplate手动写入并添加随机偏移(如10分钟±60秒)来缓解。498 收藏 -
 Redisset命令只支持字符串值,存对象需先序列化为JSON;注意处理日期、枚举等特殊字段,避免额外引号,跨语言场景优先选JSON而非Java原生序列化。496 收藏
Redisset命令只支持字符串值,存对象需先序列化为JSON;注意处理日期、枚举等特殊字段,避免额外引号,跨语言场景优先选JSON而非Java原生序列化。496 收藏 -
 Redis发布订阅不保存历史消息,因此SUBSCRIBE收不到已发布的消息;审计必须由发布端主动同步写入持久化存储,不能依赖Pub/Sub自身机制。495 收藏
Redis发布订阅不保存历史消息,因此SUBSCRIBE收不到已发布的消息;审计必须由发布端主动同步写入持久化存储,不能依赖Pub/Sub自身机制。495 收藏 -
 分片后每个Redis节点必须独立配置持久化,RDB需统一save规则且隔离磁盘路径,AOF应全节点开启并设appendfsynceverysec,避免部分节点未持久化导致数据丢失。494 收藏
分片后每个Redis节点必须独立配置持久化,RDB需统一save规则且隔离磁盘路径,AOF应全节点开启并设appendfsynceverysec,避免部分节点未持久化导致数据丢失。494 收藏 -
 Redis发布订阅怕大Key是因为PUBLISH不校验消息大小,大Payload会阻塞单线程主线程,导致延迟飙升、内存积压;应用层需在序列化后截断或拒绝超限消息(如>100KB),订阅端须预检长度并禁用自动解码,大Payload场景应改用SET+key事件、DB查询或Kafka等替代方案。491 收藏
Redis发布订阅怕大Key是因为PUBLISH不校验消息大小,大Payload会阻塞单线程主线程,导致延迟飙升、内存积压;应用层需在序列化后截断或拒绝超限消息(如>100KB),订阅端须预检长度并禁用自动解码,大Payload场景应改用SET+key事件、DB查询或Kafka等替代方案。491 收藏 -
 应使用Redis的Hash或ZSet维护用户会话映射,新登录时先获取并删除旧会话缓存及黑名单,配合事务或Lua脚本保证并发安全,而非仅依赖EXPIRE。491 收藏
应使用Redis的Hash或ZSet维护用户会话映射,新登录时先获取并删除旧会话缓存及黑名单,配合事务或Lua脚本保证并发安全,而非仅依赖EXPIRE。491 收藏 -
 执行replicaofnoone再replicaof不会清空从库数据,仅切换复制源;真正全量同步需确保无运行复制流且master_replid/offset不匹配,必要时手动清空或重启从库。489 收藏
执行replicaofnoone再replicaof不会清空从库数据,仅切换复制源;真正全量同步需确保无运行复制流且master_replid/offset不匹配,必要时手动清空或重启从库。489 收藏 -
 Redis主从复制卡顿延迟飙升的典型表现是master_repl_offset与slave_repl_offset差值持续扩大、sync_full_ok频发,根本原因是fork子进程阻塞主线程,尤其内存大时fork耗时长导致repl-backlog溢出。485 收藏
Redis主从复制卡顿延迟飙升的典型表现是master_repl_offset与slave_repl_offset差值持续扩大、sync_full_ok频发,根本原因是fork子进程阻塞主线程,尤其内存大时fork耗时长导致repl-backlog溢出。485 收藏 -
 根本原因是JedisSentinelPool未真正启用自动发现机制;必须显式设置setTestOnBorrow(true)、传入至少两个可达哨兵地址、调大sentinelMonitorInterval,否则轮询不触发重建且DNS/连接复用导致持续连旧主。482 收藏
根本原因是JedisSentinelPool未真正启用自动发现机制;必须显式设置setTestOnBorrow(true)、传入至少两个可达哨兵地址、调大sentinelMonitorInterval,否则轮询不触发重建且DNS/连接复用导致持续连旧主。482 收藏 -
 能,但仅限Redis服务器端EVAL/EVALSHA上下文;需用正确日志级别常量和预拼接字符串,且依赖redis.conf中loglevel和logfile配置生效。479 收藏
能,但仅限Redis服务器端EVAL/EVALSHA上下文;需用正确日志级别常量和预拼接字符串,且依赖redis.conf中loglevel和logfile配置生效。479 收藏 -
 repl-backlog-ttl是Redis主节点在无从节点连接时自动释放复制积压缓冲区的时间阈值,默认3600秒;超时后清空backlog,导致重连从节点无法部分同步而触发开销巨大的全量同步。477 收藏
repl-backlog-ttl是Redis主节点在无从节点连接时自动释放复制积压缓冲区的时间阈值,默认3600秒;超时后清空backlog,导致重连从节点无法部分同步而触发开销巨大的全量同步。477 收藏 -
 PSUBSCRIBE性能瓶颈源于PUBLISH时线性遍历所有pattern做glob匹配。无索引、无缓存、无短路,pattern越多越慢;大小写敏感且*不匹配空字符串,易误配;超20个pattern或100qps即引发CPU毛刺。476 收藏
PSUBSCRIBE性能瓶颈源于PUBLISH时线性遍历所有pattern做glob匹配。无索引、无缓存、无短路,pattern越多越慢;大小写敏感且*不匹配空字符串,易误配;超20个pattern或100qps即引发CPU毛刺。476 收藏 -
 执行replicaofnoone再replicaof不会清空从库数据,仅切换复制源;真正全量同步需确保无运行复制流且master_replid/offset不匹配,必要时手动清空或重启从库。474 收藏
执行replicaofnoone再replicaof不会清空从库数据,仅切换复制源;真正全量同步需确保无运行复制流且master_replid/offset不匹配,必要时手动清空或重启从库。474 收藏 -
 Redis集群不自动随机化过期时间,需业务层实现;限流须在应用层或网关层统一控制;热点key需加扰动后缀分散分片;三者叠加(集群+随机过期+限流)且随机范围≥±5%才有效防雪崩。473 收藏
Redis集群不自动随机化过期时间,需业务层实现;限流须在应用层或网关层统一控制;热点key需加扰动后缀分散分片;三者叠加(集群+随机过期+限流)且随机范围≥±5%才有效防雪崩。473 收藏