Redis技术文章
-
 Redis碎片率超1.5时响应变慢甚至雪崩,根本原因是jemalloc在不连续空闲块中反复查找合适内存块,导致分配延迟升高、CPU波动、GC压力上升并可能引发级联雪崩。457 收藏
Redis碎片率超1.5时响应变慢甚至雪崩,根本原因是jemalloc在不连续空闲块中反复查找合适内存块,导致分配延迟升高、CPU波动、GC压力上升并可能引发级联雪崩。457 收藏 -
 volatile-lru是仅对设置了TTL的key生效的近似LRU淘汰策略,不淘汰无过期时间的key;必须显式配置maxmemory-policy且配合EXPIRE或SETEX使用,否则无效。454 收藏
volatile-lru是仅对设置了TTL的key生效的近似LRU淘汰策略,不淘汰无过期时间的key;必须显式配置maxmemory-policy且配合EXPIRE或SETEX使用,否则无效。454 收藏 -
 是,HLL适合统计日活UV,但需接受约0.81%误差且不支持成员查询与精确交集;按日期分key(如uv:20240520)、设过期、统一用户标识方可稳健使用。453 收藏
是,HLL适合统计日活UV,但需接受约0.81%误差且不支持成员查询与精确交集;按日期分key(如uv:20240520)、设过期、统一用户标识方可稳健使用。453 收藏 -
 不能。Redis6–7.0的ACL不支持Key前缀通配符(如~tenant:a:),仅支持字面Key名或~;7.0起虽有实验性前缀匹配,但生产未验证且不支持嵌套通配。452 收藏
不能。Redis6–7.0的ACL不支持Key前缀通配符(如~tenant:a:),仅支持字面Key名或~;7.0起虽有实验性前缀匹配,但生产未验证且不支持嵌套通配。452 收藏 -
 Redis集群不支持Pub/Sub跨节点广播,因设计上无全局频道路由机制,PUBLISH消息仅被本地订阅者接收;应改用单节点Redis+连接池,或升级至Kafka/Pulsar等专业消息中间件。451 收藏
Redis集群不支持Pub/Sub跨节点广播,因设计上无全局频道路由机制,PUBLISH消息仅被本地订阅者接收;应改用单节点Redis+连接池,或升级至Kafka/Pulsar等专业消息中间件。451 收藏 -
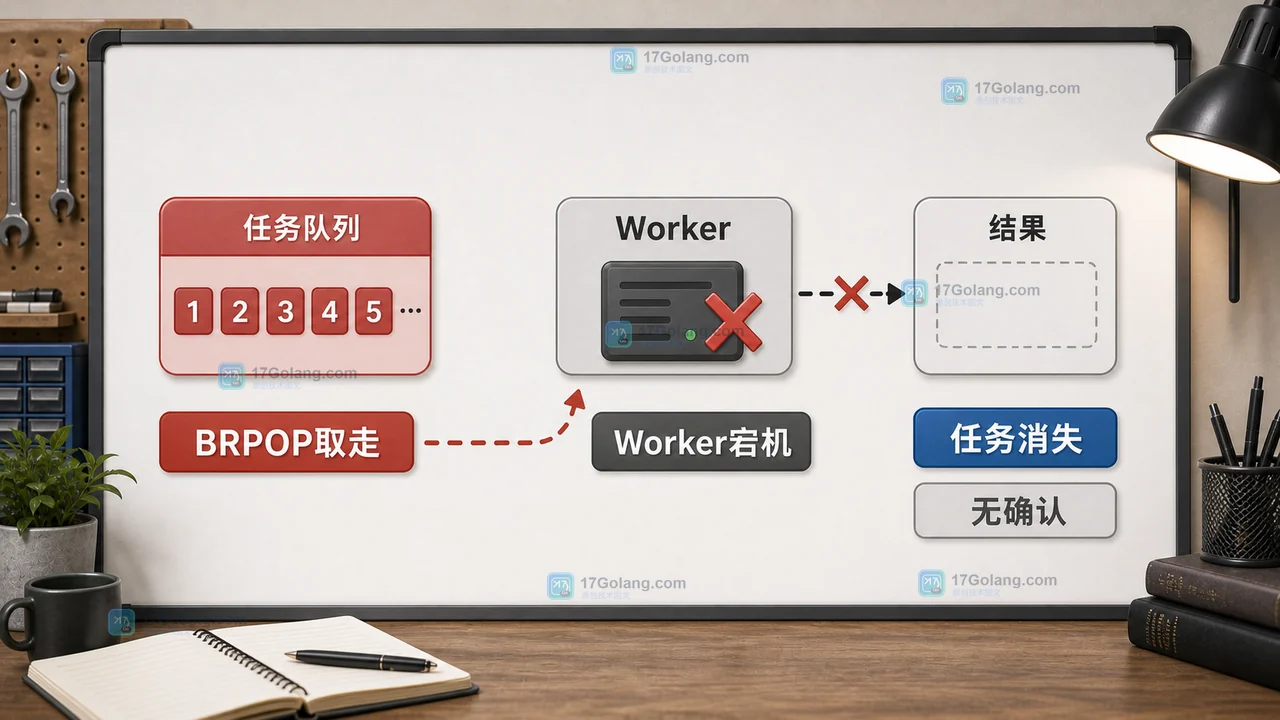 Redis List 用 BRPOP 做任务队列时,Worker 取走任务后宕机会让任务直接消失。更稳的做法是先用 LMOVE 转到处理中队列,业务成功后再 LREM 确认。449 收藏
Redis List 用 BRPOP 做任务队列时,Worker 取走任务后宕机会让任务直接消失。更稳的做法是先用 LMOVE 转到处理中队列,业务成功后再 LREM 确认。449 收藏 -
 预热不充分指预热数据未覆盖真实热点、未执行完或未及时更新,导致上线后2–5分钟内缓存击穿;须用线上采样等动态数据源、分批超时控制、命中率校验及事件驱动机制。445 收藏
预热不充分指预热数据未覆盖真实热点、未执行完或未及时更新,导致上线后2–5分钟内缓存击穿;须用线上采样等动态数据源、分批超时控制、命中率校验及事件驱动机制。445 收藏 -
 RedisPub/Sub不支持优先级,仅为瞬时广播;真正优先级队列需用List+BRPOP多键轮询,按queue:high→queue:medium→queue:low顺序原子消费,Pub/Sub仅作轻量通知触发器。441 收藏
RedisPub/Sub不支持优先级,仅为瞬时广播;真正优先级队列需用List+BRPOP多键轮询,按queue:high→queue:medium→queue:low顺序原子消费,Pub/Sub仅作轻量通知触发器。441 收藏 -
 volatile-ttl策略仅在内存达限且有写入时触发,随机采样已设TTL的key并淘汰其中剩余过期时间最短者,并非主动或精准清理“马上过期”的key。441 收藏
volatile-ttl策略仅在内存达限且有写入时触发,随机采样已设TTL的key并淘汰其中剩余过期时间最短者,并非主动或精准清理“马上过期”的key。441 收藏 -
 Redis 过期键通知适合做自动清理的提醒信号,但不能当成可靠消息队列。更稳的做法是订阅事件触发清理任务,同时保留补偿扫描、幂等门禁、失败重试和告警复盘。441 收藏
Redis 过期键通知适合做自动清理的提醒信号,但不能当成可靠消息队列。更稳的做法是订阅事件触发清理任务,同时保留补偿扫描、幂等门禁、失败重试和告警复盘。441 收藏 -
 RedisTemplate操作Hash返回null的主因是序列化器不一致:key、hashKey、value三者序列化方式必须匹配,尤其hashKey须用StringRedisSerializer,value推荐Jackson序列化,否则反序列化失败或读不到数据。439 收藏
RedisTemplate操作Hash返回null的主因是序列化器不一致:key、hashKey、value三者序列化方式必须匹配,尤其hashKey须用StringRedisSerializer,value推荐Jackson序列化,否则反序列化失败或读不到数据。439 收藏 -
 intset是Redis对全整数小集合的内存优化编码,将整数紧凑存储于连续内存,无指针和字符串头开销,比hashtable节省3–5倍内存;前提为元素均为合法64位有符号整数且数量不超set-max-intset-entries(默认512)。439 收藏
intset是Redis对全整数小集合的内存优化编码,将整数紧凑存储于连续内存,无指针和字符串头开销,比hashtable节省3–5倍内存;前提为元素均为合法64位有符号整数且数量不超set-max-intset-entries(默认512)。439 收藏 -
 直接看INFOclients的qbuf、qbuf-free、obl、oll、omem字段可判断单个客户端流量压力:qbuf高说明命令积压,omem>2MB或qbuf>1MB且持续高位表明高频写入或返回大数据;CLIENTLIST才能定位具体异常客户端,需重点关注qbuf与omem同时偏高、idle小但qbuf大的连接。438 收藏
直接看INFOclients的qbuf、qbuf-free、obl、oll、omem字段可判断单个客户端流量压力:qbuf高说明命令积压,omem>2MB或qbuf>1MB且持续高位表明高频写入或返回大数据;CLIENTLIST才能定位具体异常客户端,需重点关注qbuf与omem同时偏高、idle小但qbuf大的连接。438 收藏 -
 RedisLua脚本原生不支持复杂正则匹配,仅提供基础模式匹配(如%d+),不支持\d、(?i)、.*?、分组捕获等;禁止动态加载外部库(如lrexlib-pcre);推荐在客户端处理或使用RediSearch的FT.SEARCHREGEX。438 收藏
RedisLua脚本原生不支持复杂正则匹配,仅提供基础模式匹配(如%d+),不支持\d、(?i)、.*?、分组捕获等;禁止动态加载外部库(如lrexlib-pcre);推荐在客户端处理或使用RediSearch的FT.SEARCHREGEX。438 收藏 -
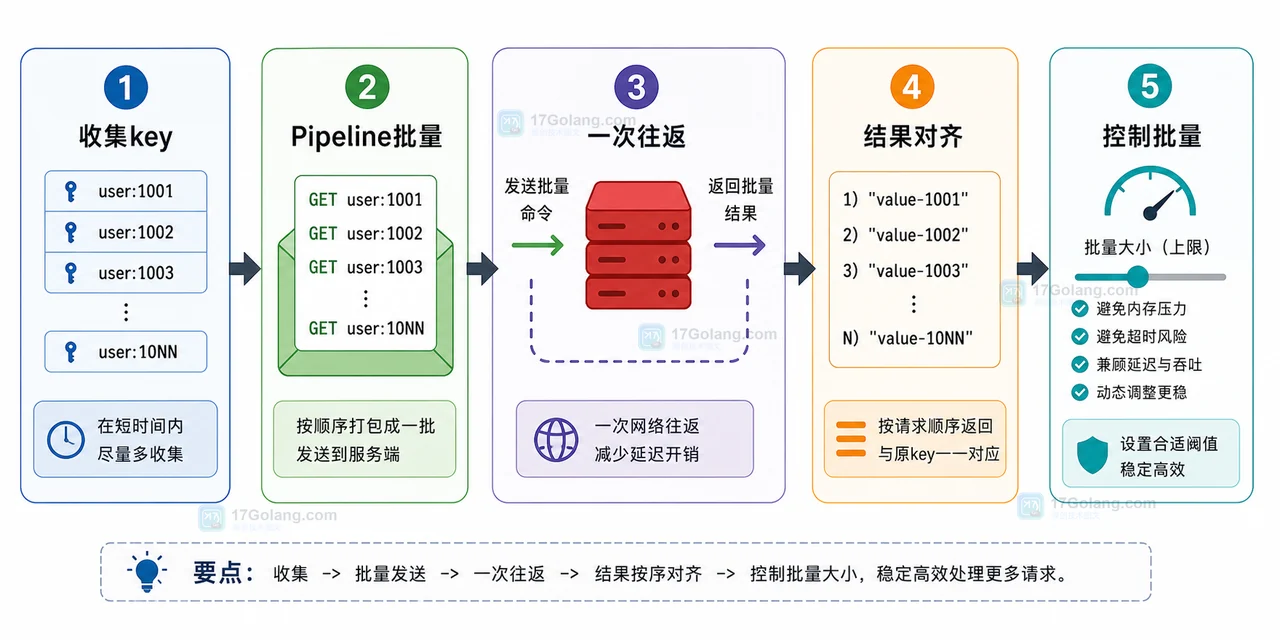 从循环 GET 多个 Redis key 导致接口变慢的现场开始,排查网络往返累积问题,再用 Pipeline、分批窗口和结果顺序对齐优化批量读写。436 收藏
从循环 GET 多个 Redis key 导致接口变慢的现场开始,排查网络往返累积问题,再用 Pipeline、分批窗口和结果顺序对齐优化批量读写。436 收藏