Redis技术文章
-
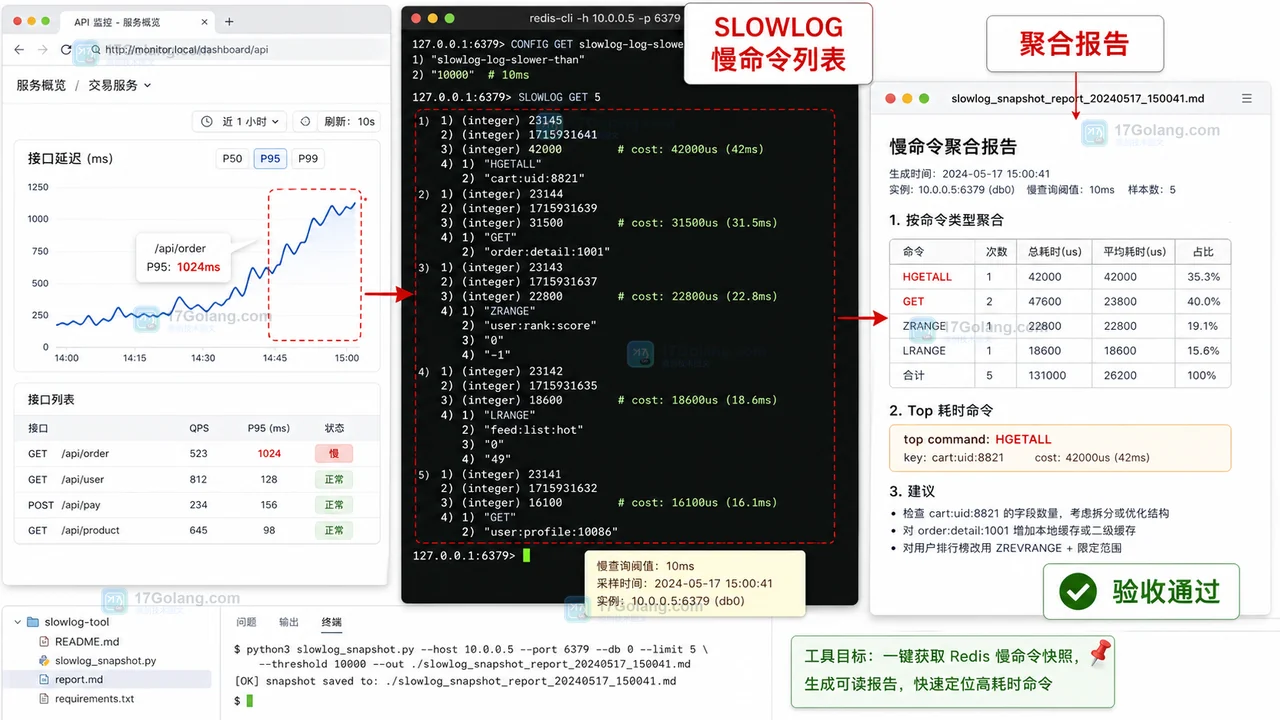 从零做一个 Redis 慢命令快照小工具,采集 SLOWLOG 样本,解析命令耗时和 Key 线索,按命令类型聚合成 Markdown 报告,用于接口延迟排查和上线前验收。501 收藏
从零做一个 Redis 慢命令快照小工具,采集 SLOWLOG 样本,解析命令耗时和 Key 线索,按命令类型聚合成 Markdown 报告,用于接口延迟排查和上线前验收。501 收藏 -
 本文从 Redis 分布式锁偶发并发进入的现场出发,复现旧请求误删新锁的问题,定位锁值缺少身份标记的根因,并用 token 校验方式修复释放锁流程。464 收藏
本文从 Redis 分布式锁偶发并发进入的现场出发,复现旧请求误删新锁的问题,定位锁值缺少身份标记的根因,并用 token 校验方式修复释放锁流程。464 收藏 -
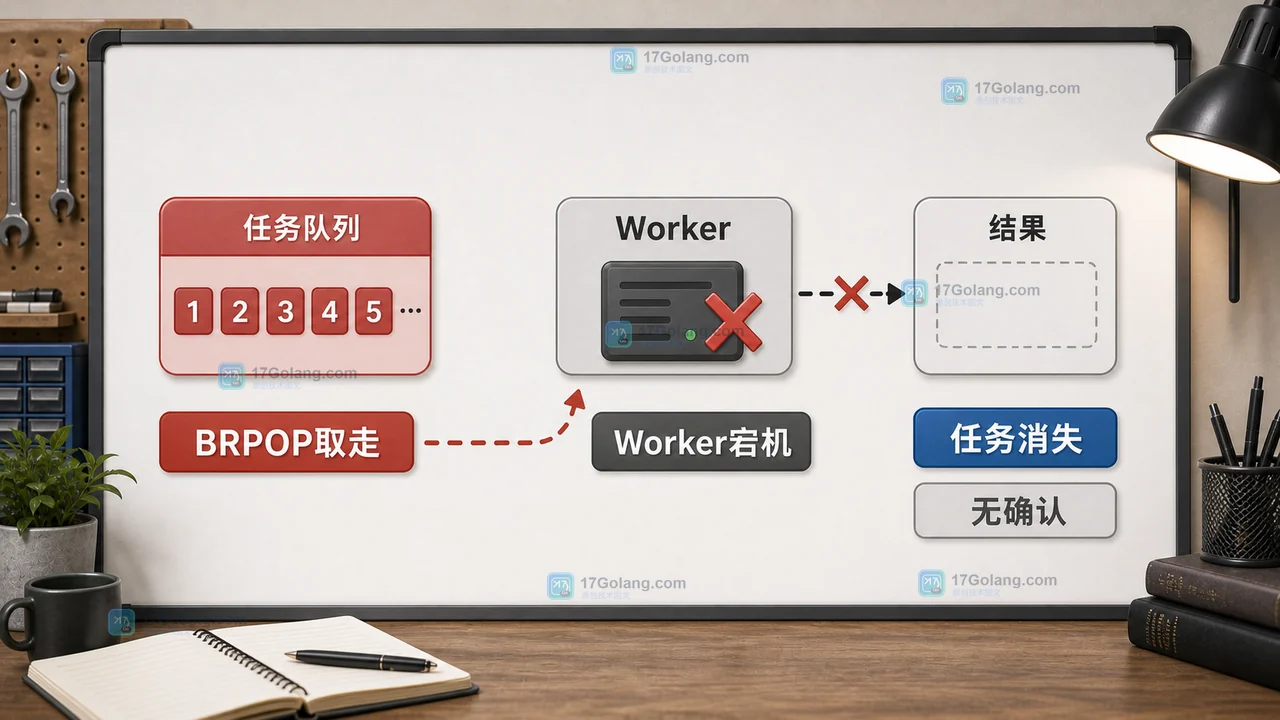 Redis List 用 BRPOP 做任务队列时,Worker 取走任务后宕机会让任务直接消失。更稳的做法是先用 LMOVE 转到处理中队列,业务成功后再 LREM 确认。449 收藏
Redis List 用 BRPOP 做任务队列时,Worker 取走任务后宕机会让任务直接消失。更稳的做法是先用 LMOVE 转到处理中队列,业务成功后再 LREM 确认。449 收藏 -
 Redis 过期键通知适合做自动清理的提醒信号,但不能当成可靠消息队列。更稳的做法是订阅事件触发清理任务,同时保留补偿扫描、幂等门禁、失败重试和告警复盘。441 收藏
Redis 过期键通知适合做自动清理的提醒信号,但不能当成可靠消息队列。更稳的做法是订阅事件触发清理任务,同时保留补偿扫描、幂等门禁、失败重试和告警复盘。441 收藏 -
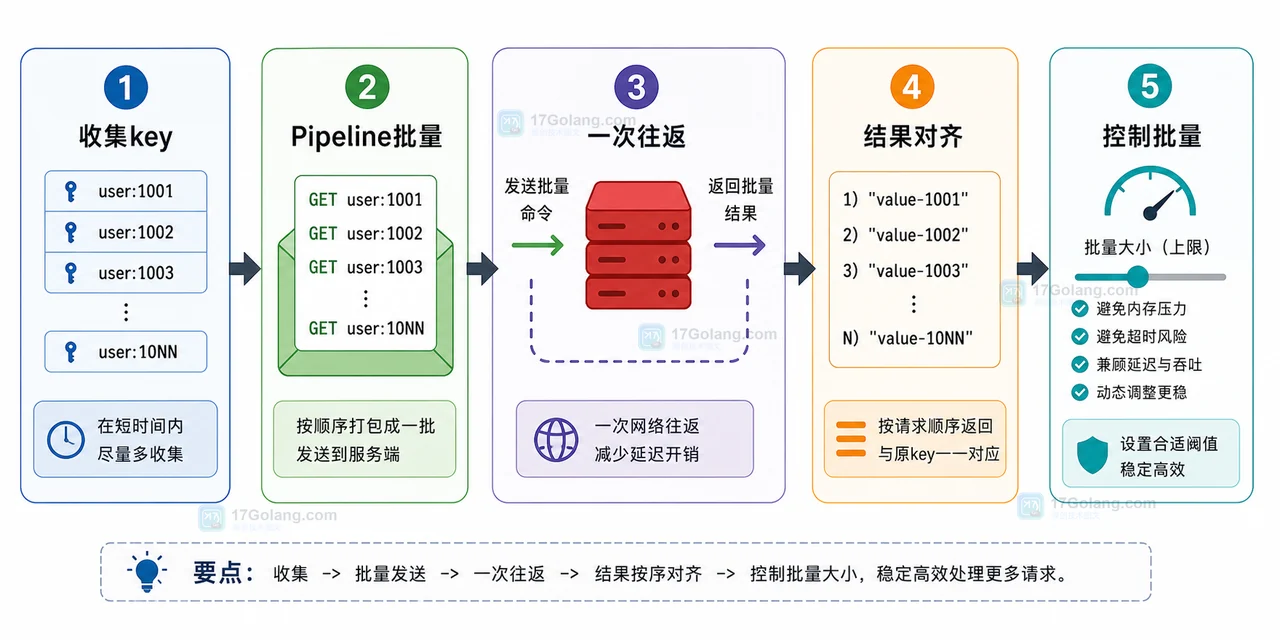 从循环 GET 多个 Redis key 导致接口变慢的现场开始,排查网络往返累积问题,再用 Pipeline、分批窗口和结果顺序对齐优化批量读写。436 收藏
从循环 GET 多个 Redis key 导致接口变慢的现场开始,排查网络往返累积问题,再用 Pipeline、分批窗口和结果顺序对齐优化批量读写。436 收藏 -
 排行榜看起来只是查个 TOP 列表,真正落地时还要处理加分、我的排名、分页、同分规则、周期榜和过期清理。本文按完整工作流拆解 Redis ZSET 排行榜设计。407 收藏
排行榜看起来只是查个 TOP 列表,真正落地时还要处理加分、我的排名、分页、同分规则、周期榜和过期清理。本文按完整工作流拆解 Redis ZSET 排行榜设计。407 收藏 -
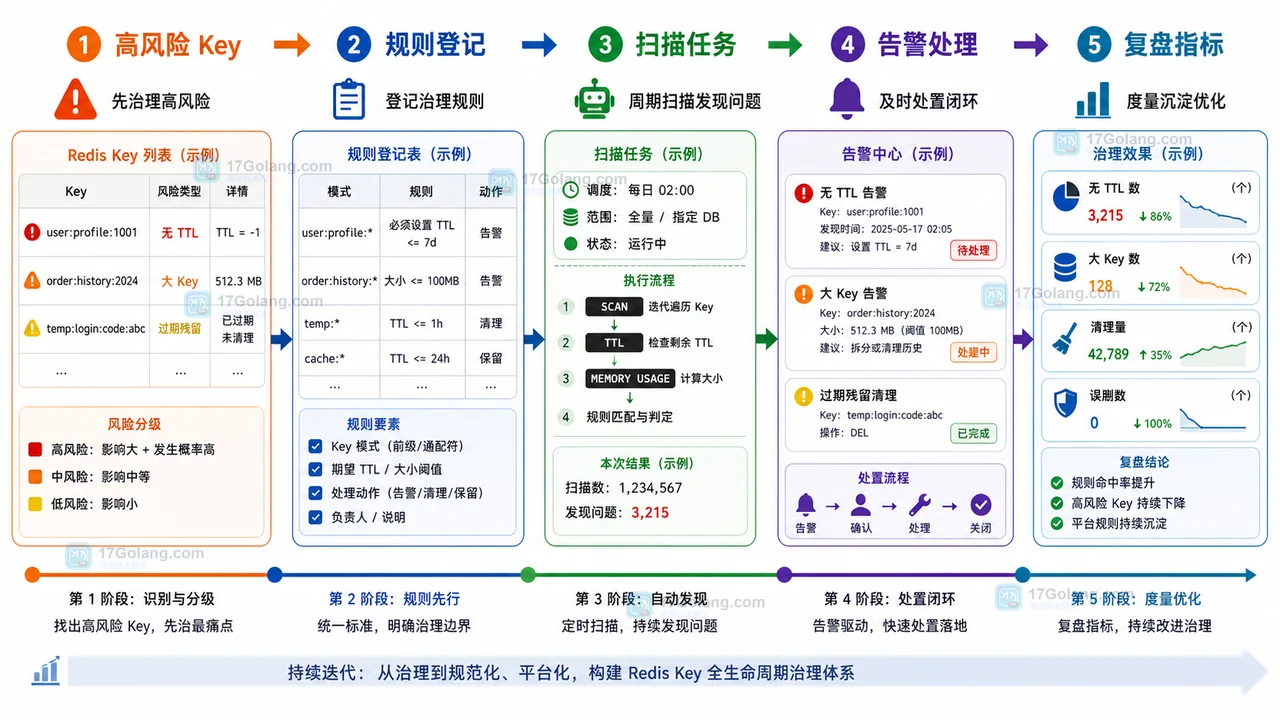 从 Redis Key 生命周期治理趋势入手,分析散落 Key、无 TTL、大 Key 和过期策略带来的问题,给出规则登记、扫描任务、告警处理、复盘指标的渐进式采用路径。400 收藏
从 Redis Key 生命周期治理趋势入手,分析散落 Key、无 TTL、大 Key 和过期策略带来的问题,给出规则登记、扫描任务、告警处理、复盘指标的渐进式采用路径。400 收藏 -
数据库 · Redis | 4星期前 | Redis · Streams · 消费者组 · Pending · XACK · 消息堆积 消费者组 XACK XPENDING XAUTOCLAIM Redis Streams
 Redis Streams 消费者组如果消费者掉线或处理失败,消息会留在 Pending 列表里,表现为队列越积越多。本文从现象复现、XINFO/XPENDING 检查、认领重试到 XACK 确认,完整排查一次消费堆积问题。385 收藏
Redis Streams 消费者组如果消费者掉线或处理失败,消息会留在 Pending 列表里,表现为队列越积越多。本文从现象复现、XINFO/XPENDING 检查、认领重试到 XACK 确认,完整排查一次消费堆积问题。385 收藏 -
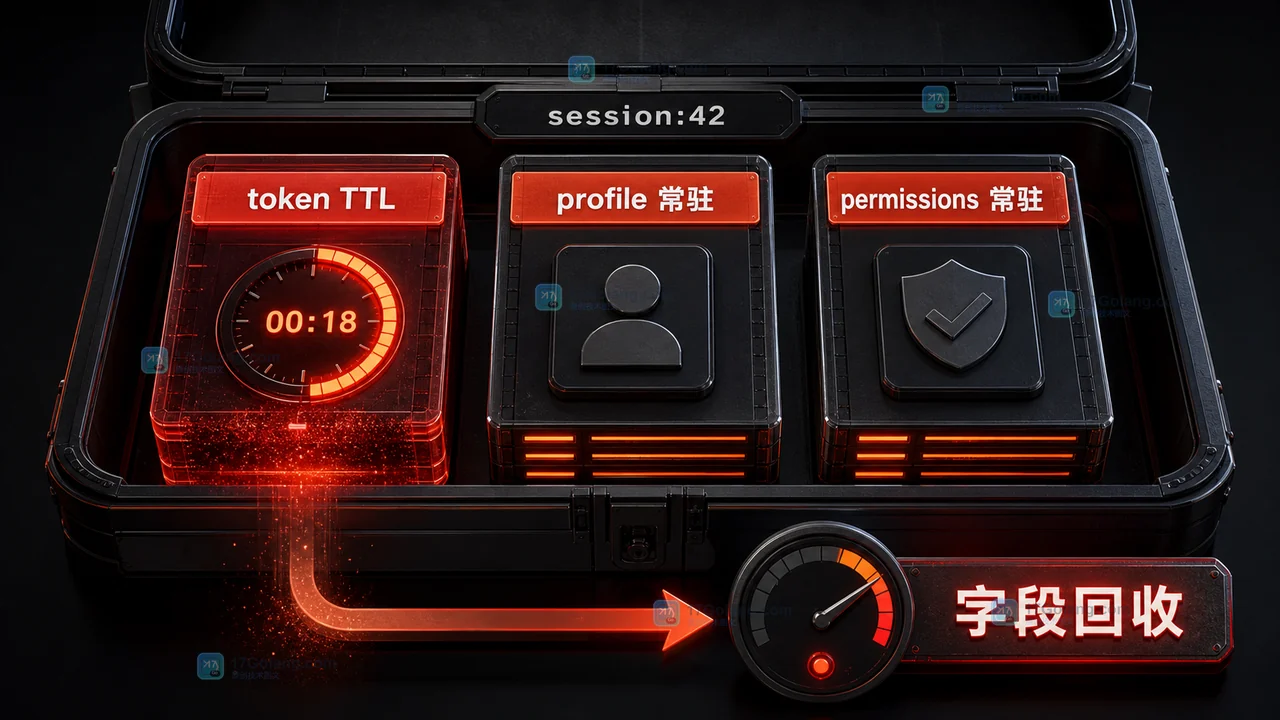 Redis 7.4 起支持给 Hash 的单个字段设置 TTL。本文用会话 token 场景说明 HEXPIRE、HTTL、条件更新和兼容检查,避免为了一个短期字段让整条 Hash 一起过期。366 收藏
Redis 7.4 起支持给 Hash 的单个字段设置 TTL。本文用会话 token 场景说明 HEXPIRE、HTTL、条件更新和兼容检查,避免为了一个短期字段让整条 Hash 一起过期。366 收藏 -
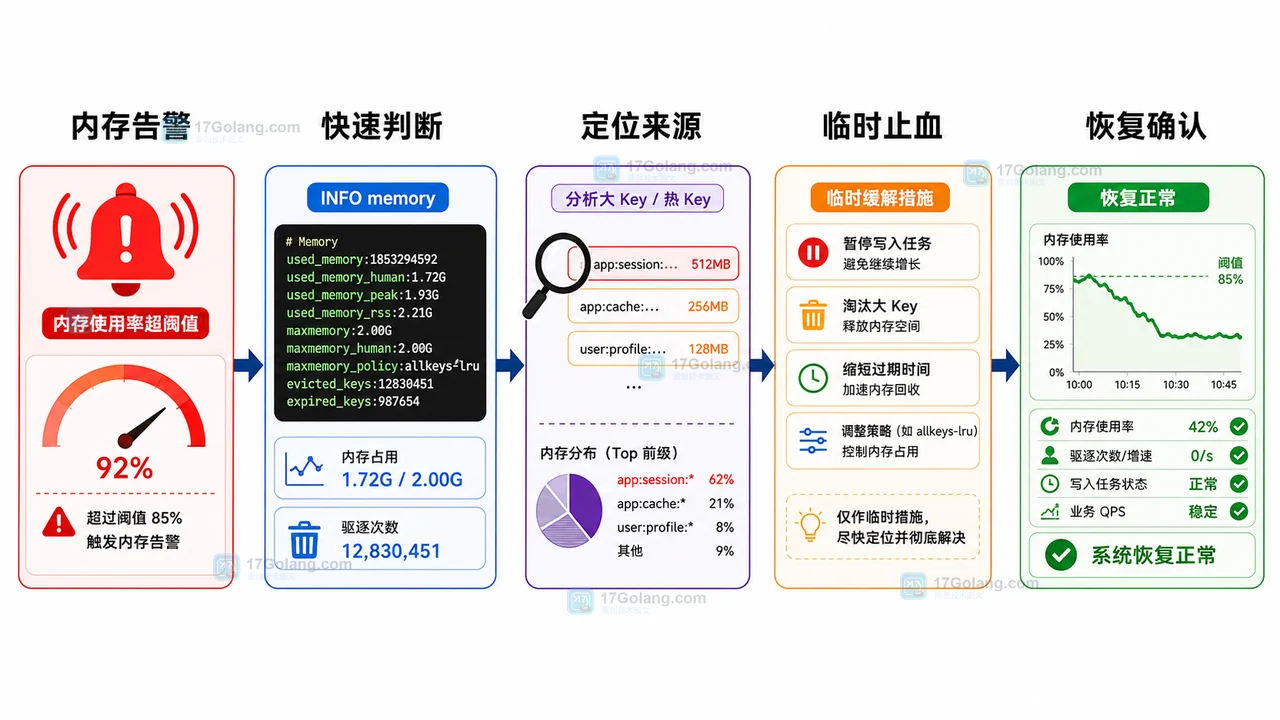 面向线上 Redis 内存告警的运行手册,覆盖触发信号、INFO memory 快速判断、bigkeys 排查、maxmemory 与淘汰策略检查、临时止血、回滚和复盘清单。313 收藏
面向线上 Redis 内存告警的运行手册,覆盖触发信号、INFO memory 快速判断、bigkeys 排查、maxmemory 与淘汰策略检查、临时止血、回滚和复盘清单。313 收藏 -
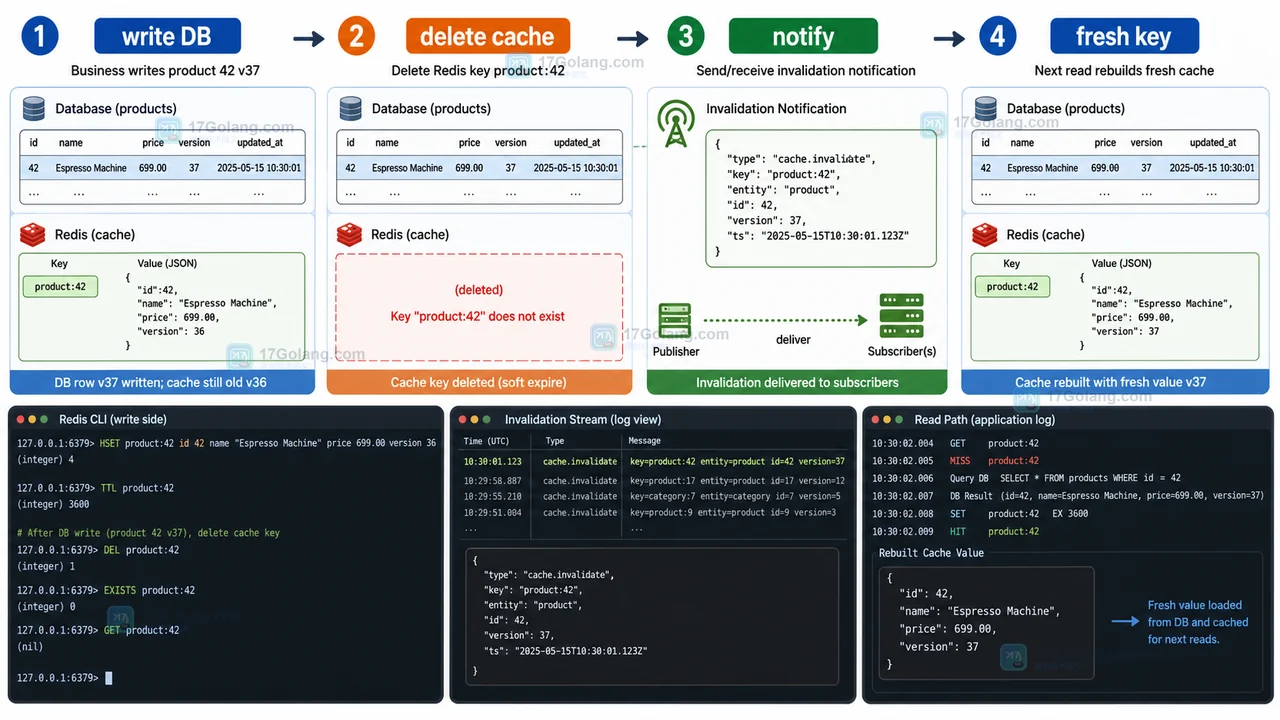 从 Redis 缓存治理趋势出发,分析单一 TTL 的不足,给出软过期、写侧失效通知、新鲜度指标和渐进落地路径,帮助团队在高峰流量下减少脏读窗口。280 收藏
从 Redis 缓存治理趋势出发,分析单一 TTL 的不足,给出软过期、写侧失效通知、新鲜度指标和渐进落地路径,帮助团队在高峰流量下减少脏读窗口。280 收藏 -
 本文从热点 Key 过期导致数据库 QPS 飙升的现场出发,排查 Redis 缓存击穿原因,并用互斥锁、旧值兜底和缓存重建流程修复。235 收藏
本文从热点 Key 过期导致数据库 QPS 飙升的现场出发,排查 Redis 缓存击穿原因,并用互斥锁、旧值兜底和缓存重建流程修复。235 收藏 -
数据库 · Redis | 2星期前 | Redis · 缓存治理 · Keyspace Notifications · 过期事件 · redis Pub/Sub Keyspace Notifications 过期事件 缓存监听 补偿任务
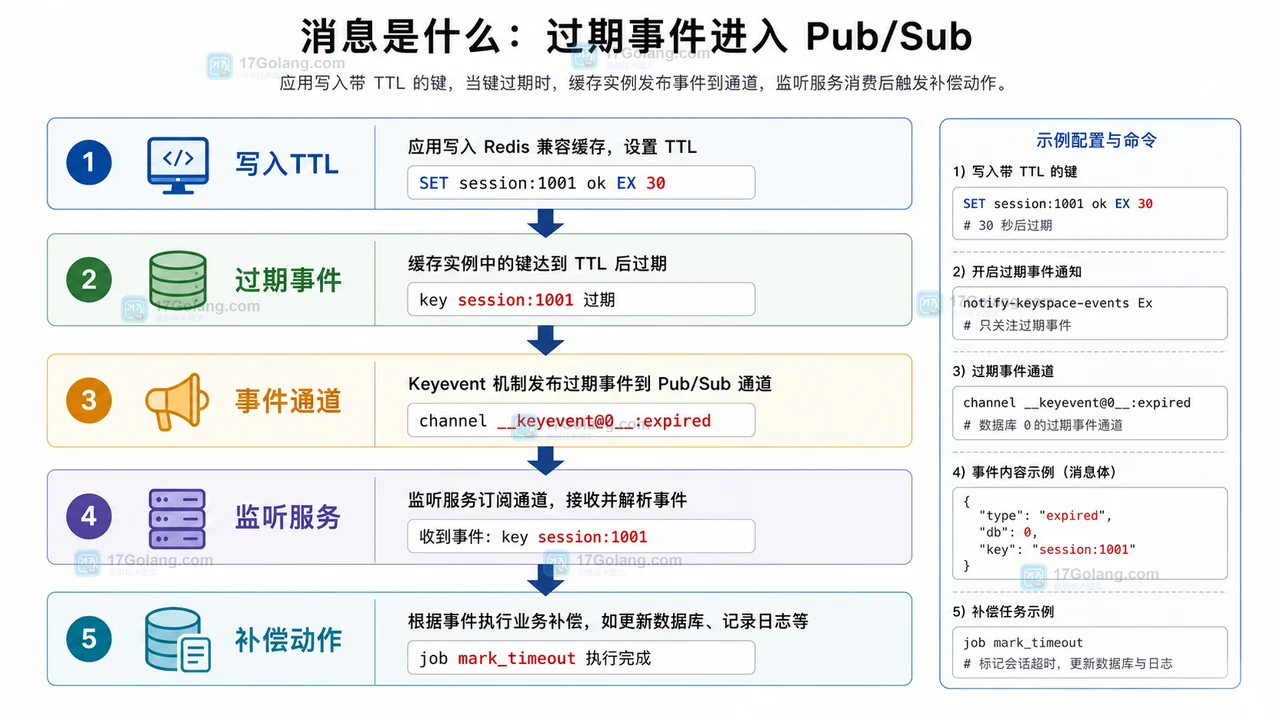 本文用 Redis Keyspace Notifications 演示如何监听过期 Key,配置 notify-keyspace-events,接收 __keyevent@0__:expired 事件,并说明事件通知的丢失风险与补扫兜底做法。181 收藏
本文用 Redis Keyspace Notifications 演示如何监听过期 Key,配置 notify-keyspace-events,接收 __keyevent@0__:expired 事件,并说明事件通知的丢失风险与补扫兜底做法。181 收藏 -
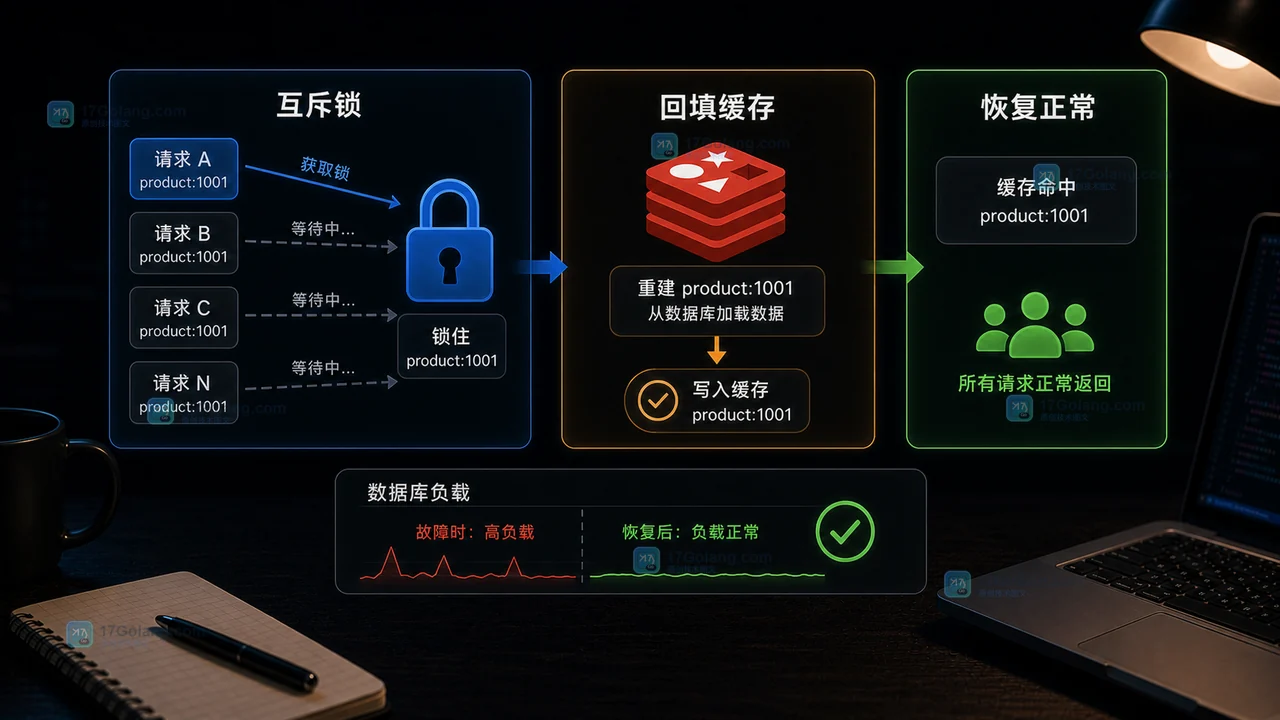 Redis 热点 key 在高并发下同时过期,所有请求会一起回源数据库,表现为 DB QPS 突增、接口超时和 Redis 命中率下降。排查时先看热点 key 的 TTL、命中率和回源日志,修复时用互斥锁、逻辑过期、随机 TTL 和降级保护控制回源压力。119 收藏
Redis 热点 key 在高并发下同时过期,所有请求会一起回源数据库,表现为 DB QPS 突增、接口超时和 Redis 命中率下降。排查时先看热点 key 的 TTL、命中率和回源日志,修复时用互斥锁、逻辑过期、随机 TTL 和降级保护控制回源压力。119 收藏