-
Redis内存使用率过高会导致服务不可用、性能降低和实例崩溃。1)服务器可能拒绝新写操作,2)触发交换分区降低性能,3)实例崩溃影响应用稳定性。预警和优化是关键。
-

Redis启动后无法访问的原因主要包括配置文件问题、网络问题、防火墙设置和内存不足。解决方案如下:1.调整配置文件,确保绑定地址和端口正确;2.修复网络连接,确保Redis服务器和客户端连接正常;3.调整防火墙规则,允许Redis端口访问;4.增加内存或调整Redis配置,确保内存充足。
-

Redis在Golang开发中的应用:如何并发地存取复杂数据结构Redis是一种高效的开源内存数据库,广泛应用于各种不同的应用中。它支持丰富的数据结构,如字符串、哈希、列表、集合和有序集合,使得开发人员可以灵活地存储和查询数据。在Golang开发中,Redis是一个非常有用的工具,能够帮助我们实现高效地并发处理复杂数据结构。本文将介绍如何在Golang中使用
-
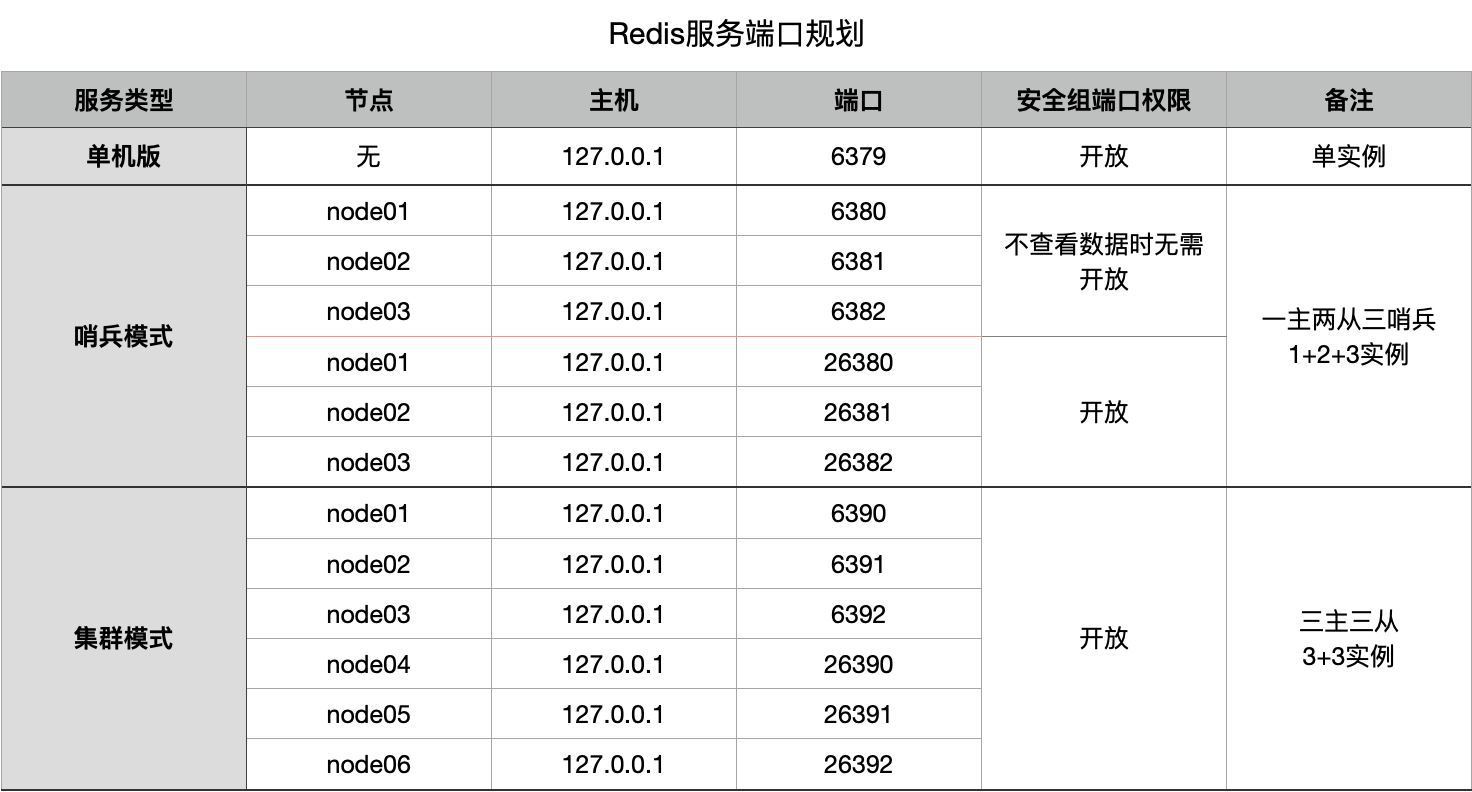
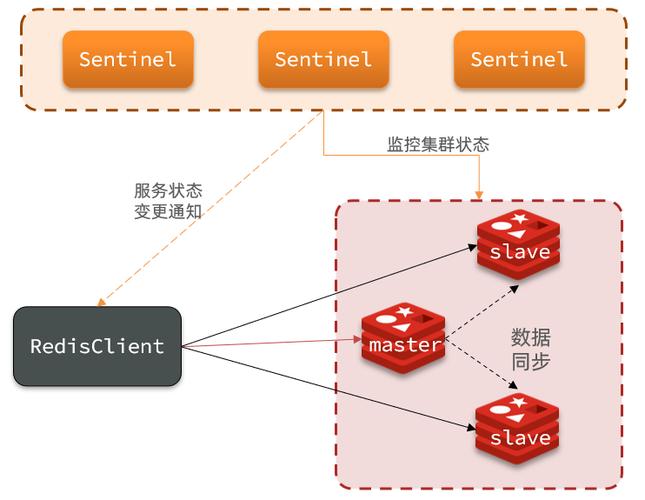
一、序言Redis高可用有两种模式:哨兵模式和集群模式,本文基于哨兵模式搭建一主两从三哨兵Redis高可用服务。1、目标与收获一主两从三哨兵Redis服务,基本能够满足中小型项目的高可用要求,使用Supervisor监控并管理Redis实例。通过本文将完成如下目标:哨兵模式服务规划与搭建哨兵模式服务相比于单机版服务更加可靠,适合读写分离、数据量不是很大、要求可靠稳定性的场景。客户端整合与读写分离通过Spring框架对哨兵模式进行连接,完成生产环境的常见操作。2、端口规划端口规划是完成本方案的第一步。二、单
-

学习如何使用 Redis 和 Python 构建一个位置感知的应用程序。
我经常出差。但不是一个汽车狂热分子,所以当我有空闲时,我更喜欢在城市中散步或者骑单车。我参观过的许多城市都有共享单车
-
前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为productID,value就是具体的customerid集合,后续的话,我就可以
-

Redis默认tcp-keepalive关闭(值为0),需主从双方redis.conf显式配置tcp-keepalive300并重启生效,且须与repl-timeout≥300协同调整,否则连接假活导致复制卡死。
-

彻底禁用RDB自动触发需注释或设为save"",重启或CONFIGREWRITE后CONFIGGETsave返回["save",""],且rdb_changes_since_last_save持续增长即生效。
-

Redis启动后无法访问的原因主要包括配置文件问题、网络问题、防火墙设置和内存不足。解决方案如下:1.调整配置文件,确保绑定地址和端口正确;2.修复网络连接,确保Redis服务器和客户端连接正常;3.调整防火墙规则,允许Redis端口访问;4.增加内存或调整Redis配置,确保内存充足。
-

利用Redis和Golang构建分布式缓存系统:如何快速读写数据引言:在现代应用程序开发中,缓存是提高性能和加速数据访问的重要组成部分。分布式缓存系统能够有效地解决数据访问高延迟的问题,并提供高效的读写操作。本文将介绍如何利用Redis和Golang构建一个简单但高效的分布式缓存系统,并提供代码示例。准备工作首先,我们需要安装Redis和Golang的开发环
-
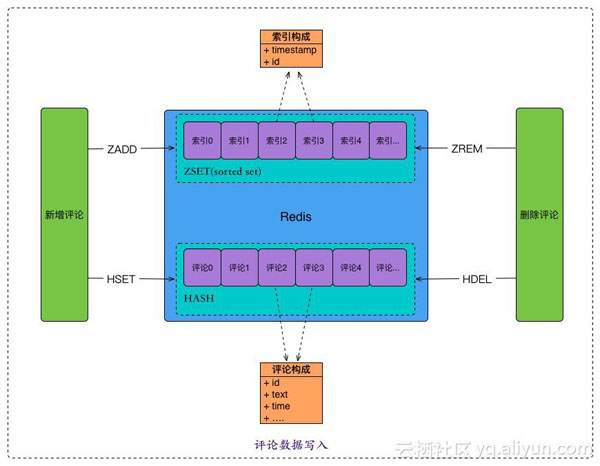
Redis是一个使用范围很广的NOSQL数据库,阿里云Redis同时在公有云和阿里集团内部进行服务,本文介绍了阿里云Redis双11的一些业务场景:微淘社区之亿级关系链存储、天猫直播之评论商品游标分
-
Redis对于Linux是官方支持的,安装和使用没有什么好说的,普通使用按照官方指导,5分钟以内就能搞定。详情请参考:
http://redis.io/download
但有时候又想在windows下折腾下Redis,官方是不支持windows的。
-

Redis短信登录流程描述
短信验证码的发送
用户提交手机号,系统验证手机号是否有效,毕竟无效手机号会消耗你的短信验证次数还会导致系统的性能下降。如果手机号为无效的话就让用户重新
-

sentinelmonitor三要素(master-name、IP、port)必须准确,缺一不可,否则哨兵无法发现主从拓扑;quorum是触发投票的最小同意数,非哨兵总数;密码需三端一致(requirepass/masterauth/auth-pass),ACL还需配置masteruser;down-after-milliseconds宜设3000–5000ms防误判;启动前须确保主从就绪,否则从节点被误标sdown。
-

Redis避免脏读的关键在于其事务机制和乐观锁策略。首先,Redis本身不支持传统数据库的隔离级别,但通过WATCH命令监控键的变化可防止事务执行期间的数据冲突。其次,使用Lua脚本可以实现多个操作的原子性执行,从而避免并发修改带来的数据不一致问题。第三,在并发冲突较少的场景下推荐使用乐观锁(WATCH命令),而在冲突频繁的情况下可考虑采用分布式锁如Redlock来提升一致性保障。综上,虽然Redis无法完全杜绝广义上的脏读,但结合事务、Lua脚本及锁机制可有效降低此类风险。