-

Redis中可以设置数据的过期时间,一旦过期自动删除数据。
1.设置过期时间 expire
127.0.0.1:6379> set name
"ok"
//设置10s后过期,expire单位秒
127.0.0.1:6379> expire name 10
//设置10s后过期,pexpire 单位毫
-
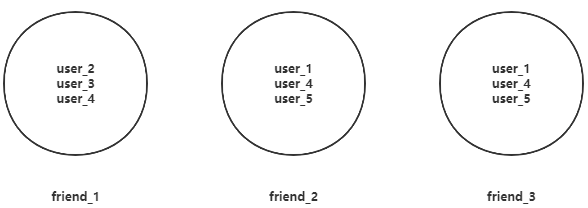
背景
微信朋友圈的点赞、评论,只能看到自己好友的信息。这就涉及到了一个共同好友的概念,通过redis的set集合可以很轻松的实现此功能。
共同好友实现思路
每个人的好友存放在set集
-

面试官:Redis中基本的数据类型有哪些?
我:Redis的基本数据类型有:字符串(string)、哈希(hash)、列表(list)、集合(set)、有序集合(zset)。
面试官:有序集合的内部实现方式是什么?
-

能,但仅限Redis服务器端EVAL/EVALSHA上下文;需用正确日志级别常量和预拼接字符串,且依赖redis.conf中loglevel和logfile配置生效。
-

典型现象是Redis从节点反复断连,日志出现“Clientclosedconnectionduetooutputbufferlimit”,INFOreplication中状态在connect→sync→disconnected循环;主节点因输出缓冲区超限(默认slave256MB/64MB/60s)主动断开连接。
-

通过redis-cli、RedisInsight、Prometheus和Grafana等工具,以及关注内存使用率、连接数、集群节点状态、数据一致性和性能指标,可以有效监控Redis集群的健康状态。
-

选择Redis集合实现数据去重是因为其支持快速插入和查找,且自动去重。1)Redis集合基于有序无重复元素的集合结构,适用于需要快速插入和查询的场景。2)但需注意其内存使用,因为每个元素占用内存。3)可通过分片存储、定期清理和结合其他存储优化使用。
-

监控Redis内存变化的步骤包括:1)使用INFOmemory命令查看当前内存使用情况;2)通过MONITOR命令实时监控命令执行对内存的影响;3)利用慢查询日志间接监控内存变化;4)结合Prometheus和Grafana实现全面监控。
-

如何利用Redis和Haskell实现资源限制功能在现代的网络应用中,对于资源的管理和限制是非常重要的。资源限制可以确保服务器的稳定性,防止滥用和恶意行为。本文将介绍如何利用Redis和Haskell实现资源限制功能,并提供具体的代码示例。Redis简介Redis是一个高性能的键值存储数据库,支持多种数据结构。它提供了丰富的功能,包括存储、计数、过期等等。在
-

利用Redis和JavaScript实现实时数据更新功能在现代的Web应用程序中,实时数据更新功能被广泛使用。例如,社交媒体应用程序需要即时显示新消息;在线游戏需要实时更新用户的分数和位置等信息。为了实现这样的功能,我们可以利用Redis和JavaScript来实现实时数据更新。Redis是一个高性能的内存键值存储数据库,适用于缓存、消息传递和实时分析等场景
-

Redis与Objective-C开发:构建高效的移动应用后端随着移动应用的兴起,构建高效的移动应用后端变得越来越重要。Redis是一个开源的内存数据库,它提供了一个高效的键值存储系统,广泛应用于各种应用场景。而Objective-C是iOS开发中最常用的语言,拥有强大的功能和灵活的开发环境。本文将介绍如何使用Redis和Objective-C开发构建高效的
-

redis适合什么场景?
1、缓存
缓存现在几乎是所有中大型网站都在用的必杀技,合理的利用缓存不仅能够提升网站访问速度,还能大大降低数据库的压力。Redis提供了键过期功能,也提供了灵活
-
创建限流组件项目
pom.xml文件中引入相关依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
-

Redis禁止BGSAVE与BGREWRITEAOF并发执行,是为避免双子进程争抢CPU、I/O、COW内存页及fsync队列;前者返回错误,后者被排队;no-appendfsync-on-rewriteyes可缓解AOF重写时主进程fsync阻塞,但对BGSAVE无效。
-

Redis在高并发环境下的性能调优可以通过以下步骤实现:1.内存管理:使用maxmemory和maxmemory-policy配置,建议使用allkeys-lru策略。2.网络I/O优化:调整tcp-backlog和client-output-buffer-limit配置。3.持久化优化:调整rdb和aof的配置,平衡性能和数据安全。4.集群和分片:使用RedisCluster或Codis分散数据。5.客户端优化:使用连接池和批处理命令如pipeline或mget/mset。通过这些措施,可以确保Redi