-

RedisHash最适合存购物车,因其天然支持按商品ID(field)原子增减、查询、删除;HINCRBY可安全±数量并自动初始化为0,但需应用层校验负数;key为cart:{user_id},value仅存整数数量,过期用EXPIRE设置。
-

Redis延迟高但CPU正常通常是网络丢包或抖动所致,表现为redis-cli--latency毛刺飙升、ping标准差>10ms或丢包率>0.1%,需用tcpdump抓包分析重传与ACK丢弃,并排查云环境安全组、NAT会话老化及内核TCP参数配置。
-

RedisPub/Sub监控需聚焦连接行为与资源消耗:用PUBSUBNUMSUB查实时订阅数,instantaneous_output_kbps和client_longest_output_list组合判断积压,connected_clients与connections_received_per_sec协同识别频繁重连。
-

redis持久化机制,将内存中的数据存储到硬盘中,方便数据的持续存在。redis支持两种持久化方式,Snapshotting(快照)和Append-onlyfile(AOF)方式:1.快照是默认的持久化方式。它将内存中的数据以快照的方式写入二进制文件中,默认的文件名为dump.rdb。2.AOF方式由于快照是在一定时间间隔做一次的,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改。如果应用要求不能丢失任何修改的话,则可以采用aof持久化方式。AOF有更好的持久化是因为redis会将每
-

NoSQL的四大种类
NoSQL数据库在整个数据库领域的江湖地位已经不言而喻。在大数据时代,虽然RDBMS很优秀,但是面对快速增长的数据规模和日渐复杂的数据模型,RDBMS渐渐力不从心,无法应
-

Redis 在当前的技术社区里是非常热门的。从来自 Antirez 一个小小的个人项目到成为内存数据存储行业的标准,Redis已经走过了很长的一段路。
1、停止使用 KEYS *
Okay,以挑战这个命令开始这篇文
-
win 7 安装redis服务
Redis官方是不支持windows的,只是 Microsoft Open Tech group 在 GitHub上开发了一个Win64的版本,项目地址是: https://github.com/MSOpenTech/redis
win 7 安装redis服务目录下载 redis安装 redis解压文
-

选择Redis集合实现数据去重是因为其支持快速插入和查找,且自动去重。1)Redis集合基于有序无重复元素的集合结构,适用于需要快速插入和查询的场景。2)但需注意其内存使用,因为每个元素占用内存。3)可通过分片存储、定期清理和结合其他存储优化使用。
-

RedisCluster集群的节点规划与部署需要至少3个主节点和建议的3个从节点,确保高可用性和可扩展性。1)节点数量:至少3主3从。2)硬件资源:每个节点至少8GB内存。3)网络拓扑:节点应部署在同一数据中心或低延迟网络。4)部署步骤包括安装Redis、配置Redis、启动节点、创建集群和验证状态。
-

Redis与Kubernetes集群的集成通过部署Redis实例、确保高可用性和管理监控来实现。1)使用StatefulSet部署Redis实例,提供稳定的网络标识和持久存储。2)通过RedisSentinel或RedisCluster实现高可用性。3)使用Prometheus和Grafana进行管理和监控,确保系统的高效运行和问题及时解决。
-

解决Redis启动时内存分配不足问题的方法包括:1.检查系统内存使用情况,必要时增加物理内存或调整Redis配置;2.修改redis.conf文件中的maxmemory参数,限制Redis内存使用;3.配置maxmemory-policy参数,选择合适的内存回收策略;4.增加swap空间或禁用Redis的swap使用;5.通过RedisCluster分散数据存储,降低单节点内存压力;6.使用MEMORYUSAGE命令查找并处理大key。
-

需要关注Redis的版本更新,因为它能带来性能提升、安全补丁和新功能。检查Redis版本是否需要升级的步骤包括:1.使用命令“redis-cli--version”查看当前版本;2.与Redis官方版本对比;3.评估新功能、性能提升、安全补丁和兼容性;4.遵循备份数据、测试环境、逐步升级和监控日志的最佳实践。
-
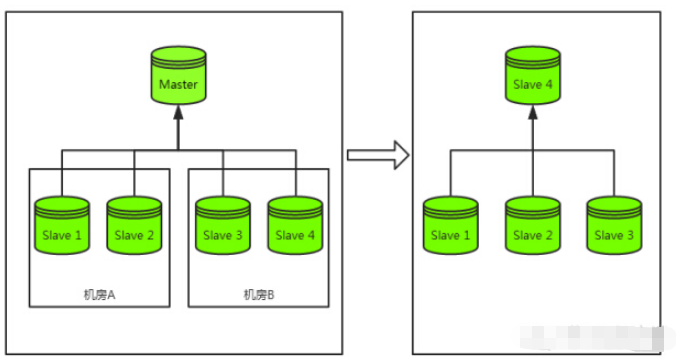
1主库宕机先来看一下主库宕机容灾过程:如下图在主库宕机的时候,我们最常见的容灾策略为“切主”。具体为从该集群剩余从库中选出一个从库并将其升级为主库,该从库升级为主库后再将剩余从库挂载至其下成为其从库,最终恢复整个主从集群结构。以上是一个完整的容灾过程,而代价***的过程为从库的重新挂载,而非主库的切换。这是因为redis无法像mysql、mongodb那样基于同步的点位在主库发生变化后从新的主库继续同步数据。在redis集群中一旦从库换主,redis的做法是将更换主库的从库清空然后从新主库完整同步一份数据
-

关闭SWAPSWAP是内存交换技术。将内存按页,复制到预先设定的磁盘空间上。内存是快速的,昂贵的。而磁盘是低速的,廉价的。通常使用SWAP越多,系统性能越低。Redis是内存数据库,使用SWAP会导致性能快速下降。建议留有足够内存,并关闭SWAP。
-

Redis作为缓存数据库的优化策略与性能测试随着互联网的快速发展,数据的处理和存储需求越来越高,对于网站和应用程序来说,减少响应时间成为了一项必须要解决的问题。缓存技术作为一个提高响应速度的方案,已成为了一个不可或缺的手段。而Redis作为一种基于内存的高性能键值存储系统,已成为了选择缓存数据库的首选技术之一。本文将着重探讨Redis作为缓存数据库的优化策略