-

随着电商业务的发展,电商平台的并发读写访问量急速增长,传统的关系型数据库在高并发环境下面临着许多挑战。为了解决这些挑战,越来越多的电商平台开始使用NoSQL数据库,其中包括Redis。在本文中,我们将介绍Redis在电商平台中的应用实例。什么是Redis?Redis是一种内存数据存储系统,它支持多种数据结构,包括字符串、哈希、列表、集合和有序集
-
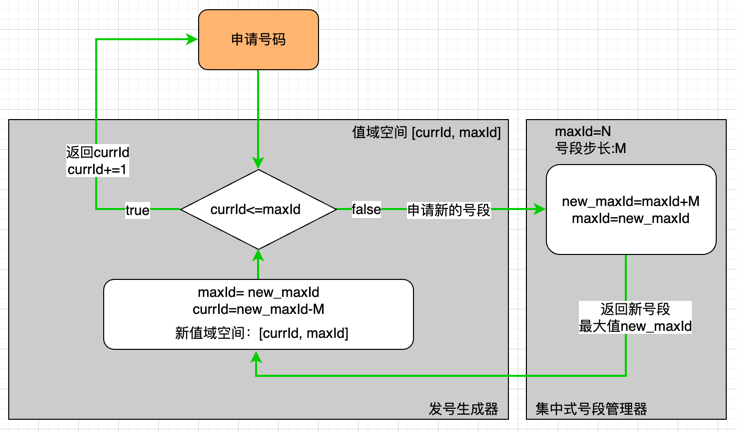
什么是发号器在互联网场景中,很多业务要求生成唯一的ID号,以用于区分某些资源。常见例子:电商系统中的订单ID号、聊天群组中的消息ID号、上传文件到存储系统中之后生成的文件ID号、用
-
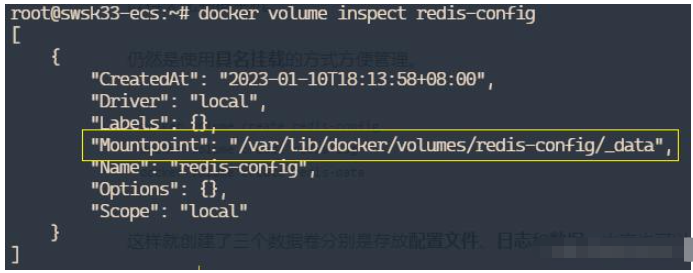
1,拉取镜像通过下列命令:docker pull redis2,创建数据卷通常,类似于MySQL,Redis作为数据库,我们最好还是需要将其配置和数据等等挂载到数据卷以持久化到宿主机。仍然是
-

通过调整Redis的配置参数可以显著提高其读写性能。1.内存管理:设置maxmemory为10GB,maxmemory-policy为allkeys-lru。2.网络通信:调整tcp-backlog为511,timeout为0。3.持久化:设置RDB快照频率为save9001、save30010、save6010000,AOF的appendfsync为everysec。
-

应从单节点Redis升级到集群模式,因为单节点在处理大规模数据和高并发请求时会遇到瓶颈,而集群模式通过分片和高可用性解决这些问题。升级步骤包括:1.评估现有数据量和访问模式,规划分片策略;2.准备新的集群环境,使用redis-cli--clustercreate命令创建集群;3.将数据迁移到集群,可使用MIGRATE命令或RDB快照方法;4.更新客户端连接逻辑,使用如redis-py-cluster库;5.实施分批迁移策略,监控数据一致性和系统性能;6.优化性能,设置监控和告警,制定故障恢复计划。通过这些
-

Redis集群数据分片的原理是通过哈希槽实现数据的分布式存储。1)Redis集群将键空间划分为16384个哈希槽,每个键通过CRC16校验和后对16384取模,决定所属哈希槽。2)每个Redis节点负责一部分哈希槽,实现数据分片。3)这种设计支持动态调整集群规模,通过迁移部分哈希槽添加或移除节点。
-

解决Redis启动时内存分配不足问题的方法包括:1.检查系统内存使用情况,必要时增加物理内存或调整Redis配置;2.修改redis.conf文件中的maxmemory参数,限制Redis内存使用;3.配置maxmemory-policy参数,选择合适的内存回收策略;4.增加swap空间或禁用Redis的swap使用;5.通过RedisCluster分散数据存储,降低单节点内存压力;6.使用MEMORYUSAGE命令查找并处理大key。
-

解决Redis启动时内存分配不足问题的方法包括:1.检查系统内存使用情况,必要时增加物理内存或调整Redis配置;2.修改redis.conf文件中的maxmemory参数,限制Redis内存使用;3.配置maxmemory-policy参数,选择合适的内存回收策略;4.增加swap空间或禁用Redis的swap使用;5.通过RedisCluster分散数据存储,降低单节点内存压力;6.使用MEMORYUSAGE命令查找并处理大key。
-

随着互联网的发展,许多应用程序需要对各种请求进行限流。这是因为在高并发的情况下,应用程序会遭受大量请求的压力,导致服务崩溃或响应变慢。为了解决这个问题,开发者们通常会使用分布式限流技术来控制请求的流量,保证服务的高可用性和稳定性。而Redis作为一款高性能内存数据存储系统,是常用的分布式限流方案之一。本文将介绍Redis实现分布式限流的原理和实现方式。一、什
-
1.不支持带密码,设置indexdb的reids
2.5.6以及以前的会有这个问题,最新的版本已经解决了这个问题了,但是还是存在一个坑,就是必须得设置用户名(大家都知道redis验证不需要用户名),如URL
-

扩展Redis集群节点的步骤包括:1.准备新节点,确保配置一致;2.使用redis-cli工具将新节点加入集群;3.重新分配槽位以均匀分布数据。在此过程中,需要注意数据迁移、故障处理、性能监控、槽位分配策略和成本效益,确保扩展操作顺利进行。
-

常用的Redis性能监控工具包括Redis自带的INFO命令、慢查询日志、RedisInsight、Prometheus和Grafana组合以及Redis-benchmark。1.INFO命令适合快速诊断问题,但数据粒度较粗。2.慢查询日志有助于优化性能,但配置需谨慎。3.RedisInsight提供直观的监控和分析功能,但需考虑资源消耗。4.Prometheus和Grafana组合适用于大规模集群监控和长期趋势分析,部署复杂。5.Redis-benchmark用于测试性能极限,需结合实际业务场景分析。
-

Redis如何实现消息队列功能随着互联网的发展,消息队列在分布式系统中变得越来越重要。消息队列允许不同的应用程序之间通过异步通信来传递和处理消息,提高了系统的可伸缩性和可靠性。Redis作为一款快速、可靠、灵活的内存数据库,也可以用来实现消息队列的功能。本文将介绍Redis如何实现消息队列功能,并提供一些具体的代码示例。一、使用RedisList数据结构R
-

本文来自Redis在Google Group上的一个问题,有一位同学发贴求助,说要解决如下的一个问题:他有一个IP范围对应地址的列表,现在需要给出一个IP的情况下,迅速的查找到这个IP在哪个范围,也就
-

应使用HSET分字段存储用户资料而非SET存JSON,因其支持原子性单字段操作、避免并发覆盖、节省带宽;字段名须全小写下划线;慎用HGETALL防性能陷阱;Hash无内置TTL,需显式EXPIRE。