-

先看一下Redis是一个什么东西。官方简介解释到:
Redis是一个基于BSD开源的项目,是一个把结构化的数据放在内存中的一个存储系统,你可以把它作为数据库,缓存和消息中间件来使用。同时支
-

背景
公司的redis有时background save db不成功,通过log发现下面的告警,很可能由它引起的:
[13223] 17 Mar 13:18:02.207 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this iss
-

缓存空值TTL推荐2–5分钟,用SETEX或set(key,"NULL",300,TimeUnit.SECONDS),避免永不过期或24小时;内容用"NULL"等明确标记,前置参数校验更早拦截无效请求。
-

在用户签到系统中使用Redis位图是一个好主意,因为它提供了高效的内存使用和快速的统计查询功能。具体来说,Redis位图通过位(bit)表示用户的签到状态,支持快速统计连续签到天数和月度签到情况,同时需要注意数据持久化和性能优化。
-

Redis的默认配置不安全,应配置防火墙规则以限制连接源。1)使用iptables规则允许特定子网访问Redis端口并拒绝其他连接。2)基于应用程序服务器位置限制访问源。3)使用TLS/SSL加密通信。4)定期审计和更新规则。5)监控和分析日志。6)考虑使用RedisSentinel。
-
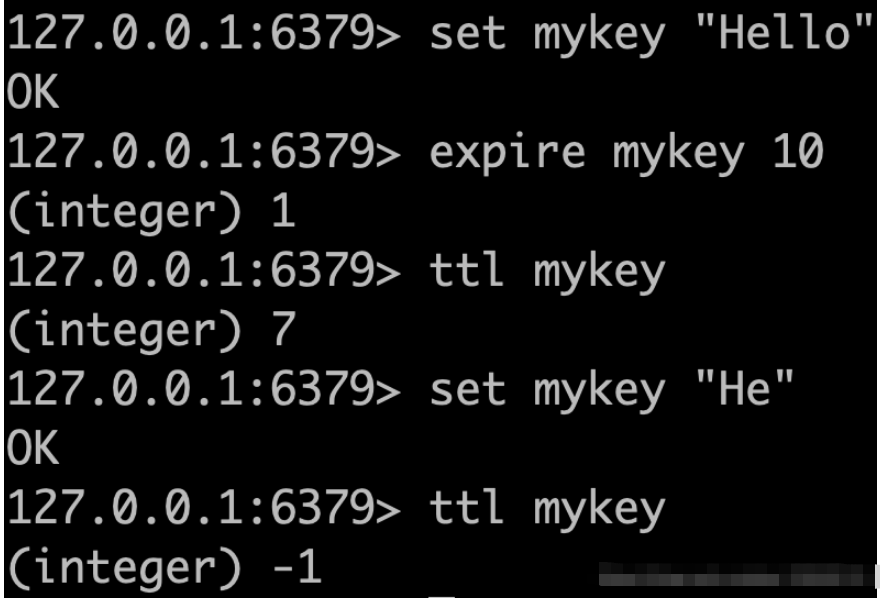
1设置带过期时间的keyexpirekeyseconds时间复杂度:O(1)设置key的过期时间。超时后,将会自动删除该key。在Redis的术语中一个key的相关超时是volatile的。超时后只有对key执行DEL、SET、GETSET时才会清除。这意味着,从概念上讲所有改变key而不用新值替换的所有操作都将保持超时不变。例如,使用INCR递增key的值,执行LPUSH将新值推到list中或用HSET改变hash的field,这些操作都使超时保持不变。使用PERSIST命令可以清除超时,使其变成一个永
-
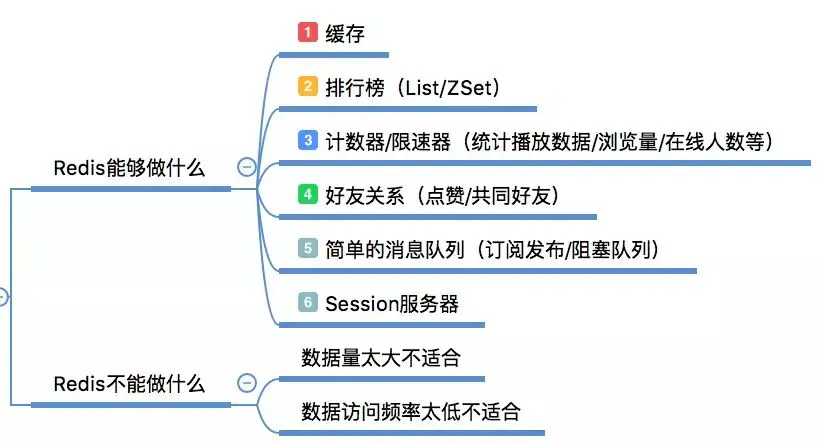
Redis常用命令总结:包括时间复杂度总结与具体数据类型在Redis内部使用的数据结构;Redis的高级功能:包括持久化、复制、哨兵、集群介绍;理解Redis:理解内存、阻塞;这部分是非常重要的,前面介绍的都可以成为术,这里应该属于道的部分;开发技巧:主要是一些开发实战的总结,包括缓存设计与常见坑点。先来开启第一部分的内容,对Redis来一次重新打量。本系列内容基于:redis-3.2.12Redis不是万金油在面试的时候,常被问比较下Redis与Memcache的优缺点,个人觉得这二者并不适合一起比较,
-

Redis:高速缓存技术的巅峰之作引言在当今时代的互联网应用开发中,高速缓存技术的重要性日益凸显。为了满足用户对于实时性和并发性的需求,开发人员需要定期地考虑如何优化应用的性能。而在众多的缓存技术中,Redis凭借其卓越的性能和可靠性,成为了开发者们钟爱的选择。一、Redis的简介Redis是一个开源的、数据结构服务器,旨在提供快速、高效、高可用的数据访问。
-

Redis与Groovy开发:简化持久化操作的实现概述:在软件开发过程中,持久化操作是不可避免的一部分。传统的数据库在处理持久化操作时,会存在较大的繁琐性和性能问题。Redis是一种基于内存的数据结构存储系统,它提供了快速、可靠且灵活的持久化方案。结合使用Redis和Groovy可以更好地简化持久化操作的实现。Redis简介:Redis是一种高性能的键值存储
-

Redis是一个快速的内存数据结构存储系统,可以用来存储和访问数据,而搜索引擎是一种用于搜索并返回文档或网页等内容的工具。在搜索引擎的应用场景中,Redis可以作为一个关键的组件,用
-

固定窗口使用Redis实现固定窗口比较简单,主要是由于固定窗口同时只会存在一个窗口,所以我们可以在第一次进入窗口时使用pexpire命令设置过期时间为窗口时间大小,这样窗口会随过期时间而失效,同时我们使用incr命令增加窗口计数。因为我们需要在counter==1的时候设置窗口的过期时间,为了保证原子性,我们使用简单的Lua脚本实现。constfixedWindowLimiterTryAcquireRedisScript=`--ARGV[1]:窗口时间大小--ARGV[2]:窗口请求上限localwind
-

Redis是一种高性能的分布式内存数据库,常用于缓存、消息队列等场景,但它的实时数据处理能力也非常强大。本文将介绍Redis在实时数据处理方面的应用实例。一、页面访问计数器在网站的实时数据处理中,页面访问计数器是一项非常重要的功能。通过实时计数器,网站管理员可以及时了解到网站的访问量、用户活跃度等数据,并根据这些数据进行相应的优化。而Redis作为一个快速的
-

那什么是基数?
比如有两个数组
数组A = [1,2,3,4,5];
数组B = [3,4,5,6,7];
这时候基数就是 [1,2,3,4,5,6,7],总共有7个数;
就是去重之后的数据;
HyperLogLog 就是用来做去重复统计的;
bitmap
-

RedisPub/Sub不适合异步任务处理,因其无确认机制、无持久化、不支持消费者组与积压缓冲;应选用LPUSH+BRPOP或XADD+XREADGROUP(Stream)实现可靠任务队列。
-

ZADD的score不能用时间戳,因同分排序不稳定且时间戳递增违背“分数越高名次越靠前”逻辑;应使用业务分数(如积分)并利用ZADD覆盖更新、ZINCRBY原子累加、ZREM安全删除。