-

Redis是一种高性能的键值数据库,适用于许多不同的用例。尤其在微服务架构中,Redis是不可或缺的。本文将介绍Redis在微服务架构中的应用实践,并讨论为什么它是如此重要。缓存API调用微服务架构中,服务通信的开销是非常显著的。一个服务调用可能需要跨越多个网络和服务器,这种开销往往会影响性能和响应时间。缓存是为了减轻这种负担,提高性能的一项关键技术。Red
-

Redis是一款高性能内存数据库,被广泛应用于分布式系统中。它提供了丰富的数据结构和强大的缓存能力,可以支持多种应用场景,如缓存、实时计算、队列等。在分布式数据处理中,Redis的数据分片和Replication机制使其成为了一种常见的数据存储解决方案。但是,Redis的分布式部署和数据处理也存在一些问题,需要在测试和调试过程中进行充分的考虑和处理。一、Re
-

应先检查是否连接泄露,再调整maxclients:通过redis-cliclientlist确认连接是否持续增长,修复Jedis未close问题;若确需扩容,须同步调高系统ulimit-n并重启Redis。
-

ZREM不能直接删除Geo数据,因为它只删除ZSET中的member名称,而非按经纬度范围删除;必须先用GEORADIUS等命令查询出目标member,再调用ZREM精确删除。
-

要定位被淘汰的key,需监控evicted_keys增量、expired_keys飙升情况,并结合Redis7.0+的MEMORYUSAGE与OBJECTFREQ抽样分析;allkeys-lru不安全,应优先用volatile-lru/lfu;LFU更耗CPU因频次衰减更新;验证key是否频繁淘汰可用PFADD+PFCOUNT埋点统计。
-

必须显式配置client-output-buffer-limit,否则普通客户端无输出缓冲区上限,易致内存耗尽;需为normal、pubsub等类型分别设置hard/soft限制,尤其pubsub缓冲区最易失控。
-

reshard搬的是Slot而非Key,先重分配16384个Slot,再由集群自动触发Key迁移;需待“Allkeystransferred”提示才完成,且新节点须完成注册、握手、身份确认三步并满足网络与配置要求。
-

Redis的有序集合(SortedSet)非常适合排行榜应用。1)它可以轻松维护有序列表并按分数排序,2)通过简单命令实现数据的插入、更新、查询和删除,3)但在大规模数据下需优化查询性能和处理实时更新,4)需保证数据一致性和完整性。
-

Redis和Memcached的主要区别在于功能和适用场景。1)Redis提供丰富的数据结构和持久化功能,适合复杂数据处理和需要数据持久化的场景。2)Memcached专注于简单、高效的键值存储,适用于快速缓存需求。选择时需考虑数据复杂性、持久化需求、性能要求和扩展性。
-

需要关注Redis的版本更新,因为它能带来性能提升、安全补丁和新功能。检查Redis版本是否需要升级的步骤包括:1.使用命令“redis-cli--version”查看当前版本;2.与Redis官方版本对比;3.评估新功能、性能提升、安全补丁和兼容性;4.遵循备份数据、测试环境、逐步升级和监控日志的最佳实践。
-

Redis可以通过命令行参数启动,覆盖redis.conf文件中的设置。1)使用--port指定端口,2)使用--config指定配置文件路径,3)使用--daemonizeyes/no选择是否后台运行。
-

如何利用Redis和Node.js实现分布式数据同步功能分布式系统是当今互联网应用中常见的架构之一。在分布式系统中,数据同步是一个重要的问题,特别是在面对大规模并发和高可靠性要求时。Redis是一个高性能的内存数据库,而Node.js是一个基于事件驱动的JavaScript运行环境。本文将介绍如何利用Redis和Node.js实现分布式数据同步功能,并给出相
-

redis是单进程,阻塞式,在同一时刻只能处理一个请求,后来的请求需要排队等待。
优点:因为是单进程,所以无需处理并发问题,降低 系统复杂度
缺点:不适合缓存大尺寸对象(超过100kb)
-
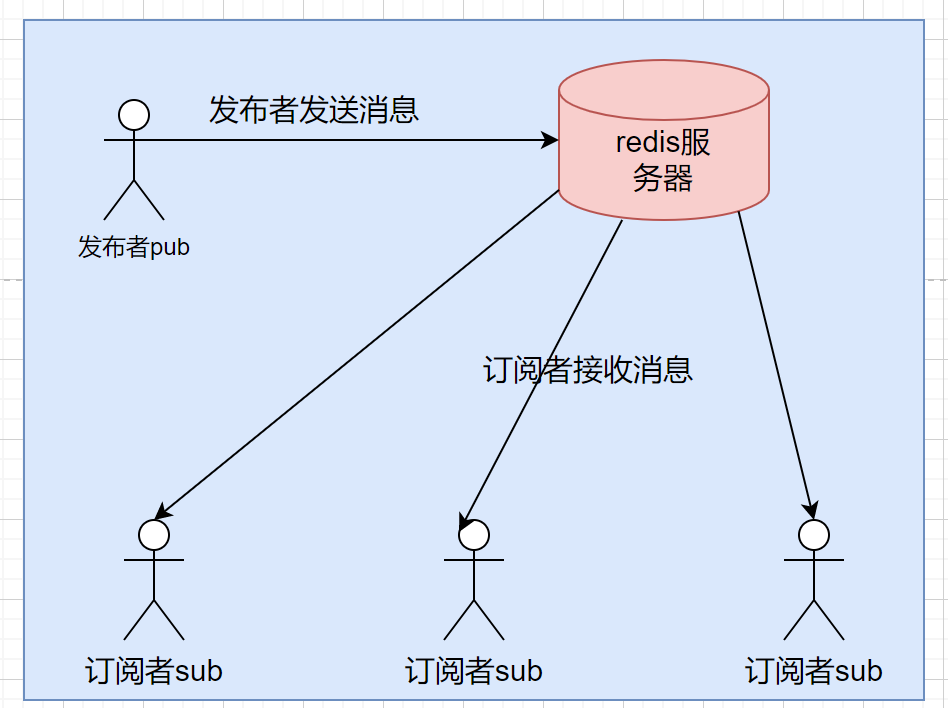
一、什么是发布和订阅
Redis 发布订阅 (pub/sub) 是一种消息通信模式:发送者 (pub) 发送消息,订阅者 (sub) 接收消息。特点:Redis 客户端可以订阅任意数量的频道。这就好比粉丝们关注了我,当我
-

RedisCluster默认不支持传统Pub/Sub跨节点广播,因频道按slot分片且gossip协议不传播订阅状态,SUBSCRIBE仅在本地节点生效;根本原因在于集群设计只负责数据分片,不实现消息路由。