-
一、redis环境:
环境:redis6.2.6linux虚拟机一台,contos7;
二、哨兵介绍:
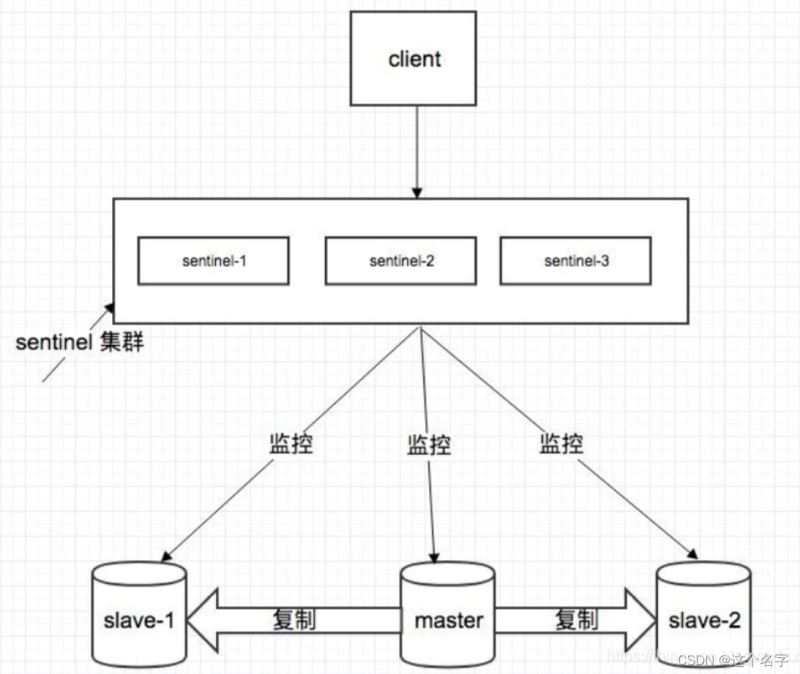
1.一主二从三哨兵理论图:
一主两从三哨兵集群,当master节点宕机时,通过哨兵(sentinel)重新推选出新的master节点,保证
-
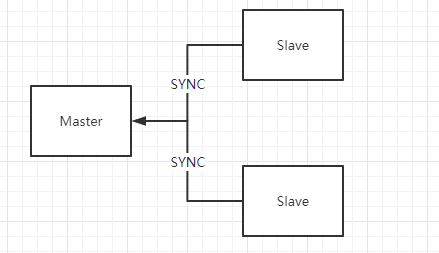
Redis三种集群方式:主从复制,哨兵模式,Cluster集群。
主从复制
基本原理
当新建立一个从服务器时,从服务器将向主服务器发送SYNC命令,接收到SYNC命令后的主服务器会进行一次BGSAVE命令,在
-

Redis在高并发环境下的性能调优可以通过以下步骤实现:1.内存管理:使用maxmemory和maxmemory-policy配置,建议使用allkeys-lru策略。2.网络I/O优化:调整tcp-backlog和client-output-buffer-limit配置。3.持久化优化:调整rdb和aof的配置,平衡性能和数据安全。4.集群和分片:使用RedisCluster或Codis分散数据。5.客户端优化:使用连接池和批处理命令如pipeline或mget/mset。通过这些措施,可以确保Redi
-

Redis 的 List 是一个双向链表,链表中的每个节点都包含了一个字符串。是redis中最常用的数据结构之一,下面跟大家分享下redis链表的底层实现以及生产实战。
底层实现
Redis的list数据结构底层
-

随着互联网的快速发展,消息队列不仅在企业级应用中得到广泛应用,也在小型项目和个人开发中逐渐流行起来。Redis作为一款高性能、内存数据库,也提供了可靠、灵活的消息队列解决方案。本文将介绍Redis如何实现消息队列,以及应用实例。一、Redis消息队列的实现方法RedisListRedisList是一种基于链表实现的数据结构,是Redis消息队列的核心部分
-

RedisStream不受maxmemory-policy淘汰机制影响,仅XADD的MAXLEN/MINID参数可在写入时截断数据;MAXLEN加~为近似截断,不加则严格控制条数,且只从最老端删除;消费者组未XACK会导致PEL积压,MAXLEN无法清理。
-

Redis主从复制故障的排查与修复步骤包括:1.检查网络连接,使用ping或telnet测试连通性;2.检查Redis配置文件,确保replicaof和repl-timeout设置正确;3.查看Redis日志文件,查找错误信息;4.如果是网络问题,尝试重启网络设备或切换备用路径;5.如果是配置问题,修改配置文件;6.如果是数据同步问题,使用SLAVEOF命令重新同步数据。
-

Redis的安全配置在不同环境下不同,因为各环境的角色和风险不同。1.开发环境配置宽松,建议启用基本认证,不暴露在公网。2.测试环境配置更严格,推荐强密码和更多安全措施。3.生产环境配置最严,使用最强密码和所有安全措施。通过合理配置和持续监控,确保Redis在各环境中的安全性和性能。
-
一、本案例涉及知识
Layui
Redis
Vue.js
jQuery
Ajax
二、效果图
三、功能实现
(一)使用 Layui 的样式构建页面
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>Redi
-

Redis需要设置最大占用内存吗?如果Redis内存使用超出了设置的最大值会怎样?
打开redis配置文件
找到如下段落,设置maxmemory参数,maxmemory是bytes字节类型,注意转换。修改如下所示:
# In short...
-

根本原因是repl-backlog-size过小或网络闪断超时,导致从节点重连时偏移量超出缓冲区范围而无法增量同步,被迫触发全量同步。
-

配置RedisSentinel高可用集群需要以下步骤:1.配置Sentinel节点,使用sentinelmonitor指令监控主节点;2.设置主从节点,确保从节点能自动接管;3.确保网络稳定性,避免误判;4.至少配置三个Sentinel节点保证高可用性;5.谨慎配置故障转移策略,设置超时时间;6.确保数据一致性,通过配置min-slaves-to-write和min-slaves-max-lag减少数据丢失风险;7.调整sentineldown-after-milliseconds参数减少不必要的故障转移
-

检测和优化Redis的网络带宽瓶颈可以通过以下步骤:1.使用INFO命令监控网络流量,计算每分钟的输入输出字节数;2.使用PING命令测量延迟;3.优化方法包括启用数据压缩、使用批量操作、优化网络配置、数据分片和使用Redis协议优化。通过这些措施,可以有效提升Redis的性能。
-

Redis通过事务、Lua脚本和SETNX命令实现数据操作的原子性。1)事务使用MULTI和EXEC命令,确保命令作为整体执行,但不支持回滚。2)Lua脚本通过EVAL命令,适合复杂操作,确保原子性。3)SETNX命令用于简单原子操作,如分布式锁,但需防死锁。
-

Redis和RabbitMQ在性能和联合应用场景中各有优势。1.Redis在数据读写上表现出色,延迟低至微秒级,适合高并发场景。2.RabbitMQ专注于消息传递,延迟在毫秒级,支持多队列和消费者模型。3.联合应用中,Redis可用于数据存储,RabbitMQ处理异步任务,提升系统响应速度和可靠性。