-

需要关注Redis的版本更新,因为它能带来性能提升、安全补丁和新功能。检查Redis版本是否需要升级的步骤包括:1.使用命令“redis-cli--version”查看当前版本;2.与Redis官方版本对比;3.评估新功能、性能提升、安全补丁和兼容性;4.遵循备份数据、测试环境、逐步升级和监控日志的最佳实践。
-

在Java项目中配置和使用Redis集群的步骤如下:1.创建RedisURI对象,指定集群节点的地址和端口;2.使用这些节点创建RedisClusterClient;3.连接到集群并获取同步命令接口;4.执行基本的读写操作;5.关闭连接和客户端。通过这些步骤,你可以有效地在Java项目中集成和使用Redis集群,提升系统的性能和可靠性。
-

如何使用Redis和Lua开发实时消息订阅功能随着互联网的快速发展,实时消息订阅功能在Web应用中的重要性日益凸显。无论是即时聊天应用、在线协作平台还是实时股票行情等,都需要实时更新消息,以保证用户能够及时获取最新的信息。在开发这类实时功能时,Redis和Lua是两个非常有力的工具。Redis是一种高性能的键值存储数据库,而Lua是一种高效的脚本语言。通过R
-
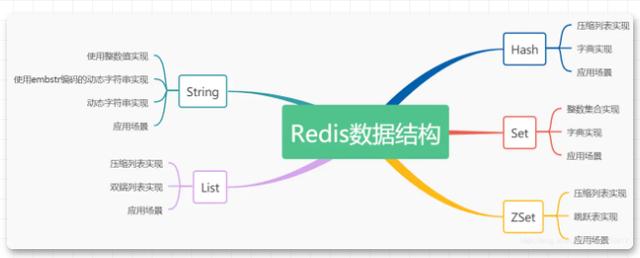
关于Redis的文章之前也写过两篇,阅读量和读者的反映都还可以,其中第一篇是Redis的缓存三大问题[。第二篇是Redis的内存管理和淘汰策略[]。这是关于Redis的第三篇文章,主要讲解Redis的
-
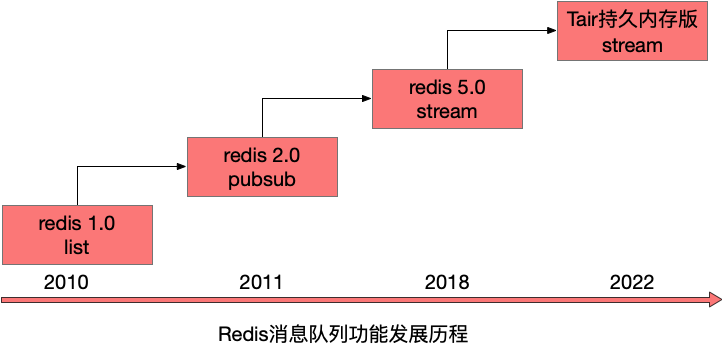
作者 | 丕天Redis是目前最受欢迎的kv类数据库,当然它的功能越来越多,早已不限定在kv场景,消息队列就是Redis中一个重要的功能。Redis从2010年发布1.0版本就具备一个消息队列的雏形,随着10
-

场景:一家网上商城做商品限量秒杀。
1 单机环境下的锁
将商品的数量存到Redis中。每个用户抢购前都需要到Redis中查询商品数量(代替mysql数据库。不考虑事务),如果商品数量大于0,则证明
-

前言
经常会有到这样的需求,就是在一个查询接口,第一次查询的时候,如果没有查询到就要执行初始化方法,初始化数据出来,之后的查询就可以直接查询库里的数据了。这样设计的目的是
-

方法一:基于Redis的setnx的操作
我们在使用Redis的分布式锁的时候,大家都知道是依靠了setnx的指令,在CAS(Compare and swap)的操作的时候,同时给指定的key设置了过期实践(expire),我们在限流
-

Redis6.0多线程不加速命令执行,仅I/O多线程+pipeline组合可提升导入效率;需客户端用pipeline打包发送,且主线程不饱和时才有效。
-

Redis延迟高但CPU正常通常是网络丢包或抖动所致,表现为redis-cli--latency毛刺飙升、ping标准差>10ms或丢包率>0.1%,需用tcpdump抓包分析重传与ACK丢弃,并排查云环境安全组、NAT会话老化及内核TCP参数配置。
-

Redis安全漏洞的扫描与修复可以通过以下步骤进行:1.使用Redis-Rogue等工具进行扫描,并在扫描前备份数据。2.分析报告,关注未授权访问、弱密码和过期版本等问题。3.修复时,设置强密码(如"Redis@2023#Sec"),定期更换,并更新到最新版本。
-

防止Redis遭受DDoS攻击的策略包括:1.限制连接数,通过maxclients参数设置合理的连接数上限;2.使用连接池管理Redis连接,设置最大连接数;3.限制命令执行,通过rename-command配置项重命名或禁用高风险命令;4.使用防火墙和安全组规则阻止不信任IP的连接;5.启用认证增加一层保护;6.通过监控和日志分析及时发现异常行为。
-

如何使用Redis和C#实现分布式事务处理功能引言:在现代分布式系统中,事务处理是一个至关重要的功能,它确保了系统中的各个操作是原子性、一致性、隔离性和持久性的。Redis是一款高性能的内存数据库,而C#是一种功能强大的编程语言。本文将介绍如何使用Redis和C#实现分布式事务处理功能,并提供相应的代码示例。一、Redis和C#介绍Redis:
-

随着互联网交易的不断增长,分布式事务成为业务系统必备的一部分。随着分布式事务的实现方式的不断丰富,Redis作为一个广泛使用的内存数据库,正逐渐成为分布式事务实现的首选。本文主要介绍Redis如何实现分布式事务。Redis的事务模型Redis支持的事务模型是批量操作。在一个事务内,Redis可以执行多个命令。多个命令在同一个事务中全部成功或者失败,保证了事务
-
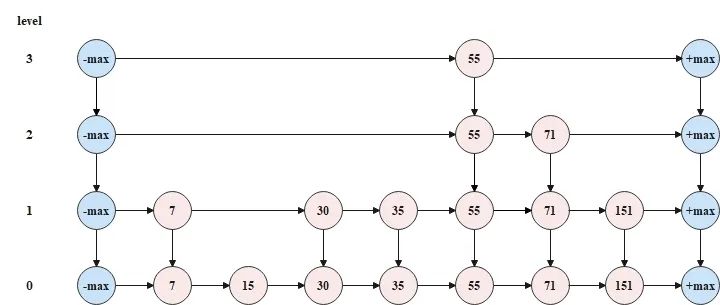
前言跳表可以达到和红黑树一样的时间复杂度 O(logN),且实现简单,Redis 中的有序集合对象的底层数据结构就使用了跳表。其作者威廉·普评价:跳跃链表是在很多应用中有可能替代平衡树的一