-
1、安装gcc编辑器安装redis需要依赖gcc环境,执行如下命令安装:yuminstall-ygcc如果机器没有网络的话,可以参考这篇文章:CentOS离线安装gcc环境(附安装包+图文并茂)2、下载redis安装包redis官网:https://redis.io/download下载后上传至CentOS,比如上传至/usr/local/3、解压并编译安装redis指令命令如下:1、进入安装包目录cd/usr/local/2、解压安装包tar-zxvfredis-6.2.1.tar.gz3、进入解压后的
-

随着分布式系统的普及,分布式锁变得越来越重要。分布式锁是一种保证在分布式系统中同时只能有一个进程或者线程进行操作的机制。在许多分布式环境下的应用程序中,分布式锁是一个非常常见的问题。Redis是一个高性能的支持多种数据结构的内存数据库,在分布式锁方面有着广泛的应用。本文将介绍Redis实现分布式锁的原理和实现方式。一、Redis实现分布式锁的原理在分布式系统
-
Redis 是一个高性能的key-value数据库, 使用内存作为主存储,数据访问速度非常快,当然它也提供了两种机制支持数据持久化存储.比较遗憾的是,Redis项目不直接支持Windows,Windows版项目是由
-

单纯靠TTL随机化不能根治缓存雪崩,但它是成本最低、见效最快的前置防线——关键在于“错开”而非“随机”,且必须配合过期时间分级和热点识别。
-

Redis键空间事件默认关闭,需配置notify-keyspace-events为KEA等组合才生效;事件频道名格式严格、无历史回放、过期事件延迟不可靠、断连事件丢失且无自动续订。
-

Redis和Memcached的主要区别在于功能和适用场景。1)Redis提供丰富的数据结构和持久化功能,适合复杂数据处理和需要数据持久化的场景。2)Memcached专注于简单、高效的键值存储,适用于快速缓存需求。选择时需考虑数据复杂性、持久化需求、性能要求和扩展性。
-

Redis在实时推荐系统中的应用随着互联网的迅猛发展和用户需求的多元化,实时推荐系统在电商、社交媒体、新闻等领域中变得越来越重要。实时推荐系统不仅能提供个性化的推荐服务,还能实时地根据用户行为和兴趣变化进行推荐调整。为了实现这些功能,需求一个高效的存储和查询工具。而Redis正是一种非常适合实时推荐系统的存储和查询工具。本文将详细介绍Redis在实时推荐系统
-

Redis是一款被广泛应用的开源Key-Value数据库,以其高性能、低延迟、高并发等优点深受开发者的青睐。然而随着数据量的不断增加,单节点的Redis已经无法满足业务需求。为了解决这个问题,Redis引入了数据分片(Sharding)功能,实现数据的水平扩展,提高了Redis的整体性能。本文将介绍Redis如何实现数据分片扩展功能,并提供具体的代码示例。一
-
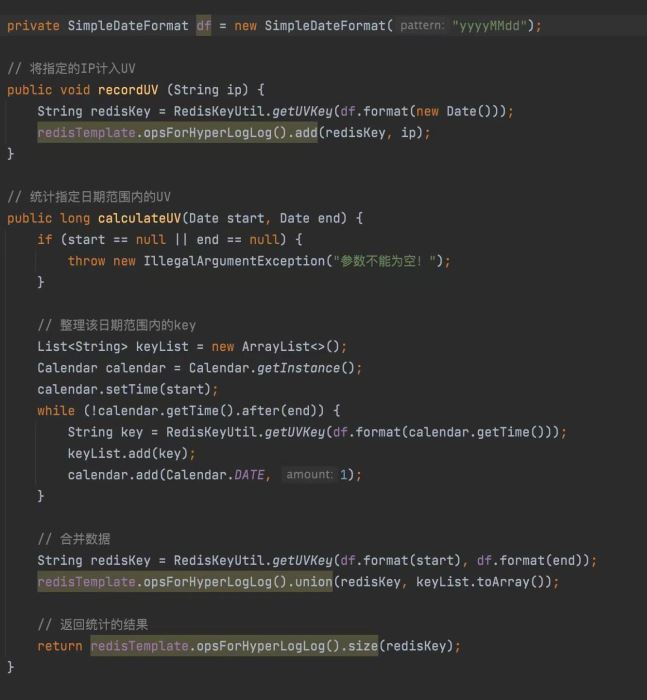
1. HyperLogLog 的原理
Redis HyperLogLog基于一种称为HyperLogLog算法的概率性算法来估计基数。 HyperLogLog使用一个长度为m的位数组和一些hash函数来估计集合中的唯一元素数。
在 HyperLogLog 算法中,对
-
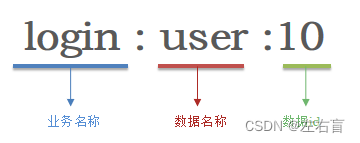
在Redis中,良好的键值设计可以达成事半功倍的效果,而不好的键值设计可能会带来Redis服务停滞,网络阻塞,CPU使用率飙升等一系列问题,今天就教大家如何设计一个良好的key-value
1 优雅的key
-

Redis Streams 消费者组如果消费者掉线或处理失败,消息会留在 Pending 列表里,表现为队列越积越多。本文从现象复现、XINFO/XPENDING 检查、认领重试到 XACK 确认,完整排查一次消费堆积问题。
-

RedisLua脚本中不能直接执行SET等命令,必须通过redis.call()或redis.pcall()调用;MULTI/EXEC等事务命令禁用;所有key需显式传入,集群下须同slot;返回值类型需手动判断,避免误判false/0。
-

HLL在处理大数据量统计时的使用技巧包括:1.合并多个HLL以统计多个数据源的UV;2.定期清理HLL数据以确保统计准确性;3.结合其他数据结构使用以获取更多详情。HLL是一种概率性数据结构,适用于需要近似值而非精确值的统计场景。
-

Redis集群数据分片的原理是通过哈希槽实现数据的分布式存储。1)Redis集群将键空间划分为16384个哈希槽,每个键通过CRC16校验和后对16384取模,决定所属哈希槽。2)每个Redis节点负责一部分哈希槽,实现数据分片。3)这种设计支持动态调整集群规模,通过迁移部分哈希槽添加或移除节点。
-

Redis的有序集合(SortedSet)非常适合排行榜应用。1)它可以轻松维护有序列表并按分数排序,2)通过简单命令实现数据的插入、更新、查询和删除,3)但在大规模数据下需优化查询性能和处理实时更新,4)需保证数据一致性和完整性。