-

通过Redisexporter采集Redis的指标数据,并配置Prometheus来抓取这些数据,同时设置合适的告警规则。1.安装并配置Redisexporter,使用Docker简化安装过程。2.在Prometheus配置文件中添加scrape配置以抓取Redisexporter数据。3.使用PromQL查询Redisexporter提供的指标,如内存使用率和连接数。4.通过Alertmanager设置告警规则,如内存使用率超过90%时触发告警。
-

开启和查看Redis的安全审计日志需要编辑redis.conf文件,将appendonly设置为yes,并定义日志文件名。查看日志可通过读取AOF文件。1.编辑redis.conf,设置appendonlyyes和appendfilename。2.使用catappendonly.aof查看日志。定期管理AOF文件并确保其安全性是必要的。
-

Redis事务通过将多个命令打包一次性执行,提供有限的原子性和隔离性。其核心实现步骤为:1.MULTI开启事务;2.命令入队但不立即执行;3.EXEC按顺序执行队列中的命令并返回结果;4.DISCARD取消事务。WATCH用于监控key以实现乐观锁。Redis事务无法完全满足ACID特性,原子性仅保证命令全执行或全不执行,但不支持回滚;一致性依赖客户端处理;隔离性有限;持久性取决于持久化策略。事务不支持回滚的原因在于设计哲学追求高效简单。执行失败时需根据EXEC返回值判断原因并重试或放弃。与Lua脚本相比
-

要保护Redis数据不被未授权访问,应采取以下措施:1.设置强密码认证,使用requirepass配置项。2.绑定Redis到特定IP地址,如127.0.0.1。3.使用ACL设置不同用户权限。4.配置防火墙规则限制Redis端口访问。5.使用TLS加密Redis通信。通过这些措施,可以有效降低Redis数据泄露风险,确保应用安全性和稳定性。
-

Redis因系统崩溃后的重启和数据恢复可以通过以下步骤实现:1)理解Redis的RDB和AOF持久化机制,根据业务需求选择合适的方式;2)使用redis-check-aof工具修复损坏的AOF文件;3)检查并调整redis.conf文件中的持久化设置;4)对于Redis集群,先移除崩溃节点,重启并恢复数据后再重新加入集群;5)定期使用bgsave命令备份数据,确保数据安全。通过这些步骤,可以有效地重启Redis并恢复数据,保障系统的连续性和数据的安全性。
-
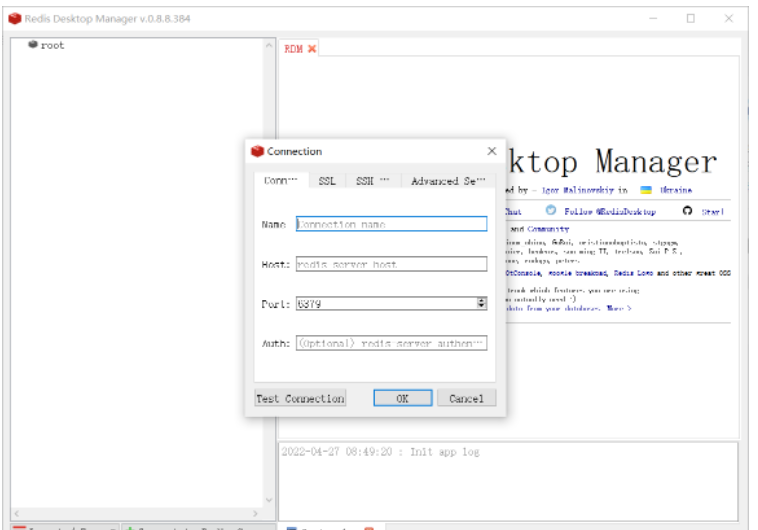
1.下载RedisDesktopManager直接去官网或者csdn上搜就行2.安装RedisDesktopManager傻瓜式安装,一直点next就行安装完成后就是这样3.建立远程连接开始连接之前需要以下准备工作修改redis.conf文件命令vimredis.conf如果你的redis.conf在其他文件里面,需要加上文件路径比如我的在etc目录下,就在redis前面加上/etcvim/etc/redis.conf1.设置虚拟机的主机ip/或者设置为0.0.0.0开放所有我这里是直接注释掉了,然后使用
-

引言
2023的金三银四来的没想象中那么激烈,一个朋友前段时间投了几十家,多数石沉大海,好不容易等来面试机会,就恰好被问道项目中关于分布式锁的应用,后涉及Redisson实现分布式锁的原
-

MongoDB更类似MySQL,支持字段索引、游标操作,其优势在于查询功能比较强大,擅长查询JSON数据,能存储海量数据,但是不支持事务。
Mysql在大数据量时效率显著下降,MongoDB更多时候作为关系数
-

常用的Redis性能监控工具包括Redis自带的INFO命令、慢查询日志、RedisInsight、Prometheus和Grafana组合以及Redis-benchmark。1.INFO命令适合快速诊断问题,但数据粒度较粗。2.慢查询日志有助于优化性能,但配置需谨慎。3.RedisInsight提供直观的监控和分析功能,但需考虑资源消耗。4.Prometheus和Grafana组合适用于大规模集群监控和长期趋势分析,部署复杂。5.Redis-benchmark用于测试性能极限,需结合实际业务场景分析。
-

查哨兵进程资源需用ps和top实时监控CPU与内存,关注RSS突增、%CPU峰值及线性上涨;结合日志分析+sdown/+odown频次、INFOSENTINEL状态(如sentinel_tilt、sentinel_running_scripts)定位真实压力源。
-

Redis和HBase可以协同工作,发挥各自优势。1)使用Redis处理实时数据和缓存,如用户行为数据。2)利用HBase存储和分析历史数据,如用户购买习惯。通过这种方式,可以实现快速访问和长久存储的平衡。
-

Redis(RemoteDictionaryServer)是一种基于内存的数据结构存储系统,具有轻便、高效、易用等特点。它不仅是一个高速的键值对存储数据库,而且提供了各种灵活的数据结构,如字符串、散列、列表、集合和有序集合,可以支持各种场景的应用。除此之外,Redis还拥有强大的实时计算能力,可以快速构建实时统计系统。在实际应用场景中,常常需要构建实时统
-

使用Python和Redis构建键值存储系统:如何高效地存储和检索数据在现代大数据时代,高效地存储和检索数据是至关重要的。为了满足这个需求,我们可以使用Python和Redis来构建一个高性能的键值存储系统。Redis是一个开源的内存数据库,具有出色的性能和可扩展性。在本文中,我们将学习如何使用Python的redis模块来连接Redis数据库,并通过一些示
-

Redis与Java开发:构建可扩展的企业级应用在开发企业级应用时,数据的存储和管理是非常重要的一部分。传统的关系型数据库虽然功能强大,但在处理高并发和大数据量的场景下,性能和扩展性往往成为瓶颈。而Redis作为一种高性能的内存数据库,具有速度快、支持多种数据结构、可扩展性强等优点,成为解决这些问题的好选择。本文将介绍如何在Java开发中使用Redis构建可
-

随着互联网的发展,在线教育已成为一种新兴的学习方式。在这个领域中,数据存储和快速响应速度非常关键,因此NoSQL数据库应用越来越应用于在线教育平台。其中,Redis作为NoSQL数据库的一种,具有高速的读写速度和数据持久化机制,被广泛应用于在线教育领域。下面,我们将介绍Redis在在线教育领域中的应用实践。一、课程内容缓存在线教育平台中的课程内容通常是动态的