-
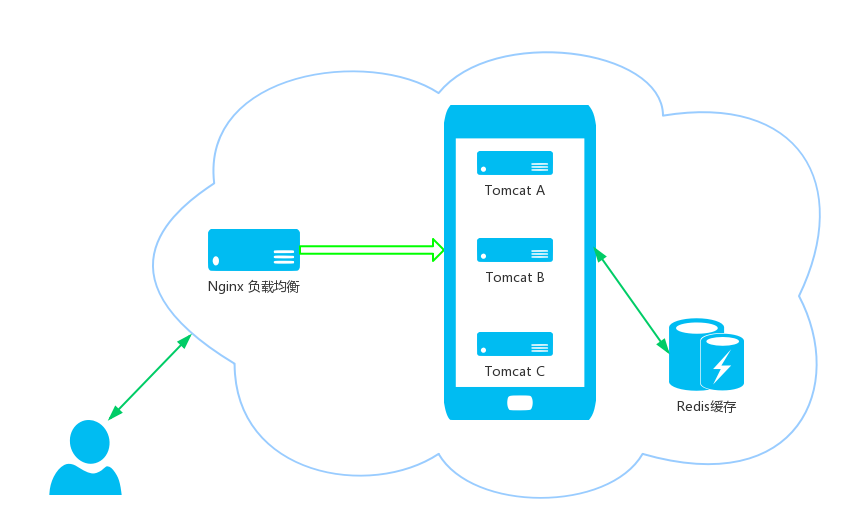
架构方案使用redis集中存储,实现分布式集群共享用户信息,这里我们采用第三方开源插件crazycake来实现,pom.xml引入:org.springframework.bootspring-boot-starter-data-redisorg.crazycakeshiro-redis3.2.3配置application.properties:#Redis#数据库索引(默认为0)redis.database=0#服务器地址变更为自己的redis.host=127.0.0.1#服务器连接端口redis.p
-

通过redis-cli、RedisInsight、Prometheus和Grafana等工具,以及关注内存使用率、连接数、集群节点状态、数据一致性和性能指标,可以有效监控Redis集群的健康状态。
-

在多线程环境中优化Redis性能可以通过以下策略:1.使用连接池管理,减少连接开销;2.采用命令批处理减少网络延迟;3.实施数据分片分担负载;4.避免阻塞操作;5.使用锁机制确保数据一致性;6.进行监控与调优以提升性能。
-

Redis集群通过主从复制、故障转移和一致性哈希保障数据一致性。优化方法包括:1.调整网络配置,提升网络性能;2.合理的数据分片策略,均衡负载;3.采用读写分离,提升读性能和降低主节点压力。
-

Redis主从复制故障的排查与修复步骤包括:1.检查网络连接,使用ping或telnet测试连通性;2.检查Redis配置文件,确保replicaof和repl-timeout设置正确;3.查看Redis日志文件,查找错误信息;4.如果是网络问题,尝试重启网络设备或切换备用路径;5.如果是配置问题,修改配置文件;6.如果是数据同步问题,使用SLAVEOF命令重新同步数据。
-

HLL在处理大数据量统计时的使用技巧包括:1.合并多个HLL以统计多个数据源的UV;2.定期清理HLL数据以确保统计准确性;3.结合其他数据结构使用以获取更多详情。HLL是一种概率性数据结构,适用于需要近似值而非精确值的统计场景。
-

Redis和HBase可以协同工作,发挥各自优势。1)使用Redis处理实时数据和缓存,如用户行为数据。2)利用HBase存储和分析历史数据,如用户购买习惯。通过这种方式,可以实现快速访问和长久存储的平衡。
-

maxclients作用于每个Redis实例(节点)而非整个集群,集群中6个节点需单独配置;其实际生效值取配置值与系统ulimit-n的较小值,且slave节点因承担复制和读请求双重压力更易触顶。
-

使用Java和Redis构建分布式缓存系统:如何提高应用的扩展性引言:在现代的分布式应用程序中,缓存是提高性能和可伸缩性的关键组件之一。Redis是一种广泛使用的内存数据存储系统,它能够提供快速和高效的数据访问。本文将介绍如何使用Java和Redis构建一个分布式缓存系统,并通过代码示例演示如何提高应用的扩展性。一、概述:分布式缓存系统通过将缓存数据分散存储
-

使用Python和Redis构建实时用户分析系统:如何提供用户行为统计引言:随着互联网的发展,用户行为统计对于企业和产品的发展至关重要。这是一个能够实时统计、分析和展示用户行为数据的系统。在本文中,我们将介绍如何使用Python和Redis构建一个实时用户分析系统,以提供准确和实时的用户行为统计信息。我们将展示如何使用Python编写代码,并结合Redis数
-

缓存击穿需用Redis原子命令SETkeyvalueEXsecondsNX加key级互斥锁,配合Lua脚本安全解锁;推荐RedissonRLock自动续期,空值缓存需权衡数据一致性与性能。
-
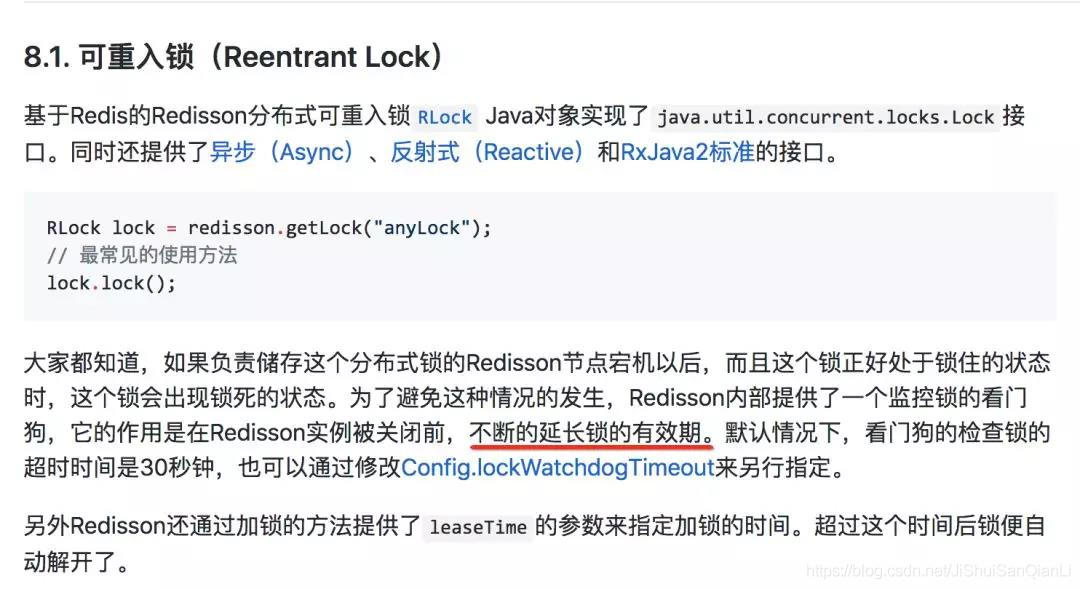
面试问题
Redis锁的过期时间小于业务的执行时间该如何续期?
问题分析
首先如果你之前用Redis的分布式锁的姿势正确,并且看过相应的官方文档的话,这个问题So easy.我们来看
很多同学在用分布式
-

解决Redis启动时内存分配不足问题的方法包括:1.检查系统内存使用情况,必要时增加物理内存或调整Redis配置;2.修改redis.conf文件中的maxmemory参数,限制Redis内存使用;3.配置maxmemory-policy参数,选择合适的内存回收策略;4.增加swap空间或禁用Redis的swap使用;5.通过RedisCluster分散数据存储,降低单节点内存压力;6.使用MEMORYUSAGE命令查找并处理大key。
-

Redis列表在消息队列中的应用可以通过以下优化措施提升性能和可靠性:1.启用持久化机制(AOF或RDB)确保消息不丢失;2.使用BRPOP命令提高消费者的响应性和降低系统负载;3.通过多个列表模拟优先级队列处理不同优先级的消息;4.设置键的过期时间或在消息中加入时间戳管理消息的生命周期;5.利用批量操作减少网络开销,提升系统性能。
-

Redis连接数过高可能导致服务器压力增大,影响响应速度甚至引发崩溃,因此需监控和管理。可通过RedisCLI执行INFO命令查看connected_clients指标,或使用RedisDesktopManager、Prometheus+Grafana等工具实现可视化监控,也可通过CLIENTLIST命令详细查看每个客户端连接情况。管理方面包括优化代码防止连接泄漏、使用连接池减少频繁连接开销、设置maxclients限制最大连接数、利用CLIENTKILL终止异常连接、调整timeout参数自动关闭空闲连