Redis技术文章
-
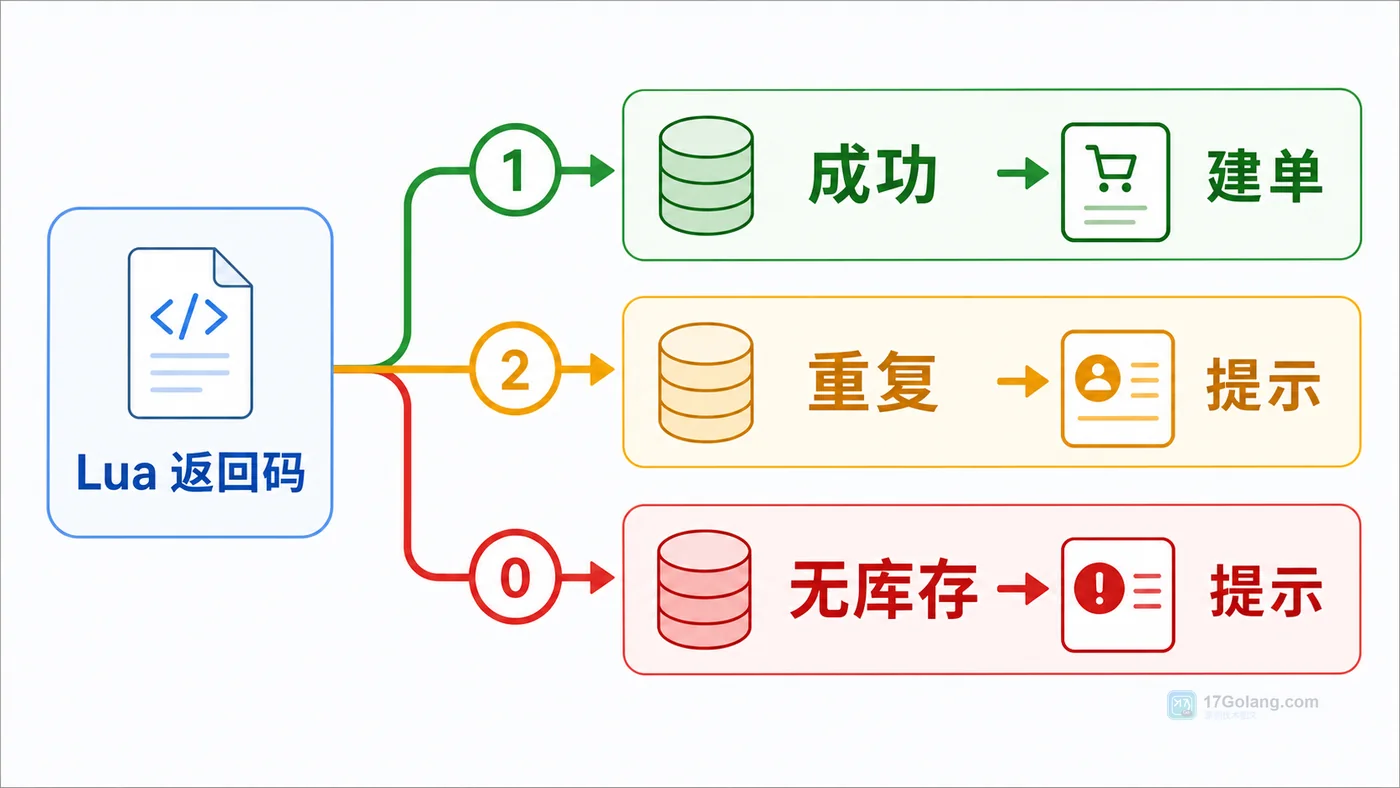 本文用秒杀扣库存场景讲清 Redis Lua 的落地方式:在一个脚本里完成库存校验、重复订单判断、扣减库存和记录订单结果,减少并发下超卖和重复扣减风险。118 收藏
本文用秒杀扣库存场景讲清 Redis Lua 的落地方式:在一个脚本里完成库存校验、重复订单判断、扣减库存和记录订单结果,减少并发下超卖和重复扣减风险。118 收藏 -
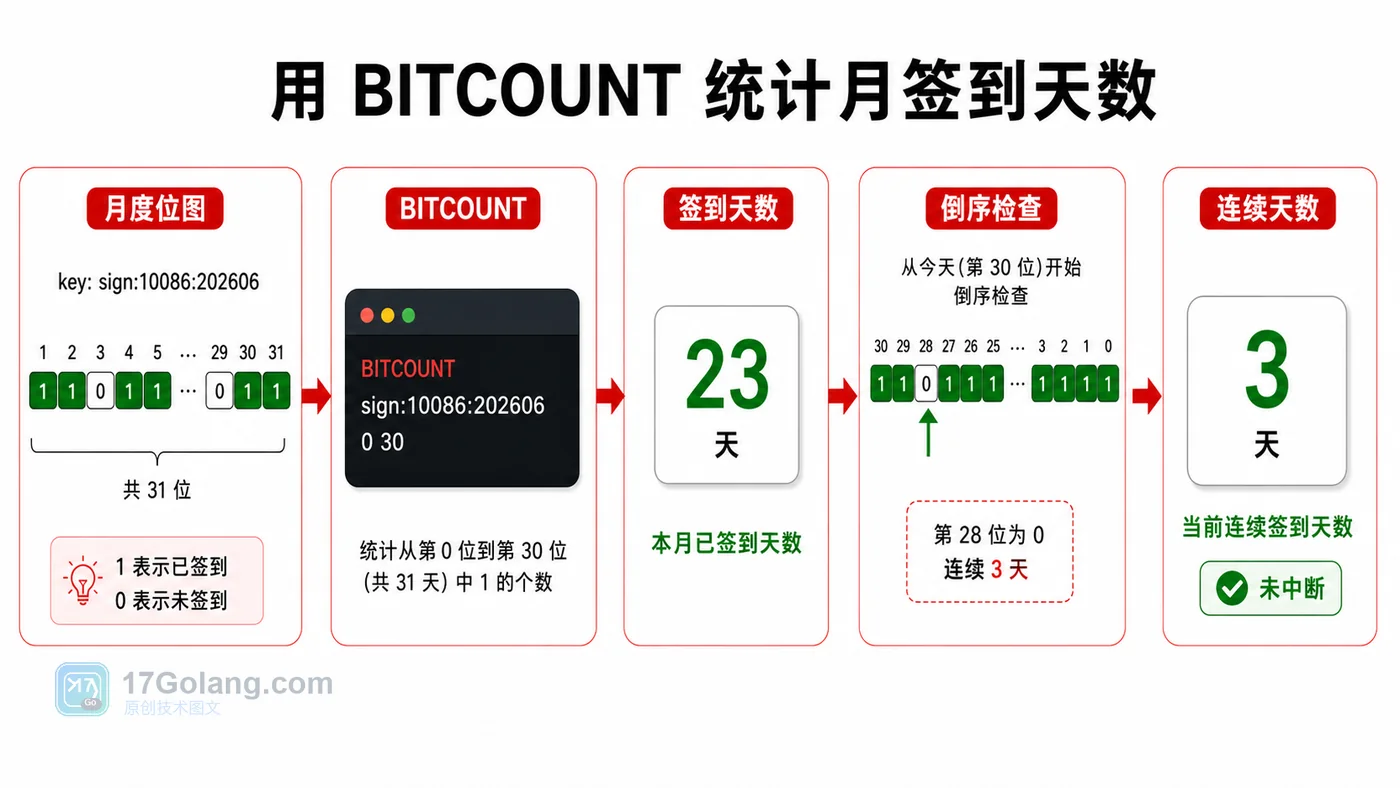 本文用 Redis Bitmap 实现用户签到:用 SETBIT 写入每天状态,用 GETBIT 查询当天是否签到,用 BITCOUNT 快速统计月签到天数,并补充连续签到和键设计建议。464 收藏
本文用 Redis Bitmap 实现用户签到:用 SETBIT 写入每天状态,用 GETBIT 查询当天是否签到,用 BITCOUNT 快速统计月签到天数,并补充连续签到和键设计建议。464 收藏 -
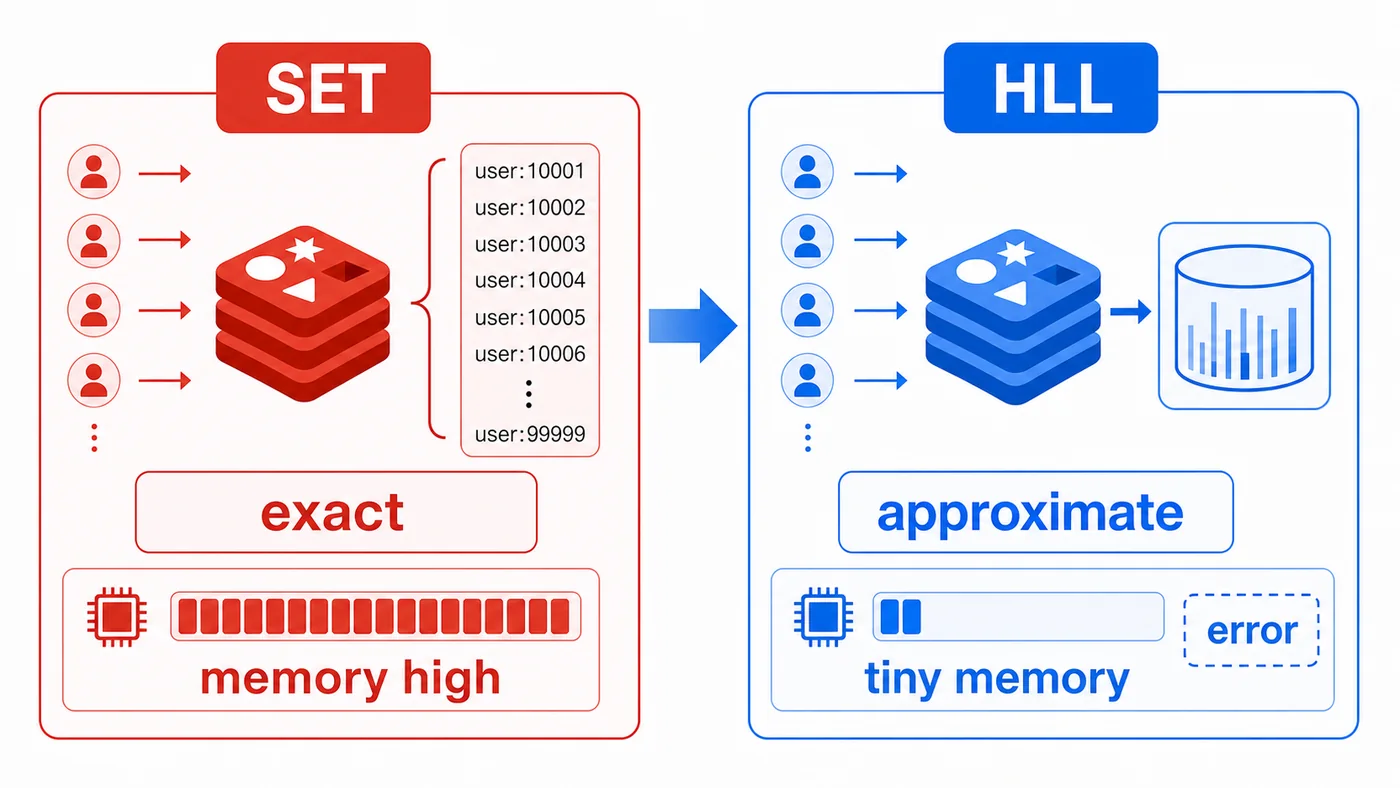 用 Redis HyperLogLog 做站点 UV 统计:通过 PFADD 写入用户标识,用 PFCOUNT 读取近似去重人数,对比 Set 精确去重的内存成本,并说明适用场景和误差边界。180 收藏
用 Redis HyperLogLog 做站点 UV 统计:通过 PFADD 写入用户标识,用 PFCOUNT 读取近似去重人数,对比 Set 精确去重的内存成本,并说明适用场景和误差边界。180 收藏 -
数据库 · Redis | 4星期前 | Redis · 消息队列 · Stream · 消费组 · redis 消息队列 Redis Stream 消费组 XREADGROUP XACK XPENDING XAUTOCLAIM
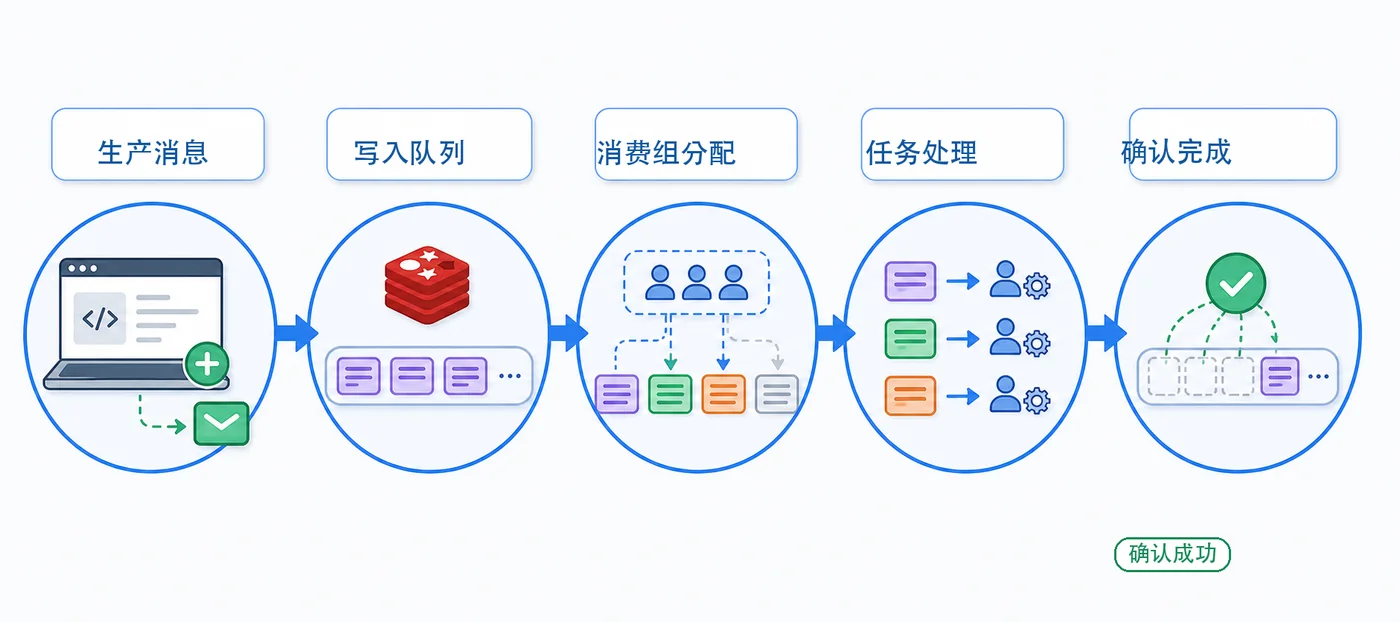 用订单异步处理场景讲清楚 Redis Stream 的实用队列模型:生产者写入消息,消费组分配任务,Worker 处理成功后 ACK,失败或超时的消息进入待确认列表,再通过 XPENDING 和 XAUTOCLAIM 做重投。187 收藏
用订单异步处理场景讲清楚 Redis Stream 的实用队列模型:生产者写入消息,消费组分配任务,Worker 处理成功后 ACK,失败或超时的消息进入待确认列表,再通过 XPENDING 和 XAUTOCLAIM 做重投。187 收藏 -
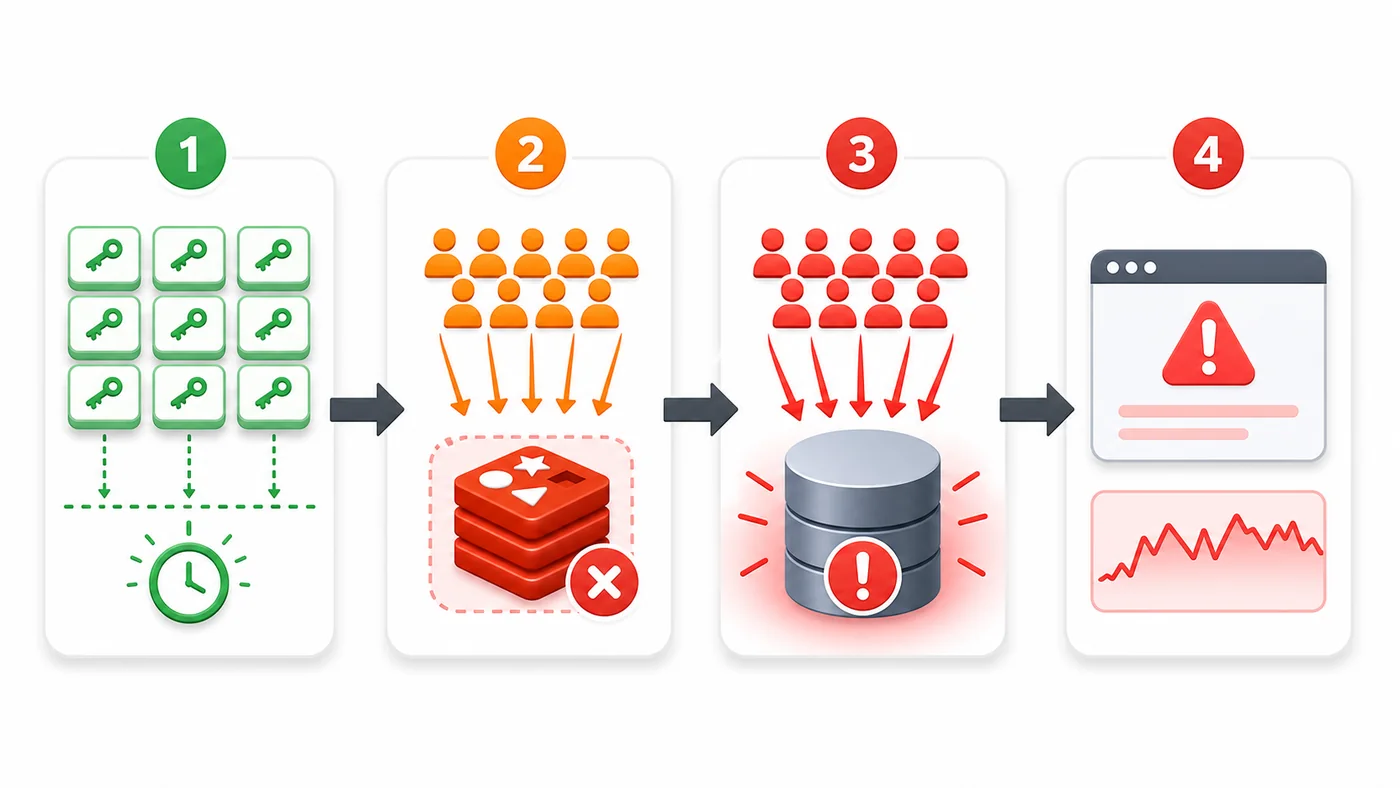 本文用商品详情缓存同时过期的场景,演示 Redis 缓存雪崩的形成过程,并给出 TTL 抖动、热点预热、互斥重建和降级保护的落地方案。139 收藏
本文用商品详情缓存同时过期的场景,演示 Redis 缓存雪崩的形成过程,并给出 TTL 抖动、热点预热、互斥重建和降级保护的落地方案。139 收藏 -
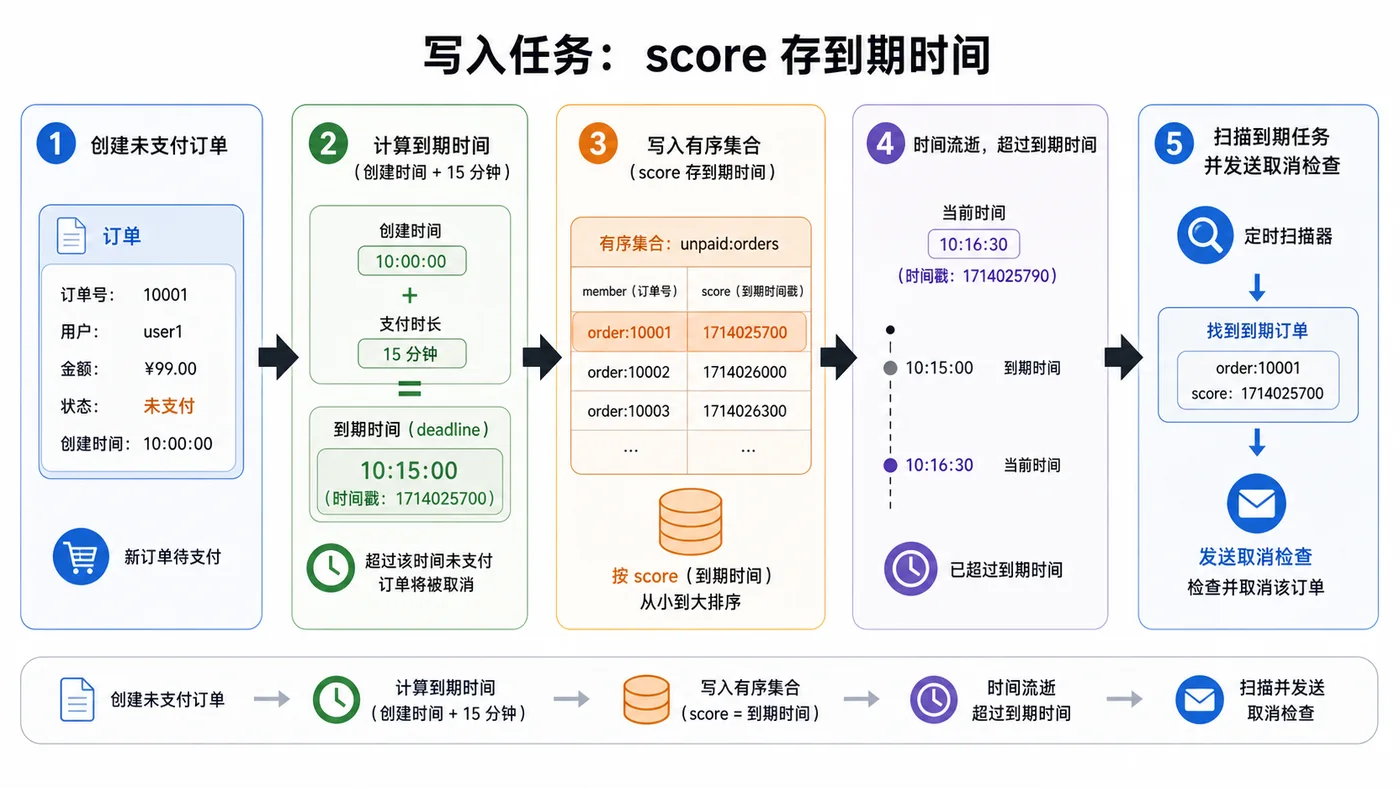 本文用 Redis ZSET 设计一个轻量延迟队列,讲清楚如何写入订单超时任务、按时间扫描到期任务、抢占删除、防重复处理以及失败重试。116 收藏
本文用 Redis ZSET 设计一个轻量延迟队列,讲清楚如何写入订单超时任务、按时间扫描到期任务、抢占删除、防重复处理以及失败重试。116 收藏 -
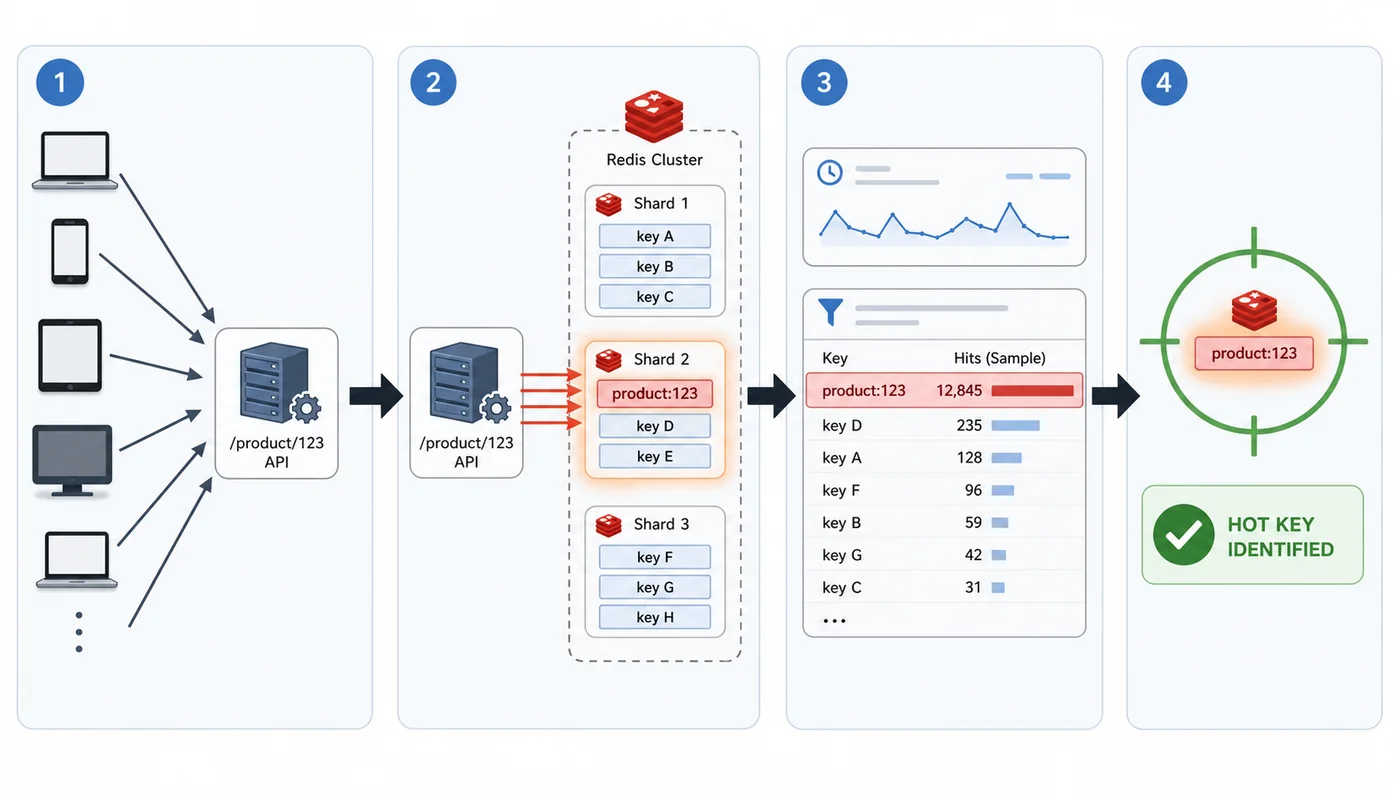 本文从一次商品详情接口抖动出发,演示如何发现 Redis 热 Key、判断访问倾斜,并通过过期时间抖动、本地短缓存、singleflight 合并加载和拆分 Key 降低热点冲击。111 收藏
本文从一次商品详情接口抖动出发,演示如何发现 Redis 热 Key、判断访问倾斜,并通过过期时间抖动、本地短缓存、singleflight 合并加载和拆分 Key 降低热点冲击。111 收藏 -
 RedisLua脚本原生不支持复杂正则匹配,仅提供基础模式匹配(如%d+),不支持\d、(?i)、.*?、分组捕获等;禁止动态加载外部库(如lrexlib-pcre);推荐在客户端处理或使用RediSearch的FT.SEARCHREGEX。438 收藏
RedisLua脚本原生不支持复杂正则匹配,仅提供基础模式匹配(如%d+),不支持\d、(?i)、.*?、分组捕获等;禁止动态加载外部库(如lrexlib-pcre);推荐在客户端处理或使用RediSearch的FT.SEARCHREGEX。438 收藏 -
 必须显式配置client-output-buffer-limit,否则普通客户端无输出缓冲区上限,易致内存耗尽;需为normal、pubsub等类型分别设置hard/soft限制,尤其pubsub缓冲区最易失控。146 收藏
必须显式配置client-output-buffer-limit,否则普通客户端无输出缓冲区上限,易致内存耗尽;需为normal、pubsub等类型分别设置hard/soft限制,尤其pubsub缓冲区最易失控。146 收藏 -
 PSUBSCRIBE性能瓶颈源于PUBLISH时线性遍历所有pattern做glob匹配。无索引、无缓存、无短路,pattern越多越慢;大小写敏感且*不匹配空字符串,易误配;超20个pattern或100qps即引发CPU毛刺。476 收藏
PSUBSCRIBE性能瓶颈源于PUBLISH时线性遍历所有pattern做glob匹配。无索引、无缓存、无短路,pattern越多越慢;大小写敏感且*不匹配空字符串,易误配;超20个pattern或100qps即引发CPU毛刺。476 收藏 -
 直接用DEL释放锁会误删其他客户端的锁,因判断持有锁与删除非原子操作;Lua脚本通过原子执行“GET校验+DEL”解决,需传入key和client_id,返回1成功、0失败。216 收藏
直接用DEL释放锁会误删其他客户端的锁,因判断持有锁与删除非原子操作;Lua脚本通过原子执行“GET校验+DEL”解决,需传入key和client_id,返回1成功、0失败。216 收藏 -
 RedisLua脚本不能实现真正的分布式事务回滚,仅能通过条件化原子写入预防性拒绝,失败后需业务层设计补偿机制。180 收藏
RedisLua脚本不能实现真正的分布式事务回滚,仅能通过条件化原子写入预防性拒绝,失败后需业务层设计补偿机制。180 收藏 -
 必须同时启用io-threads和io-threads-do-reads,否则I/O线程不参与读请求处理;io-threads≥2才生效,需configrewrite或重启;推荐值为min(4,CPU核心数×0.7),NUMA架构下必须用server_cpulist绑定同node核心。326 收藏
必须同时启用io-threads和io-threads-do-reads,否则I/O线程不参与读请求处理;io-threads≥2才生效,需configrewrite或重启;推荐值为min(4,CPU核心数×0.7),NUMA架构下必须用server_cpulist绑定同node核心。326 收藏 -
 RedisPub/Sub不支持自动消息压缩,因PUBLISH内容直写输出缓冲区,绕过LZF等内存压缩逻辑;需客户端自行压缩/解压,并统一算法;高频短消息推荐LZ4/Snappy;长期应改用Stream替代。415 收藏
RedisPub/Sub不支持自动消息压缩,因PUBLISH内容直写输出缓冲区,绕过LZF等内存压缩逻辑;需客户端自行压缩/解压,并统一算法;高频短消息推荐LZ4/Snappy;长期应改用Stream替代。415 收藏 -
 命中率低于75%(即keyspace_hits:keyspace_misses<3:1)时应调整淘汰策略,因缓存已无法有效分担数据库压力;需结合evicted_keys增速与keyspace_misses增速同步上升来确认问题根源。242 收藏
命中率低于75%(即keyspace_hits:keyspace_misses<3:1)时应调整淘汰策略,因缓存已无法有效分担数据库压力;需结合evicted_keys增速与keyspace_misses增速同步上升来确认问题根源。242 收藏