-

可通过手动导出奶酪单词词表→点点AI生成四字段复习表→导入自定义词书→OCR补全图片词→用复习本数据反向优化辨析题,实现二者协同学习。
-

响应被截断主因是max_tokens设置不当,需按输出类型(64–4096)、模型规格(abab6.5s限2048、minimax-pro可设4096)、截断现象(提升40%~60%或+384)、stop参数协同及token精准计算五方面调整。
-

OpenClawAI支持四种DeepSeek模型接入方式:一、DeepSeek官方API;二、DigitalOceanGradient平台;三、本地Ollama服务;四、阿里云百炼平台,各需配置对应API密钥、BaseURL及ModelID。
-
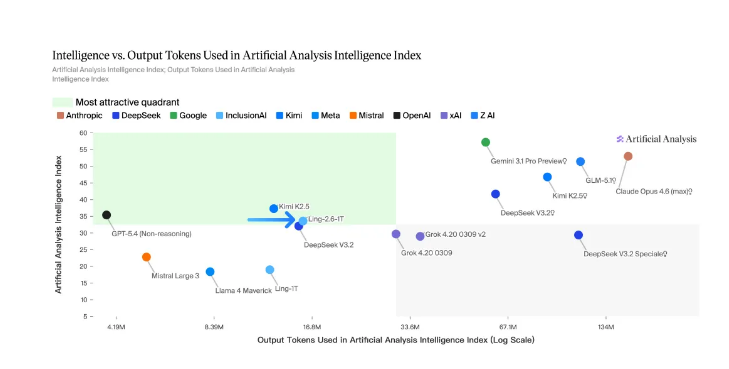
蚂蚁百灵大模型(Ling)今日正式宣布,其参数规模达万亿级别的旗舰版本Ling-2.6-1T全面开源。该模型延续了上周首发时的核心技术路线,摒弃单纯堆叠参数或拉长推理链路的粗放路径,转而采用MLA与LinearAttention融合的新型架构,构建出高效的“快思考(Fast-Thinking)”能力,直击超大规模模型在真实业务场景中智能与效率难以兼顾的关键瓶颈。根据ArtificialAnalysis平台的全维度评测结果,Ling-2.6-1T展现出卓越的Token利用效率——仅消
-

豆包AI基础大模型知识截止于2024年7月,训练语料封版于此;动态知识通过实时检索增强,政务与金融数据延迟≤24小时,部分工具链更新至2025年10月,但通用知识仍锚定原时间节点。
-

应精简负面提示词、添加空间限定语法、嵌入风格锚点、分层屏蔽高频干扰物,并控制token长度与分布。具体包括剔除冗余词、前置背景相关短语、插入“background:”前缀、加权边缘控制、追加风格一致性指令、按场景启用针对性屏蔽组,以及将负面词限于120字符内并用逗号分隔。
-

AI可提升企业培训质量与效率,具体路径包括:一、基于岗位需求生成课程大纲;二、批量制作多样化教学素材;三、构建个性化学习路径引擎;四、部署智能陪练与即时反馈系统;五、自动化评估培训效果归因。
-

腾讯云WorkBuddy采用Credits点数制计费,免费版限基础模型、50MB知识库、1个插件及本地权限,企业版开放全模型、无上限知识库与插件、AD域控、数字水印及审批流,需通过License状态、功能灰度与策略配置综合识别版本。
-

与Seedance2.0合作需经五步:一、官网指定入口提交意向;二、填写并上传《商务合作意向表》及营业执照;三、3日内等初审结果并添加对接专员;四、线上尽调并签署NDA后获取资料包;五、签署协议回传后24小时内开通权限。
-

GeminiAPI集成需掌握5大核心技术模块:一、模型标识与版本控制,须显式声明model字段并确认启用状态;二、内容结构化输入,强制使用content数组封装多模态数据;三、安全过滤器需逐条配置category与threshold;四、流式响应须处理SSEchunk并识别done标志;五、工具调用须严格遵循schema定义与三阶段闭环流程。
-

缺乏真实演练环境或反馈机制的求职者,可选用五款AI模拟面试App:智联校园小程序、译妙蛙面试官、AI职通、易展翅、可栗口语,各具岗位适配、多语支持、轻量高效、校招定制及英语强化等特色功能。
-

可行但需组合使用Windows计划任务与WorkBuddy内置自动化计划:前者负责定时唤醒进程,后者根据预设自然语言指令执行具体任务,二者缺一不可。
-

【PHP中文网快讯】小米今日正式宣布开源XiaomiMiMo-V2.5大模型系列(关于该系列模型的详细信息,可回溯查看PHP中文网此前报道:《对标全球顶尖模型!XiaomiMiMo-V2.5系列大模型开启公测,Token效率大幅提升》),项目遵循MIT开源协议,全面支持商业场景下的推理部署及二次训练,无需额外申请授权。同步启动“MiMoOrbit”生态扶持计划,涵盖两大专项:面向AI开发者的“百万亿Token创造者激励计划”,以及面向Agent框架研发团队的“Agent生态共建计划”。百万亿Toke
-

Perplexity中需启用Sources模式并配置引文样式以显示引用摘要预览:一、通过Focus菜单选择Sources/Academic/Research模式;二、在Settings→Citations&References中设默认格式并勾选显示元数据;三、用自然语言指令临时指定MLA/APA等格式;四、Pro用户可用Cite按钮导出BibTeX/RIS。
-

WorkBuddy不支持私有化部署AI绘画模型,因其本地推理仅兼容llama.cpp的.gguf格式LLM,不支持StableDiffusion等扩散模型;AI绘画实际通过云端腾讯服务执行,非本地运行。