Go语言技术文章
-
 RAG 应用答错时,不要只怪模型。更常见的根因在检索层:切片不合适、召回证据偏题、排序没过滤、回答没有引用约束。复盘时要把用户问题、检索结果、证据片段、模型回答和评测样本串起来,才能真正防复发。468 收藏
RAG 应用答错时,不要只怪模型。更常见的根因在检索层:切片不合适、召回证据偏题、排序没过滤、回答没有引用约束。复盘时要把用户问题、检索结果、证据片段、模型回答和评测样本串起来,才能真正防复发。468 收藏 -
科技周边 · 业界新闻 | 5天前 | WEB开发 · chrome · 业界新闻 · 前端工程 · 浏览器特性 · 滚动事件 Web平台 Chrome 151 Beta WheelEvent momentum
 Chrome 151 Beta 带来了 WheelEvent.momentum,前端可以区分手指直接滚动和触控板惯性滚动,适合长列表、画布缩放和自定义滚动场景做更稳的交互判断。425 收藏
Chrome 151 Beta 带来了 WheelEvent.momentum,前端可以区分手指直接滚动和触控板惯性滚动,适合长列表、画布缩放和自定义滚动场景做更稳的交互判断。425 收藏 -
 Go 1.26 引入实验性的 goroutineleak profile,让协程泄漏排查从经验判断走向可采样的证据链。文章说明适用场景、旧项目影响、灰度接入和最小验证方法。424 收藏
Go 1.26 引入实验性的 goroutineleak profile,让协程泄漏排查从经验判断走向可采样的证据链。文章说明适用场景、旧项目影响、灰度接入和最小验证方法。424 收藏 -
科技周边 · 人工智能 | 4天前 | 人工智能 · ai agent · AI应用 · 工具调用 · 权限边界 · 审计链路 · 人工智能 权限控制 AI Agent 工具调用 审批链路 审计回放 上线指标
 AI Agent 真正接入业务系统时,难点不在能不能调用工具,而在权限闸门、人工审批、参数校验、审计回放和上线观察指标是否齐全。先让 Agent 做低风险查询,再逐步放开写入和自动化动作,会比一次性接管业务流程稳得多。343 收藏
AI Agent 真正接入业务系统时,难点不在能不能调用工具,而在权限闸门、人工审批、参数校验、审计回放和上线观察指标是否齐全。先让 Agent 做低风险查询,再逐步放开写入和自动化动作,会比一次性接管业务流程稳得多。343 收藏 -
 Go 1.26 把 go fix 重写成基于 Go analysis framework 的现代化工具,能批量给旧项目应用更符合新版本的写法。旧项目升级时建议先用 -diff 预览,再分批提交、跑全量测试和灰度发布,不要把自动改写直接混进业务改动里。198 收藏
Go 1.26 把 go fix 重写成基于 Go analysis framework 的现代化工具,能批量给旧项目应用更符合新版本的写法。旧项目升级时建议先用 -diff 预览,再分批提交、跑全量测试和灰度发布,不要把自动改写直接混进业务改动里。198 收藏 -
科技周边 · 业界新闻 | 4天前 | 开发工具 · github copilot · vs code · AI编程 · 业界新闻 · VS Code AI编程 Autopilot GitHub Copilot 模型选择 并行会话 成本可见
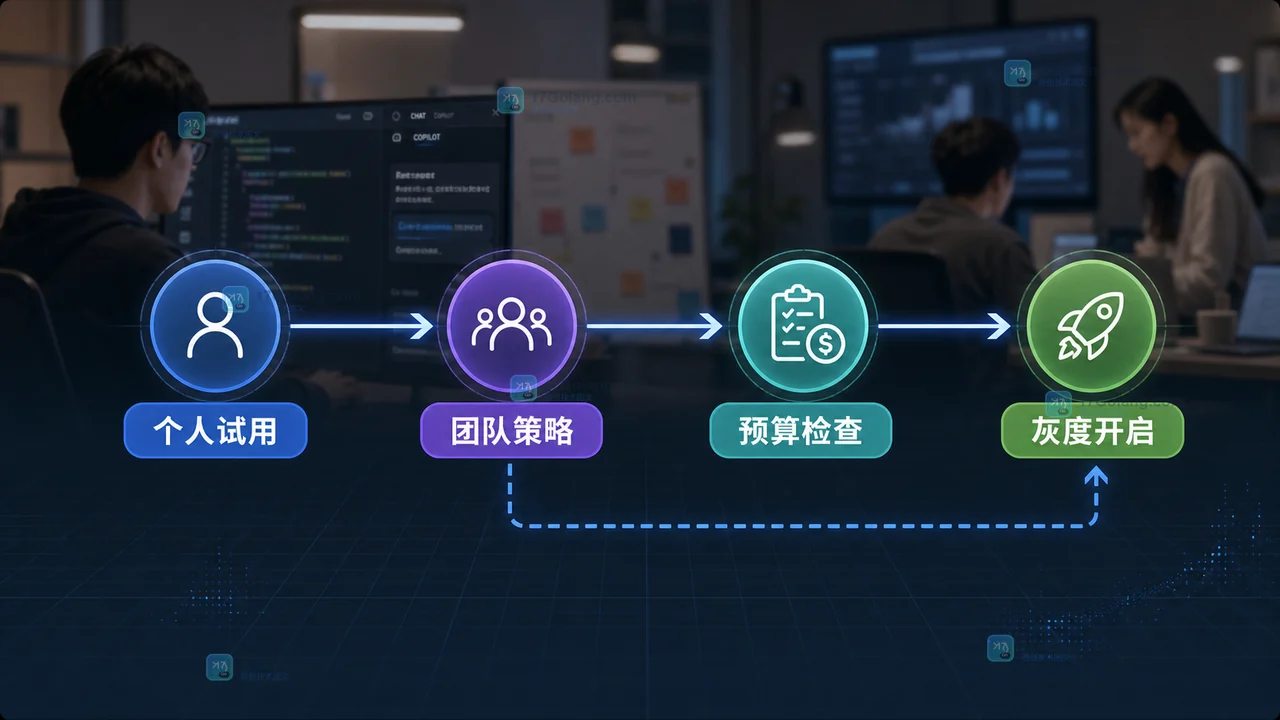 GitHub 7 月 8 日发布的 Copilot in VS Code 更新覆盖 v1.123 到 v1.127,重点不是单个按钮变化,而是把浏览器验证、并行会话、成本可见、模型选择和团队管控连成更完整的代理开发工作流。187 收藏
GitHub 7 月 8 日发布的 Copilot in VS Code 更新覆盖 v1.123 到 v1.127,重点不是单个按钮变化,而是把浏览器验证、并行会话、成本可见、模型选择和团队管控连成更完整的代理开发工作流。187 收藏