-

DeepSeekCoder是专为代码理解与生成优化的大语言模型,支持Python、Java、C++等16种编程语言,其中Python在缩进敏感性、异步语法及框架API识别上表现突出,Java则对JDK8–17特性、SpringBoot注解及Lombok有高精度建模能力。
-

可通过三种方式设置骡子快跑脚本快捷键:一、在热键管理器中绑定组合键并关联脚本;二、用CLI命令行注入JSON格式热键配置;三、在Computer模块创建定时+手动双模自动化流程并生成注册指令。
-

豆包AI可高效生成100个创意点子,操作路径包括:一、设定清晰主题与约束条件;二、采用分层提示词结构分批输出;三、加入非常规限定词激发联想;四、人工关键词干预细化动作;五、交叉验证去重保障多样性。
-

ToClaw跨设备偏好同步有四种方法:一、启用ToDesk云端配置中心自动同步;二、挂载统一配置目录至云盘实现文件级同步;三、通过mem9记忆服务注入结构化偏好元数据;四、配置外部定时任务强制覆盖本地偏好。
-

如果您在小红书发布笔记后长期未被搜索收录,或收录位置靠后,则可能是由于关键词匹配度低、内容与搜索意图偏差较大,或缺乏平台算法识别的高价值信号。以下是利用Kimi辅助分析并落地执行的多种优化路径:一、使用Kimi解析搜索热词结构,定位蓝海词组合Kimi可对小红书公开搜索数据进行语义聚类与竞争度建模,帮助识别“高搜索指数+低笔记量”的真实蓝海词。其核心逻辑是绕过表面热度,聚焦用户真实提问句式与未被充分满足的需求切口。1、在Kimi中输入行业主词(如“护肤”“辅食”“通勤穿搭”),选择“小红书语境专项分
-

HermesAgent成本取决于API调用频次、Token消耗及模型单价,公有云路径月成本约$101.2,私有化本地推理约$11.84,Serverless模式仅$0.417,记忆与技能复用月减支$0.456,提示词优化月省$35.39。
-

即梦AI的高清修复工具可以有效修复画质模糊的问题。使用方法包括:1.上传图片并选择修复模式,2.调整锐化程度和噪点处理参数,3.解决常见问题如多次调整参数或联系客服,4.注意上传高质量图片、避免过度使用高级模式并保存中间结果。
-

如果您希望利用人工智能技术构建一个功能完整的智能客服机器人,Rasa作为主流开源对话框架,提供了从自然语言理解到多轮对话管理的全栈能力。以下是基于Rasa搭建对话系统的具体实施路径:一、初始化Rasa项目并配置基础环境该步骤旨在建立符合Rasa规范的项目骨架与运行依赖,确保后续NLU训练和对话策略部署具备标准化结构。Rasa要求明确划分数据、配置、模型与服务模块,避免路径混乱导致训练失败。1、在终端中执行rasainit命令,自动创建含domain.yml、config.yml、data/nlu/
-

100万Token可生成1123篇标准小红书笔记(890Token/篇),轻量模板下达1886篇,分段生成提升至1320篇以上,并受表情、多版本、地域指令、风格切换、排版处理及设备差异等影响。
-

需获取MiniMax工作空间共享链接,可通过三种方式:一、团队管理界面点击“复制邀请链接”;二、详情页提取6位邀请码并拼接至基础域名;三、调用API接口动态获取带时效的签名链接。
-

用AI写营销文案效率高但内容常欠缺人味,搭配Deepseek和Copy.ai可批量产出优质文案。先用Deepseek做初稿:输入清晰指令快速生成结构化草稿,多试几次选出最佳方向;再交由Copy.ai润色:通过语气调整使语言更自然吸引人,提升文案转化率;最后结合模板与变量批量操作,统一风格并高效复制,从而实现高质量、高效率的文案生产流程。
-
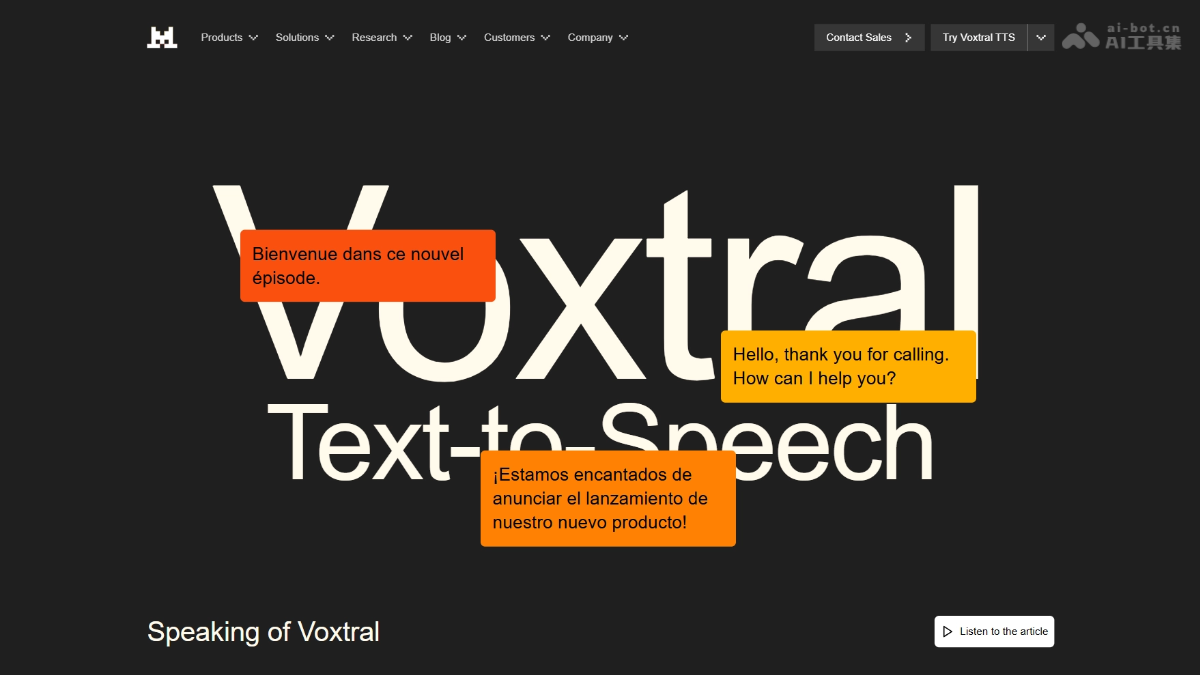
VoxtralTTS是什么VoxtralTTS是由MistralAI推出的开源文本转语音(TTS)模型,基于约40亿参数的混合架构,原生支持英语、法语、德语、西班牙语、荷兰语、葡萄牙语、意大利语、印地语与阿拉伯语共9种语言。该模型具备业界领先的90毫秒首音延迟和高达6倍实时的语音生成能力;仅需3–5秒目标说话人音频即可完成零样本语音克隆。模型经量化后内存占用低至3GB,可直接部署于边缘设备;其API服务定价为$0.016/千字符。作为Mistral全栈语音
-

DeepSeek对话痕迹可通过五种方式清除:一、网页端单条或批量删除;二、APP内账户页删除全部历史;三、账户设置中管理云端数据;四、手动清除本地缓存;五、关闭自动保存功能。
-

通过构建用户画像实现豆包AI个性化推送:一、基于关键词提取锁定兴趣领域,适用于冷启动阶段;二、结合行为数据深化画像维度,分析点击、停留等互动记录;三、利用AI云盘解析日程计划等文件,实现情境化内容匹配;四、通过多轮对话动态校准画像,持续优化推荐精度。
-

可利用CodeGeeX生成符合Wire规范的注入代码:一、明确声明模块结构与依赖类型;二、用结构化提示触发精准生成;三、处理同类型字段歧义;四、集成go:generate实现一键刷新。