Go语言技术文章
-
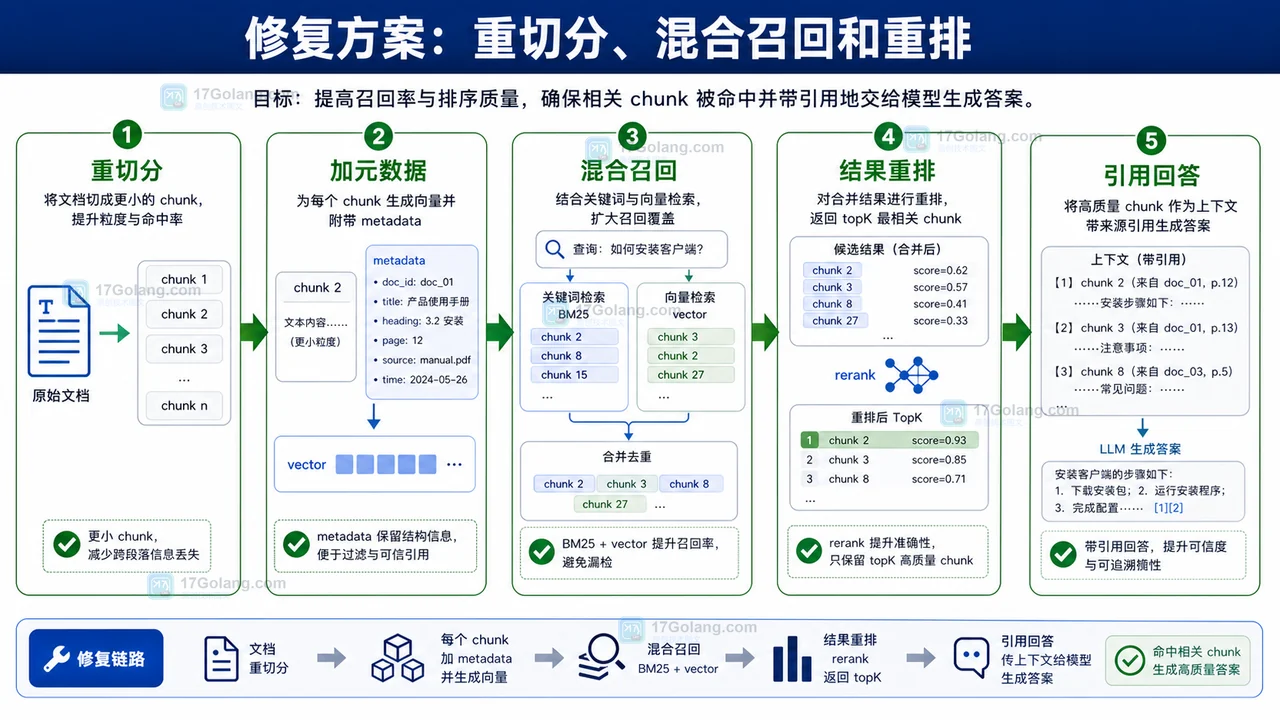 本文用代入式排查方式讲解 RAG 知识库明明有资料却答不上来的常见原因:分块过大、元数据缺失、召回偏离和排序不准,并给出重切分、混合召回、结果重排和引用验证流程。453 收藏
本文用代入式排查方式讲解 RAG 知识库明明有资料却答不上来的常见原因:分块过大、元数据缺失、召回偏离和排序不准,并给出重切分、混合召回、结果重排和引用验证流程。453 收藏 -
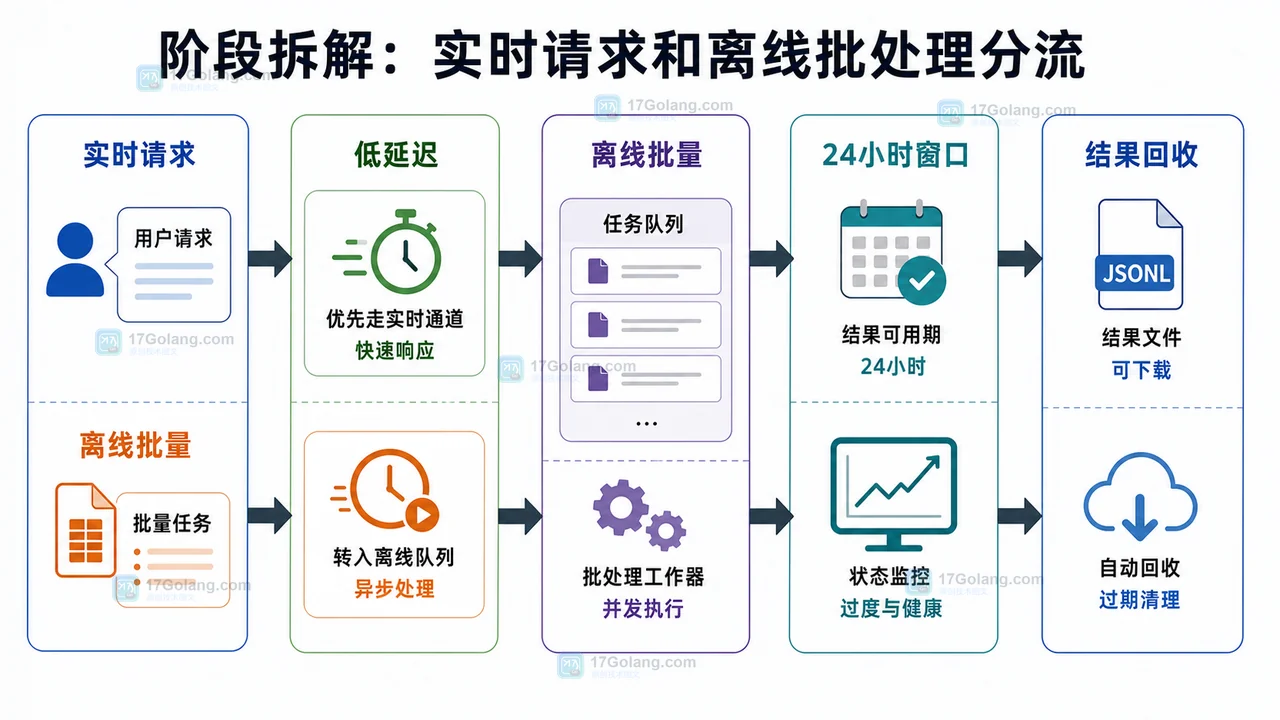 本文给出一套 AI 批量调用成本控制工作流:记录请求日志、估算 token、设置预算阈值、区分实时和离线任务,并用账单复查闭环防止成本失控。202 收藏
本文给出一套 AI 批量调用成本控制工作流:记录请求日志、估算 token、设置预算阈值、区分实时和离线任务,并用账单复查闭环防止成本失控。202 收藏 -
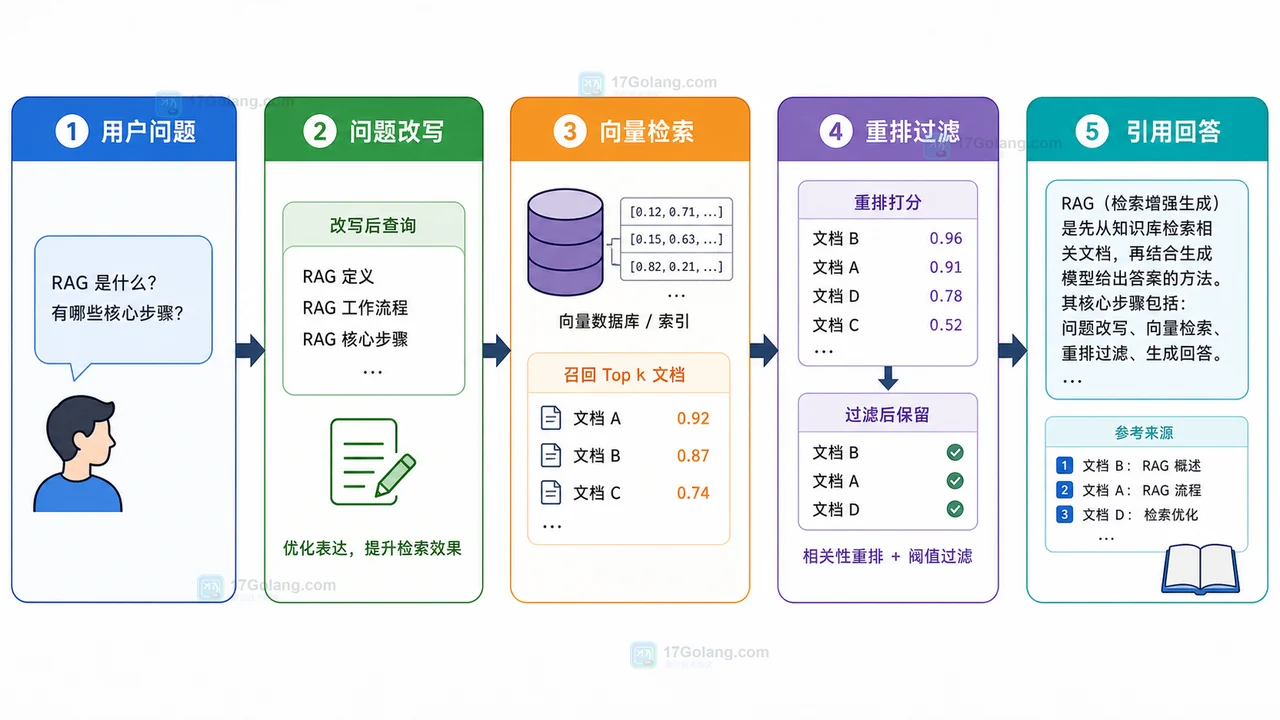 本文用知识库问答跑偏的真实工程场景,拆解 RAG 从问题改写、向量检索、重排过滤、分数阈值到引用检查的完整流程,帮助你把“模型乱答”改成可排查、可复查、可拒答的系统。419 收藏
本文用知识库问答跑偏的真实工程场景,拆解 RAG 从问题改写、向量检索、重排过滤、分数阈值到引用检查的完整流程,帮助你把“模型乱答”改成可排查、可复查、可拒答的系统。419 收藏 -
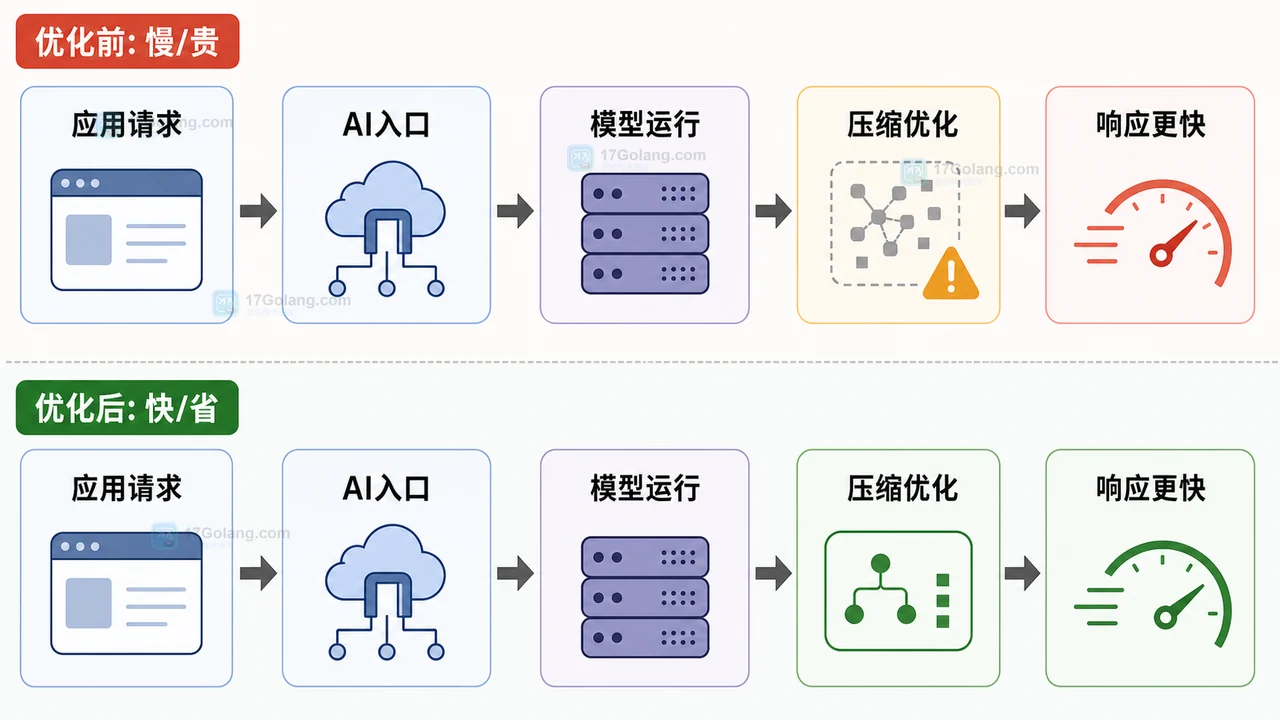 Cloudflare 官方博客披露 Ensemble AI 团队加入后,AI 推理平台竞争再次聚焦延迟、成本和模型优化。本文整理事实、影响和开发团队的检查清单。430 收藏
Cloudflare 官方博客披露 Ensemble AI 团队加入后,AI 推理平台竞争再次聚焦延迟、成本和模型优化。本文整理事实、影响和开发团队的检查清单。430 收藏 -
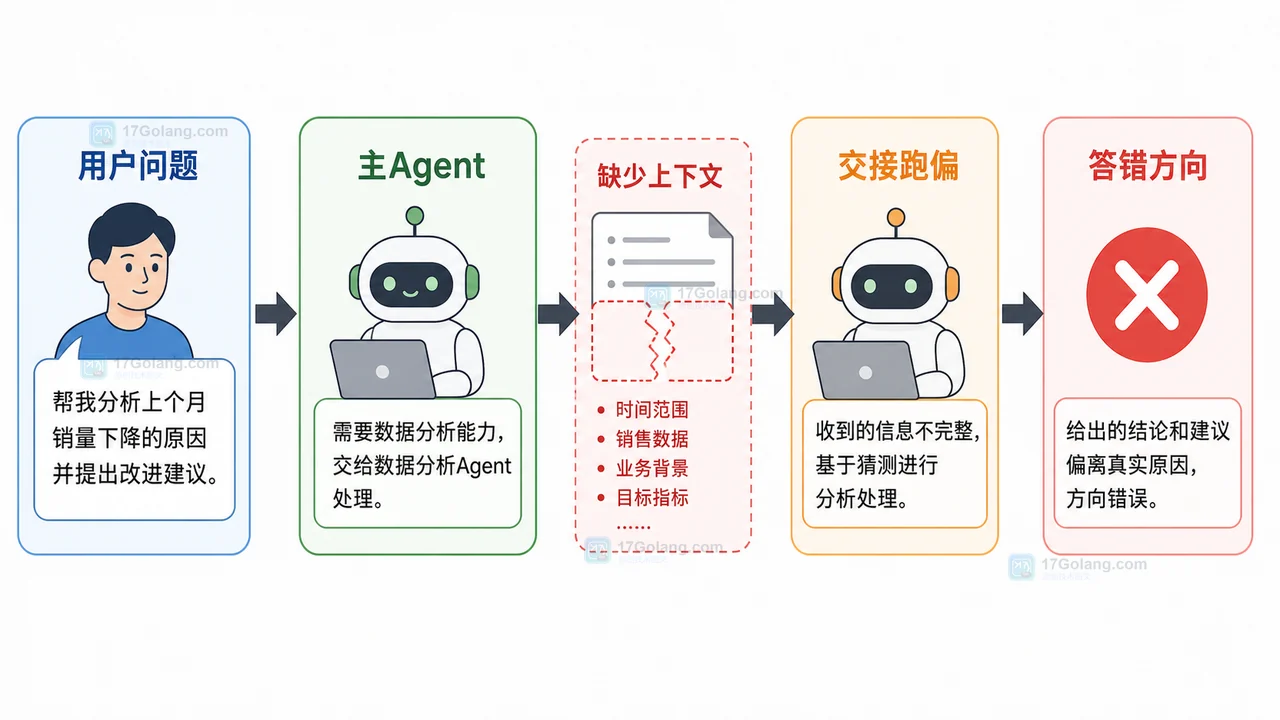 从一个 AI Agent 把任务交给错误方向的案例出发,排查意图识别、边界规则、上下文摘要和结果复查四个环节,给出可落地的交接治理流程。170 收藏
从一个 AI Agent 把任务交给错误方向的案例出发,排查意图识别、边界规则、上下文摘要和结果复查四个环节,给出可落地的交接治理流程。170 收藏 -
科技周边 · 业界新闻 | 1个月前 | 业界新闻 · Cloudflare · AI Gateway · Spend Limits · AI成本 · Cloudflare AI Gateway Spend Limits AI成本治理 AI预算 模型降级
 Cloudflare 在 2026-06-05 发布 AI Gateway Spend Limits,面向 AI 调用成本失控问题提供预算规则、超额阻断和动态路由能力。本文用完整流程拆解团队如何从请求记录、预算设置到模型降级建立成本治理闭环。495 收藏
Cloudflare 在 2026-06-05 发布 AI Gateway Spend Limits,面向 AI 调用成本失控问题提供预算规则、超额阻断和动态路由能力。本文用完整流程拆解团队如何从请求记录、预算设置到模型降级建立成本治理闭环。495 收藏 -
科技周边 · 业界新闻 | 1个月前 | Node.js · javascript · 安全版本 · 运行时 · 升级排查 · 业界新闻 Node.js安全版本 Node.js 26.3.0 运行时升级 JavaScript安全
 Node.js 官方预告 2026-06-17 前后将为 26.x、24.x、22.x 发布安全版本。本文用问题排查的方式,带你从公告确认、版本线判断、回归测试到灰度发布,整理一套不慌不乱的升级检查流程。308 收藏
Node.js 官方预告 2026-06-17 前后将为 26.x、24.x、22.x 发布安全版本。本文用问题排查的方式,带你从公告确认、版本线判断、回归测试到灰度发布,整理一套不慌不乱的升级检查流程。308 收藏 -
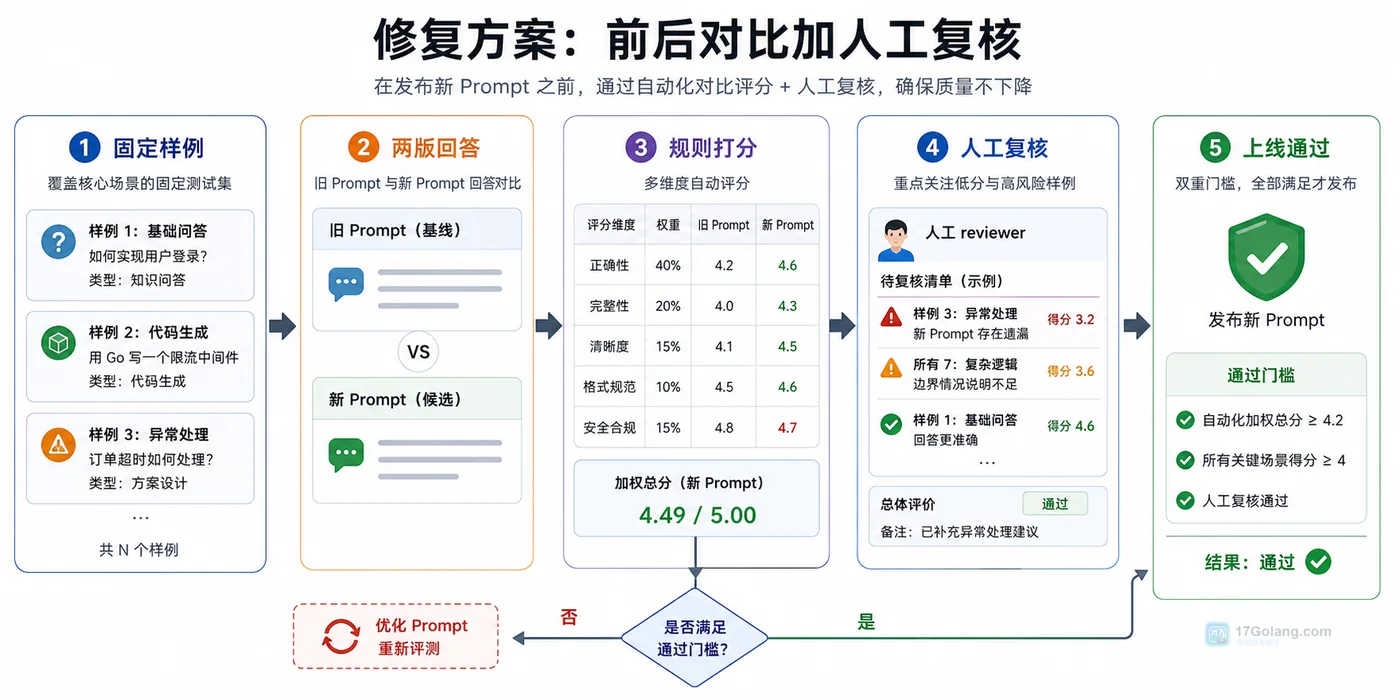 提示词一改,AI 回答可能变好,也可能让旧场景退化。本文从一次改提示词后回答跑偏的现场开始,带你搭建小样本集、评分规则、前后对比和人工复核流程,让提示词上线前有据可查。475 收藏
提示词一改,AI 回答可能变好,也可能让旧场景退化。本文从一次改提示词后回答跑偏的现场开始,带你搭建小样本集、评分规则、前后对比和人工复核流程,让提示词上线前有据可查。475 收藏 -
科技周边 · 人工智能 | 1个月前 | 人工智能 · tracing · ai agent · 可观测性 · 工具调用 · 可观测性 AI Agent Tracing 工具调用 OpenAI Agents SDK
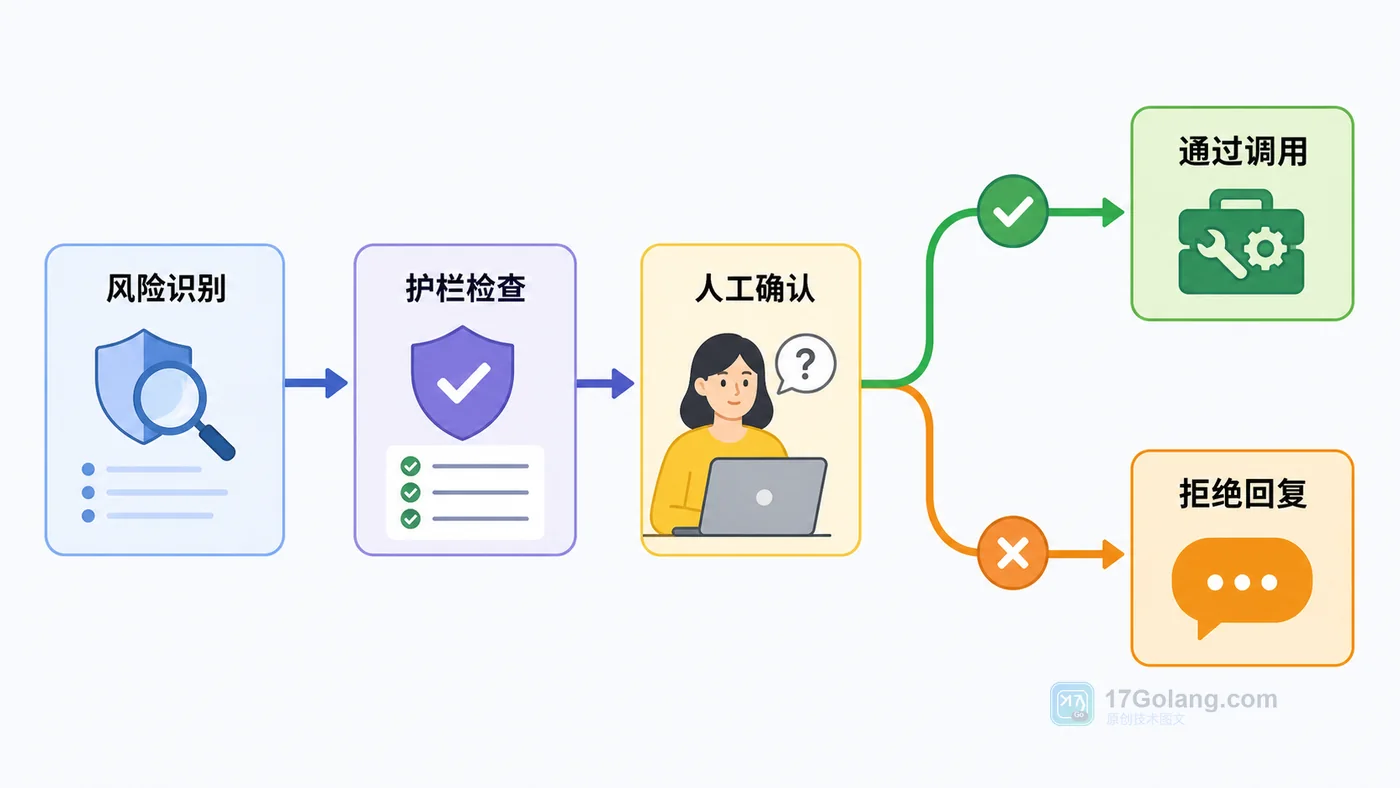 本文用客服查询 Agent 场景讲清 AI Agent Tracing 的落地方法:把模型调用、工具调用、护栏检查、人工确认和最终结果拆成 trace 与 span,方便调试、复盘和监控。292 收藏
本文用客服查询 Agent 场景讲清 AI Agent Tracing 的落地方法:把模型调用、工具调用、护栏检查、人工确认和最终结果拆成 trace 与 span,方便调试、复盘和监控。292 收藏 -
科技周边 · 业界新闻 | 1个月前 | devops · CI/CD · gitHub actions · 业界新闻 · 自托管Runner · DevOps CI/CD GitHub Actions self-hosted runner Runner升级
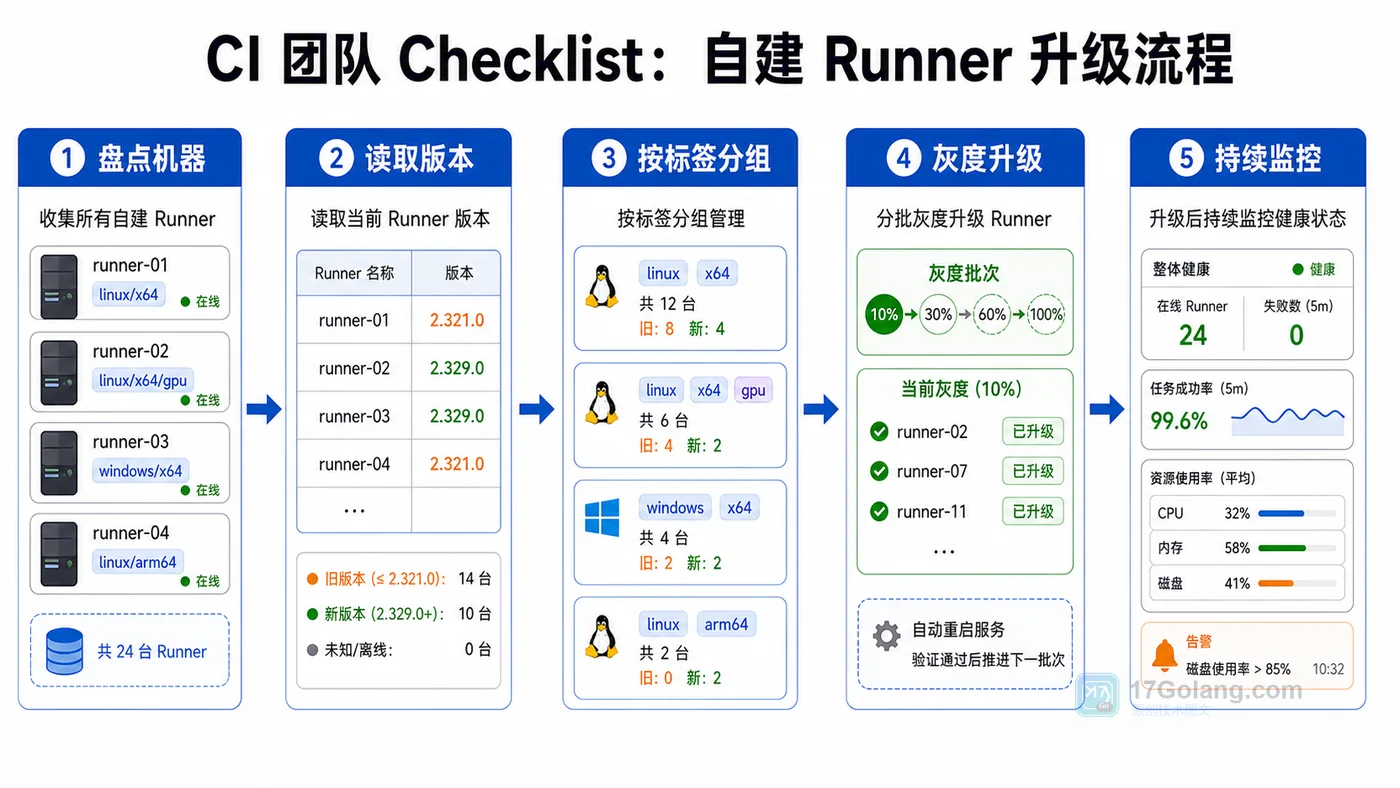 GitHub 公布 Actions 自托管 Runner 最低版本强制时间线:新注册 Runner 需要 2.329.0+,GHEC Data Residency 与 GHEC 将分阶段生效,CI 团队应提前盘点、升级和监控。431 收藏
GitHub 公布 Actions 自托管 Runner 最低版本强制时间线:新注册 Runner 需要 2.329.0+,GHEC Data Residency 与 GHEC 将分阶段生效,CI 团队应提前盘点、升级和监控。431 收藏 -
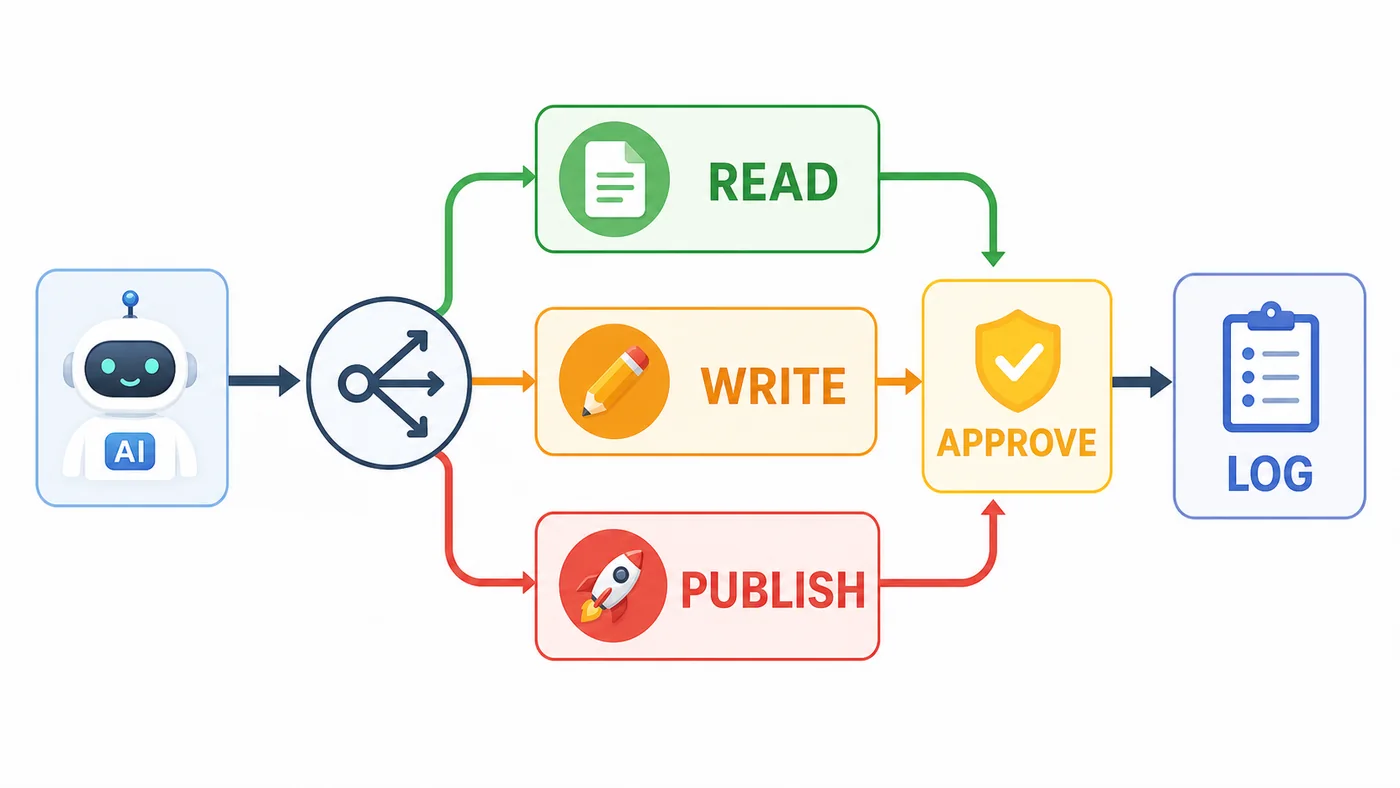 AI Agent 接入工具后,不能把所有动作都当成同一风险级别。本文用读、写、发布三类权限拆解工具治理流程:参数校验、风险判断、人工确认、调用落库和审计追踪。379 收藏
AI Agent 接入工具后,不能把所有动作都当成同一风险级别。本文用读、写、发布三类权限拆解工具治理流程:参数校验、风险判断、人工确认、调用落库和审计追踪。379 收藏 -
科技周边 · 业界新闻 | 1个月前 | github · gitHub actions · 业界新闻 · AI代理 · GitHub AI代理 GitHub Actions Agentic Workflows CI分析 Issue分流 工程自动化
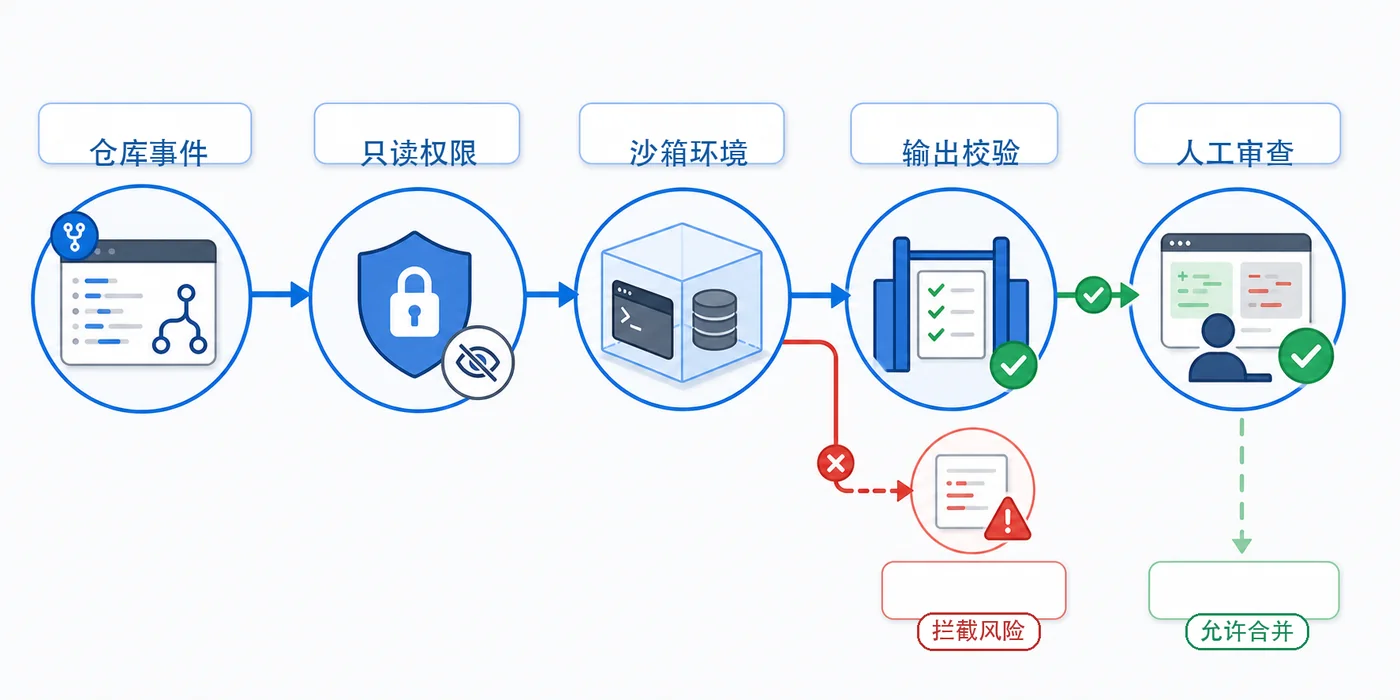 GitHub Agentic Workflows 已进入 public preview,开发团队可以用 Markdown 描述任务,再编译为 Actions YAML,把 Issue 分流、CI 失败分析、文档更新等推理型任务交给代理流水线处理。354 收藏
GitHub Agentic Workflows 已进入 public preview,开发团队可以用 Markdown 描述任务,再编译为 Actions YAML,把 Issue 分流、CI 失败分析、文档更新等推理型任务交给代理流水线处理。354 收藏 -
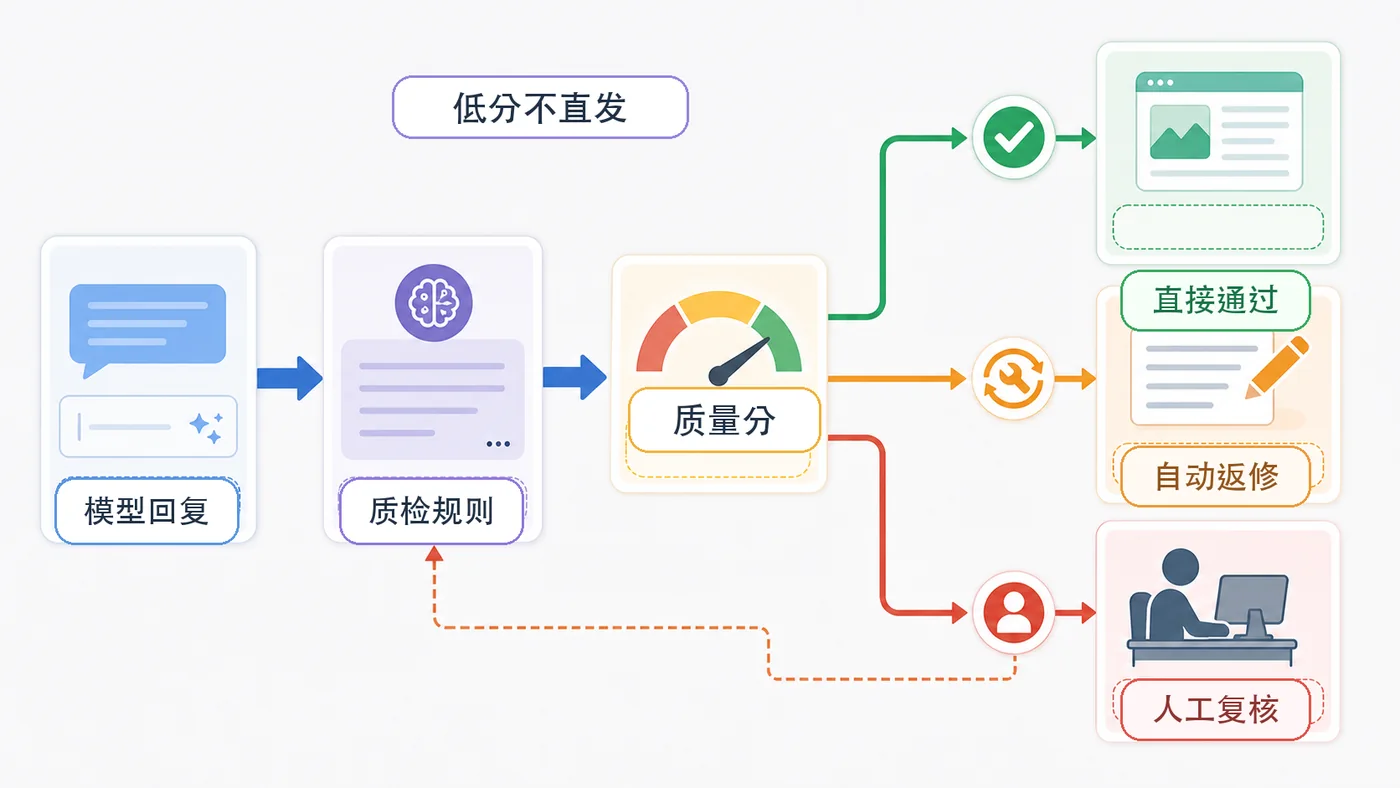 本文用内容生成场景演示一条可落地的 AI 输出质检流水线:先做规则检查,再要求结构化结果,低分输出进入自动返修或人工兜底。394 收藏
本文用内容生成场景演示一条可落地的 AI 输出质检流水线:先做规则检查,再要求结构化结果,低分输出进入自动返修或人工兜底。394 收藏 -
科技周边 · 业界新闻 | 1个月前 | 安全 · CI/CD · gitHub actions · 业界新闻 · 开发者工具 · 代码审查 供应链安全 业界新闻 GitHub Actions 机器人PR CI安全
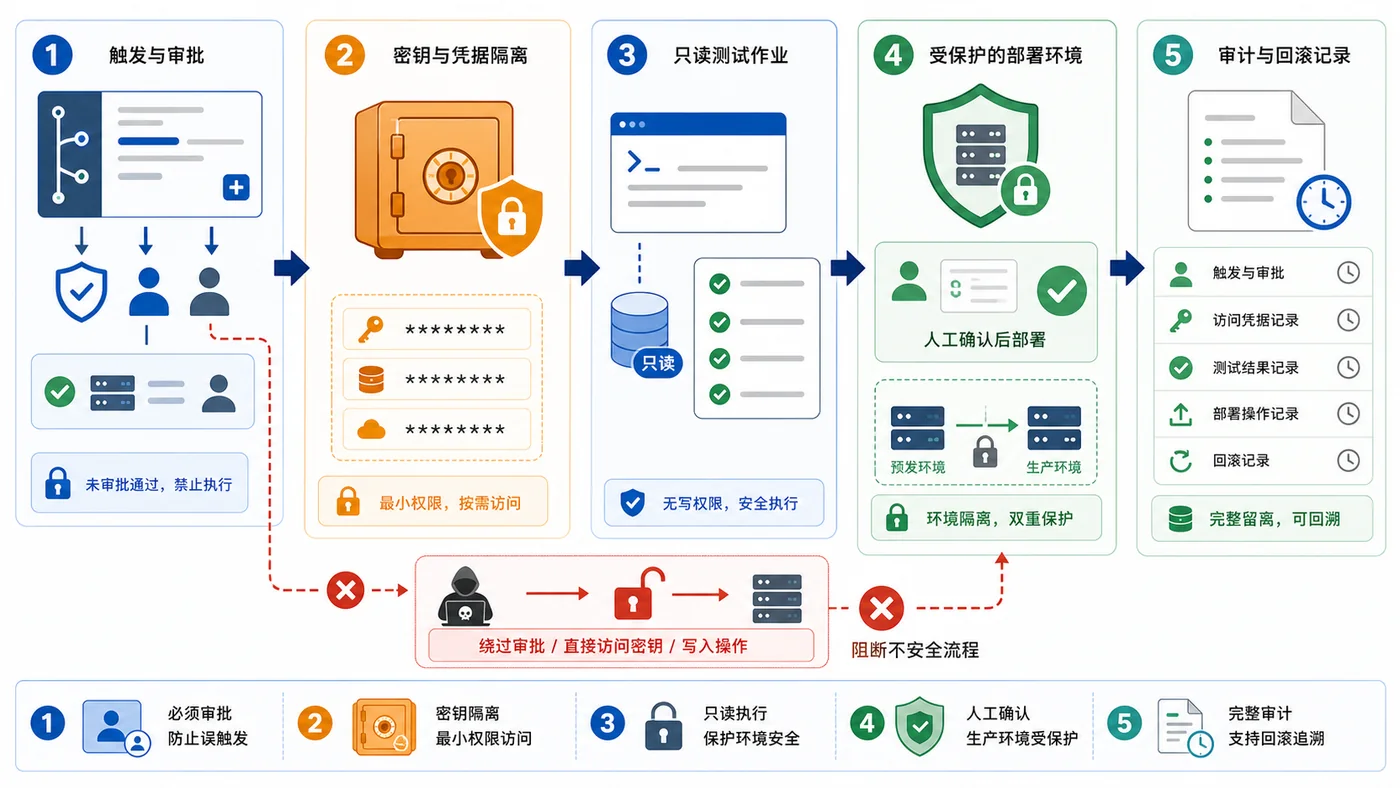 本文结合 GitHub 官方 Changelog,分析机器人创建的 PR 运行工作流前需要审批这一变化,提醒团队重新梳理 CI/CD 权限、密钥和审查边界。473 收藏
本文结合 GitHub 官方 Changelog,分析机器人创建的 PR 运行工作流前需要审批这一变化,提醒团队重新梳理 CI/CD 权限、密钥和审查边界。473 收藏 -
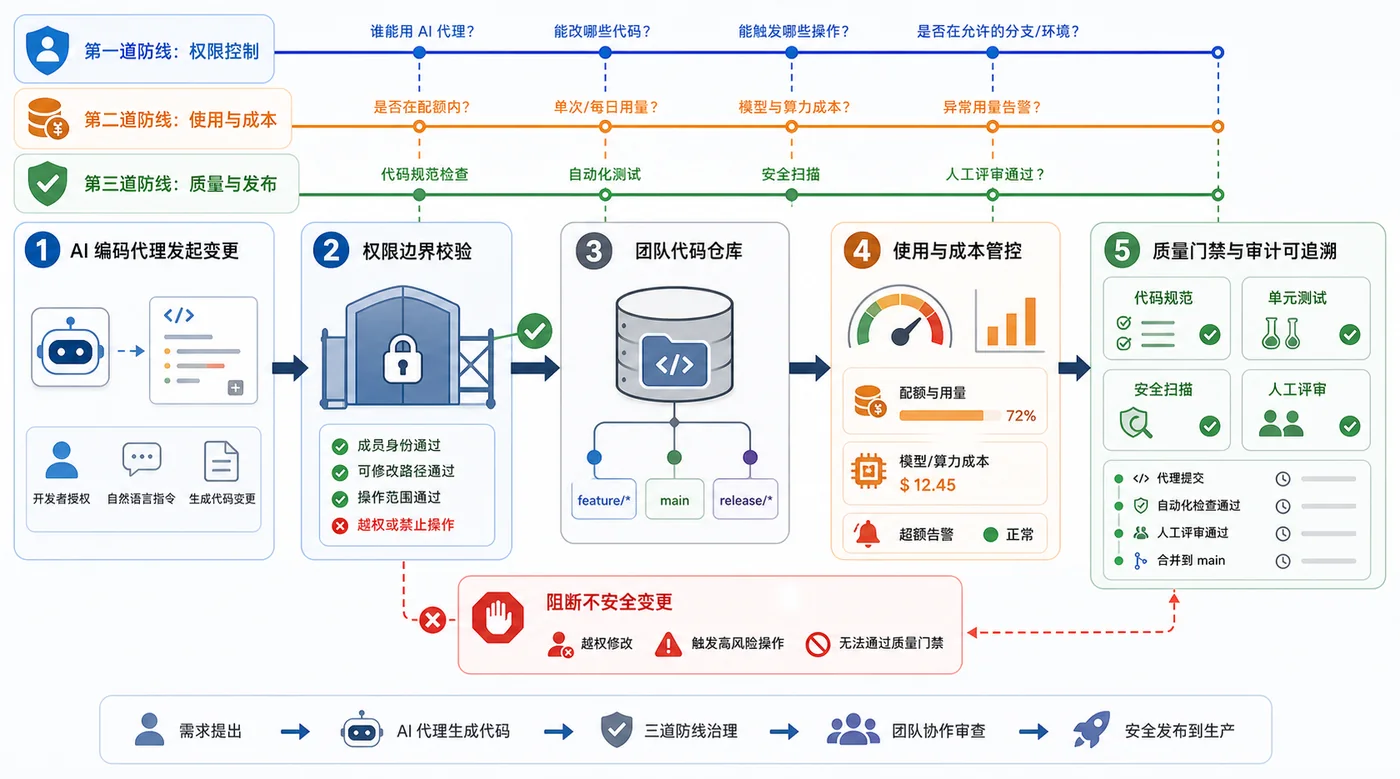 本文结合 Microsoft Build、Google I/O、GitHub Changelog 和 OpenAI 官方动态,梳理 AI 编程代理从单点问答进入工程主流程的三个信号。214 收藏
本文结合 Microsoft Build、Google I/O、GitHub Changelog 和 OpenAI 官方动态,梳理 AI 编程代理从单点问答进入工程主流程的三个信号。214 收藏