-
 真正导致堆栈轨迹极度碎片化的是异步边界跨越叠加异常创建,而非闭包嵌套本身;应通过上下文透传、禁用无意义异常、结构化并发收编来解决。154 收藏
真正导致堆栈轨迹极度碎片化的是异步边界跨越叠加异常创建,而非闭包嵌套本身;应通过上下文透传、禁用无意义异常、结构化并发收编来解决。154 收藏 -
文章 · java教程 | 1星期前 | 工程化 · Spring Boot · junit · Java教程 · Testcontainers · java 集成测试 spring boot JUnit 5 Testcontainers
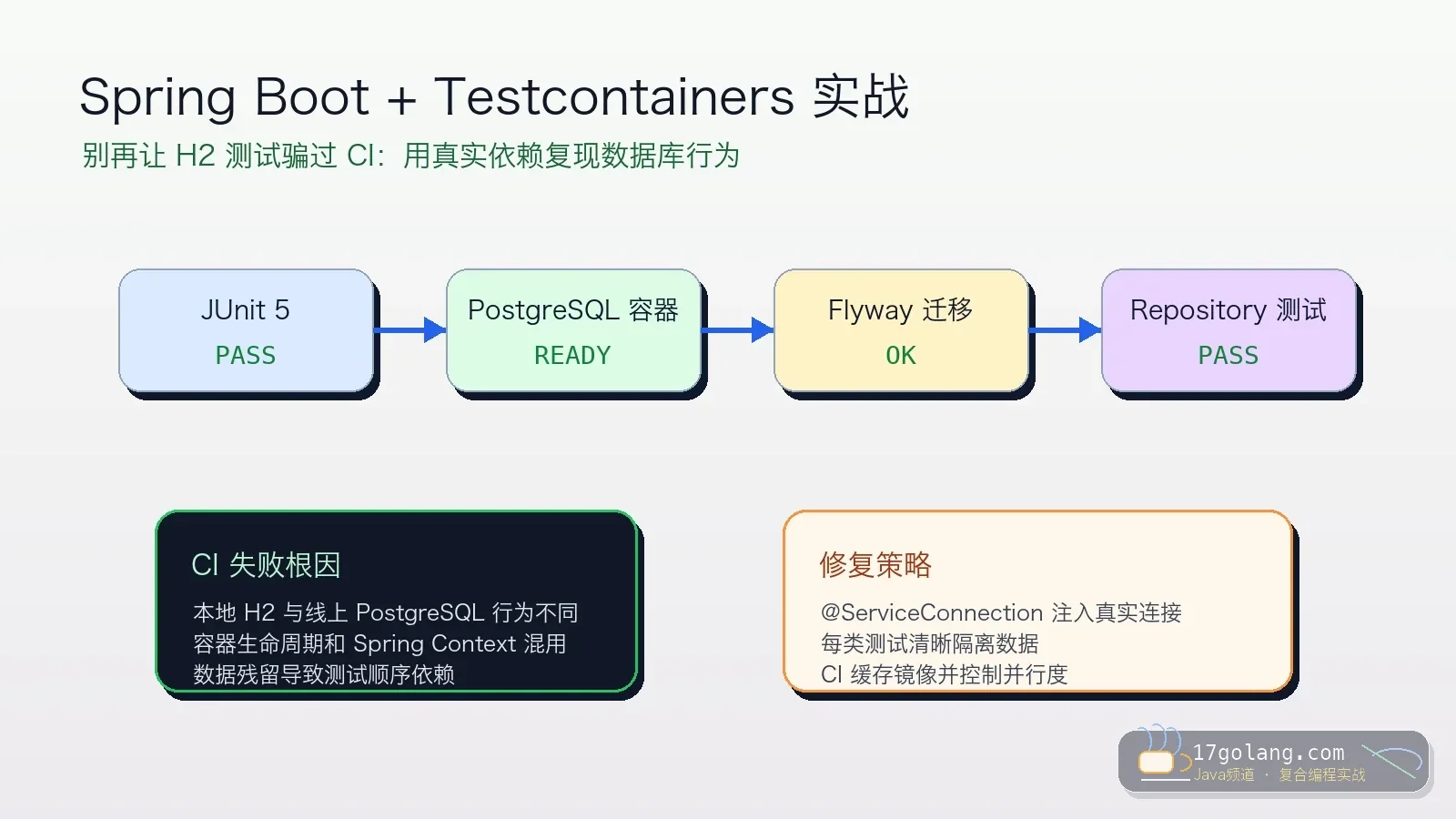 一篇 Java/Spring Boot 集成测试实战:用 Testcontainers 和 JUnit 5 让数据库、迁移脚本、约束和 CI 行为更接近生产,解决 H2 测试全绿但预发翻车的问题。154 收藏
一篇 Java/Spring Boot 集成测试实战:用 Testcontainers 和 JUnit 5 让数据库、迁移脚本、约束和 CI 行为更接近生产,解决 H2 测试全绿但预发翻车的问题。154 收藏 -
 本文介绍如何仅使用基础数组结构,在单次遍历(O(n))时间复杂度内高效定位数组中最大值的全部重复出现位置,纠正关于“双循环必为O(n²)”的常见误解。153 收藏
本文介绍如何仅使用基础数组结构,在单次遍历(O(n))时间复杂度内高效定位数组中最大值的全部重复出现位置,纠正关于“双循环必为O(n²)”的常见误解。153 收藏 -
 FileNotFoundException常在文件读写时因路径错误或文件不存在而抛出,需用try-catch捕获并给出具体提示,结合try-with-resources自动释放资源,提升程序健壮性与用户体验。153 收藏
FileNotFoundException常在文件读写时因路径错误或文件不存在而抛出,需用try-catch捕获并给出具体提示,结合try-with-resources自动释放资源,提升程序健壮性与用户体验。153 收藏 -
 Maven项目中的依赖并非无条件加入运行时类路径,其实际行为取决于打包类型、作用域(scope)及所用插件——编译期默认包含compile和provided依赖,而运行时是否包含则由构建目标(如JAR/WAR/SpringBoot可执行包)决定。153 收藏
Maven项目中的依赖并非无条件加入运行时类路径,其实际行为取决于打包类型、作用域(scope)及所用插件——编译期默认包含compile和provided依赖,而运行时是否包含则由构建目标(如JAR/WAR/SpringBoot可执行包)决定。153 收藏 -
 抽象类不能直接实例化,普通类可以;抽象类定义通用结构并强制子类实现抽象方法,普通类封装具体功能;模板方法模式利用该特性将算法骨架放在抽象类中,可变步骤延迟至子类实现。153 收藏
抽象类不能直接实例化,普通类可以;抽象类定义通用结构并强制子类实现抽象方法,普通类封装具体功能;模板方法模式利用该特性将算法骨架放在抽象类中,可变步骤延迟至子类实现。153 收藏 -
 Collections.frequency适用于单元素频次统计,语义清晰但仅支持精确equals比较;Stream.groupingBy适合全量频次统计,性能更优但需注意null键和自定义对象的equals/hashCode实现。153 收藏
Collections.frequency适用于单元素频次统计,语义清晰但仅支持精确equals比较;Stream.groupingBy适合全量频次统计,性能更优但需注意null键和自定义对象的equals/hashCode实现。153 收藏 -
 静态块不能抛出受检异常,否则编译失败;若抛出未捕获异常(含RuntimeException),类初始化失败,后续所有对该类的主动使用均抛NoClassDefFoundError。153 收藏
静态块不能抛出受检异常,否则编译失败;若抛出未捕获异常(含RuntimeException),类初始化失败,后续所有对该类的主动使用均抛NoClassDefFoundError。153 收藏 -
 因为JVM的tableswitch和lookupswitch指令要求跳转目标在类加载时确定,故case必须是编译期常量;否则编译报错“constantexpressionrequired”,不退化为if-else。153 收藏
因为JVM的tableswitch和lookupswitch指令要求跳转目标在类加载时确定,故case必须是编译期常量;否则编译报错“constantexpressionrequired”,不退化为if-else。153 收藏 -
 Java对象内存布局分为对象头、实例数据、对齐填充三部分;对象头含MarkWord(存哈希码、锁状态等)和类型指针(指向类元数据);实例数据按宽度重排序存储字段值;对齐填充确保对象总大小为8字节倍数。153 收藏
Java对象内存布局分为对象头、实例数据、对齐填充三部分;对象头含MarkWord(存哈希码、锁状态等)和类型指针(指向类元数据);实例数据按宽度重排序存储字段值;对齐填充确保对象总大小为8字节倍数。153 收藏 -
 抽象方法的核心作用是强制子类实现特定方法,统一流程骨架并保留实现灵活性;需用abstract修饰、无方法体,所在类也须为abstract;不可为private或final,推荐public;常用于模板方法模式,配合钩子方法提升扩展性。153 收藏
抽象方法的核心作用是强制子类实现特定方法,统一流程骨架并保留实现灵活性;需用abstract修饰、无方法体,所在类也须为abstract;不可为private或final,推荐public;常用于模板方法模式,配合钩子方法提升扩展性。153 收藏 -
 synchronized修饰方法能保证自增线程安全,但仅适用于简单场景;它本质是把整个方法变成临界区,靠对象锁互斥执行,性能开销明显,且无法应对跨方法的复合操作。153 收藏
synchronized修饰方法能保证自增线程安全,但仅适用于简单场景;它本质是把整个方法变成临界区,靠对象锁互斥执行,性能开销明显,且无法应对跨方法的复合操作。153 收藏 -
 在Quarkus中使用@InjectMock时,被测类的所有方法默认被空实现覆盖,导致内部方法调用无法触发真实逻辑;需显式配置thenCallRealMethod()才能实现对类内方法(如get())的可控模拟。153 收藏
在Quarkus中使用@InjectMock时,被测类的所有方法默认被空实现覆盖,导致内部方法调用无法触发真实逻辑;需显式配置thenCallRealMethod()才能实现对类内方法(如get())的可控模拟。153 收藏 -
 魔数须为4字节固定int型(如0x12345678)以区分非法连接,版本字段占1字节便于平滑升级;长度字段紧随其后且定长4字节,表示消息体字节数并校验上限;消息体首选Protobuf,避免嵌套过深,不加应用层分隔符。153 收藏
魔数须为4字节固定int型(如0x12345678)以区分非法连接,版本字段占1字节便于平滑升级;长度字段紧随其后且定长4字节,表示消息体字节数并校验上限;消息体首选Protobuf,避免嵌套过深,不加应用层分隔符。153 收藏 -
 os.path.exists()用于判断路径是否存在,返回True或False;它不区分文件与目录,需配合os.path.isfile()或os.path.isdir()确认类型;相对路径依赖当前工作目录,建议转绝对路径;权限不足、损坏软链接或网络设备未挂载时均返回False。153 收藏
os.path.exists()用于判断路径是否存在,返回True或False;它不区分文件与目录,需配合os.path.isfile()或os.path.isdir()确认类型;相对路径依赖当前工作目录,建议转绝对路径;权限不足、损坏软链接或网络设备未挂载时均返回False。153 收藏