LeCun 的世界模型初步实现!基于预训练视觉特征,看一眼任务就能零样本规划
来源:机器之心
时间:2024-11-19 12:57:55 292浏览 收藏
大家好,今天本人给大家带来文章《LeCun 的世界模型初步实现!基于预训练视觉特征,看一眼任务就能零样本规划》,文中内容主要涉及到,如果你对科技周边方面的知识点感兴趣,那就请各位朋友继续看下去吧~希望能真正帮到你们,谢谢!
在 LLM 应用不断迭代升级更新的当下,图灵奖得主 Yann LeCun 却代表了一股不同的声音。他在许多不同场合都反复重申了自己的一个观点:当前的 LLM 根本无法理解世界。他曾说过:LLM「理解逻辑的能力非常有限…… 无法理解物理世界,没有持续性记忆,不能推理(只要推理的定义是合理的)、不能规划。」

Yann LeCun 批评 LLM 的推文之一
相反,他更注重所谓的世界模型(World Model),也就是根据世界数据拟合的一个动态模型。比如驴,正是有了这样的世界模型,它们才能找到更省力的负重登山方法。
近日,LeCun 团队发布了他们在世界模型方面的一项新研究成果:基于预训练的视觉特征训练的世界模型可以实现零样本规划!也就是说该模型无需依赖任何专家演示、奖励建模或预先学习的逆向模型。

- 论文标题:DINO-WM: World Models on Pre-trained Visual Features enable Zero-shot Planning
- 论文地址:https://arxiv.org/pdf/2411.04983v1
- 项目地址:https://dino-wm.github.io/
该团队提出的 DINO-WM 是一种可基于离线的轨迹数据集构建与任务无关的世界模型的简单新方法。据介绍,DINO-WM 是基于世界的紧凑嵌入建模世界的动态,而不是使用原始的观察本身。
对于嵌入,他们使用的是来自 DINOv2 模型的预训练图块特征,其能提供空间的和以目标为中心的表征先验。该团队推测,这种预训练的表征可实现稳健且一致的世界建模,从而可放宽对具体任务数据的需求。
有了这些视觉嵌入和动作后,DINO-WM 会使用 ViT 架构来预测未来嵌入。
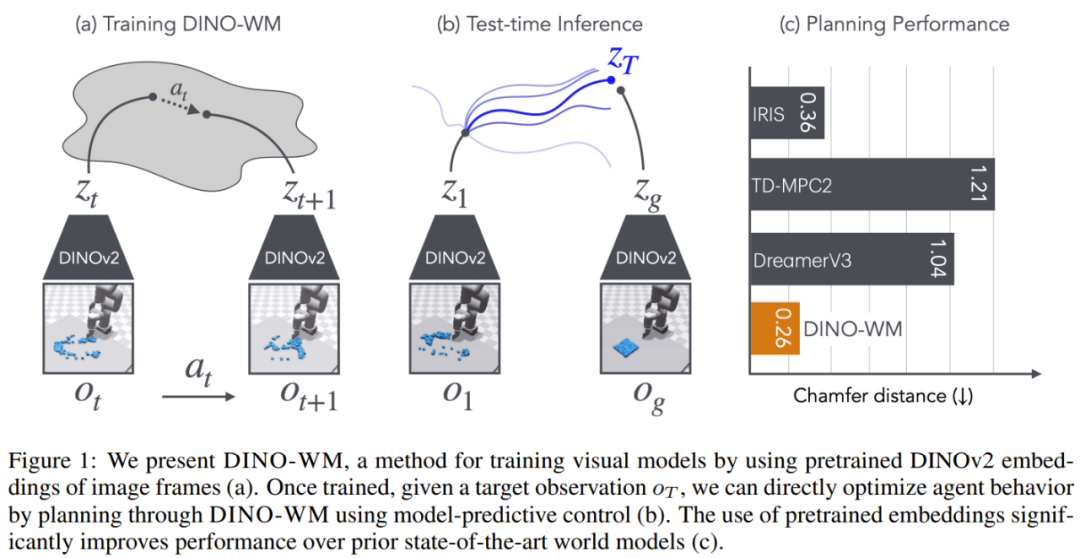
完成模型训练之后,在解决任务时,规划会被构建成视觉目标的达成,即给定当前观察达成未来的预期目标。由于 DINO-WM 的预测质量很高,于是就可以简单地使用模型预测控制和推理时间优化来达成期望的目标,而无需在测试期间使用任何额外信息。
DINO 世界模型
概述和问题表述:该研究遵循基于视觉的控制任务框架,即将环境建模为部分可观察的马尔可夫决策过程 (POMDP)。POMDP 可定义成一个元组 (O, A, p),其中 O 表示观察空间,A 表示动作空间。p (o_{t+1} | o≤t, a≤t) 是一个转移分布,建模了环境的动态,可根据过去的动作和观察预测未来的观察。
这项研究的目标是从预先收集的离线数据集中学习与任务无关的世界模型,然后在测试时间使用这些世界模型来执行视觉推理。
在测试时间,该系统可从一个任意的环境状态开始,然后根据提供的目标观察(RGB 图像形式),执行一系列动作 a_0, ..., a_T,使得目标状态得以实现。
该方法不同于在线强化学习中使用的世界模型,其目标是优化手头一组固定任务的奖励;也不同于基于文本的世界模型,其目标需要通过文本提示词指定。
基于 DINO 的世界模型(DINO-WM)
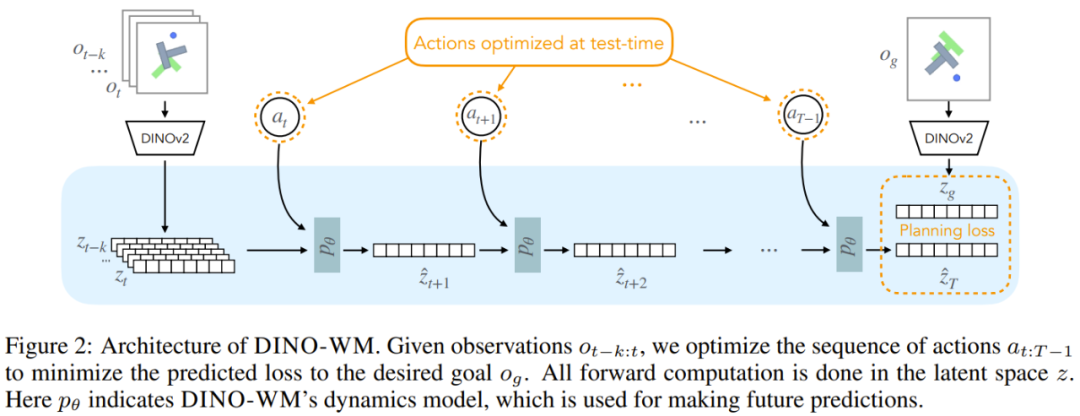
该团队将环境动态建模到了隐藏空间中。更具体而言,在每个时间步骤 t,该世界模型由以下组分构成:

其中,观察模型是将图像观察编码成隐藏状态 z_t,而转移模型则是以长度为 H 的过去隐藏状态历史为输入。解码器模型则是以隐藏的 z_t 为输入,重建出图像观察 o_t。这里的 θ 表示这些模型的参数。
该团队指出,其中的解码器是可选的,因为解码器的训练目标与训练世界模型的其余部分无关。这样一来,就不必在训练和测试期间重建图像了;相比于将观察模型和解码器的训练结合在一起的做法,这还能降低计算成本。
DINO-WM 仅会建模环境中离线轨迹数据中可用的信息,这不同于近期的在线强化学习世界模型方法(还需要奖励和终止条件等与任务相关的信息)。
使用 DINO-WM 实现视觉规划
为了评估世界模型的质量,需要了解其在下游任务上的推理和规划能力。一种标准的评估指标是在测试时间使用世界模型执行轨迹优化并测量其性能。虽然规划方法本身相当标准,但它可以作为一种展现世界模型质量的手段。
为此,该团队使用 DINO-WM 执行了这样的操作:以当前观察 o_0 和目标观察 o_g(都是 RGB 图像)为输入,规划便是搜索能使智能体到达 o_g 的一个动作序列。为了实现这一点,该团队使用了模型预测性控制(MPC),即通过考虑未来动作的结果来促进规划。
为了优化每次迭代的动作序列,该团队还使用了一种随机优化算法:交叉熵方法(CEM)。其规划成本定义为当前隐藏状态与目标隐藏状态之间的均方误差(MSE),如下所示:
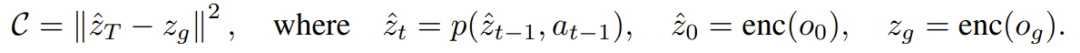
实验
该团队基于以下四个关键问题进行了实验:
- 能否使用预先收集的离线数据集有效地训练 DINO-WM?
- 训练完成后,DINO-WM 可以用于视觉规划吗?
- 世界模型的质量在多大程度上取决于预训练的视觉表征?
- DINO-WM 是否可以泛化到新的配置,例如不同的空间布局和物体排列方式?
为了解答这些问题,该团队在 5 个环境套件(Point Maze、Push-T、Wall、Rope Manipulation、Granular Manipulation)中训练和评估了 DINO-WM,并将其与多种在隐藏空间和原始像素空间中建模世界的世界模型进行了比较。
使用 DINO-WM 优化行为
该团队研究了 DINO-WM 是否可直接用于在隐藏空间中实现零样本规划。
如表 1 所示,在 Wall 和 PointMaze 等较简单的环境中,DINO-WM 与 DreamerV3 等最先进的世界模型相当。但是,在需要准确推断丰富的接触信息和物体动态才能完成任务的操纵环境中,DINO-WM 的表现明显优于之前的方法。
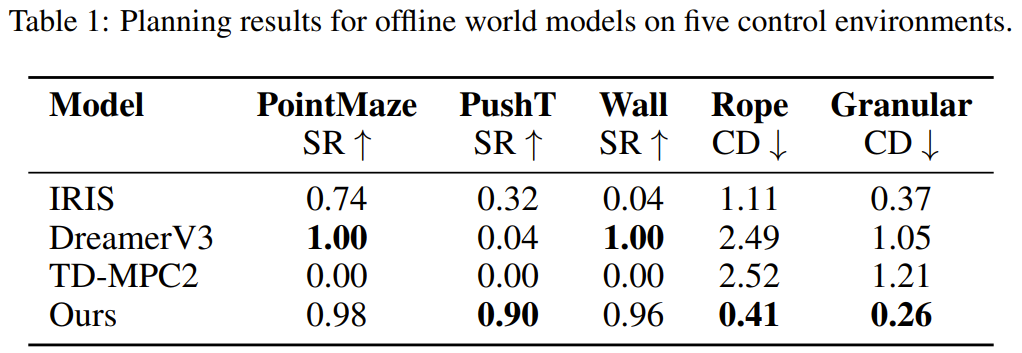
下面展示了一些可视化的规划结果:

预训练的视觉表征重要吗?
该团队使用不同的预训练通用编码器作为世界模型的观察模型,并评估了它们的下游规划性能。
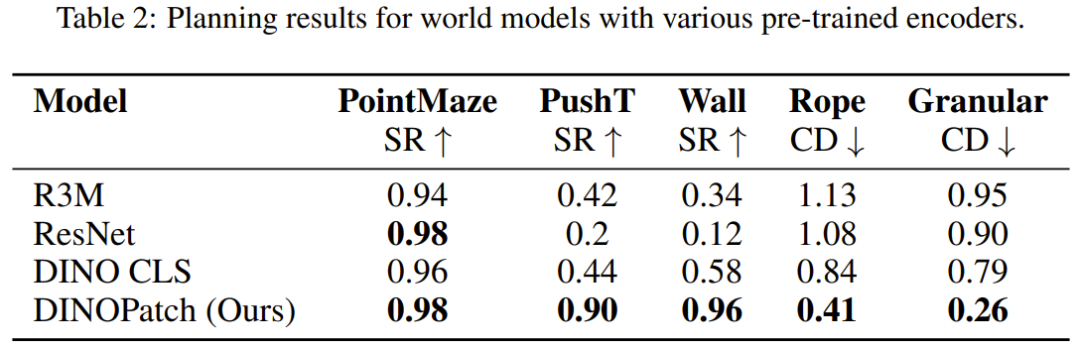
在涉及简单动态和控制的 PointMaze 任务中,该团队观察到具有不同观察编码器的世界模型都实现了近乎完美的成功率。然而,随着环境复杂性的增加(需要更精确的控制和空间理解),将观察结果编码为单个隐藏向量的世界模型的性能会显著下降。他们猜想基于图块的表征可以更好地捕获空间信息,而 R3M、ResNet 和 DINO CLS 等模型是将观察结果简化为单个全局特征向量,这样会丢失操作任务所需的关键空间细节。
泛化到全新的环境配置
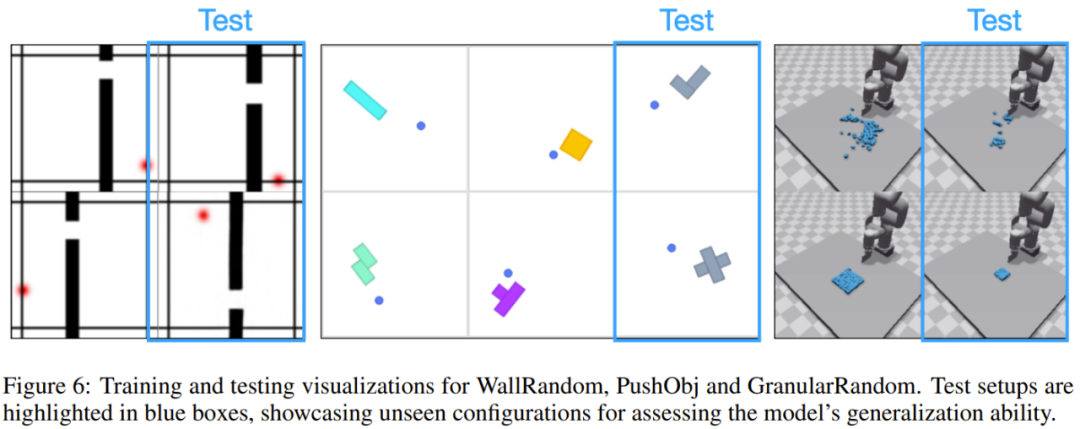
该团队也评估了新提出的模型对不同环境的泛化能力。为此,他们构建了三类环境:WallRandom、PushObj 和 GranularRandom。实验中,世界模型会被部署在从未见过的环境中去实现从未见过的任务。图 6 展示了一些示例。
结果见表 3。可以看到,DINO-WM 在 WallRandom 环境中的表现明显更好,这表明世界模型已经有效地学习了墙壁和门的一般概念,即使它们位于训练期间未曾见过的位置。相比之下,其他方法很难做到这一点。
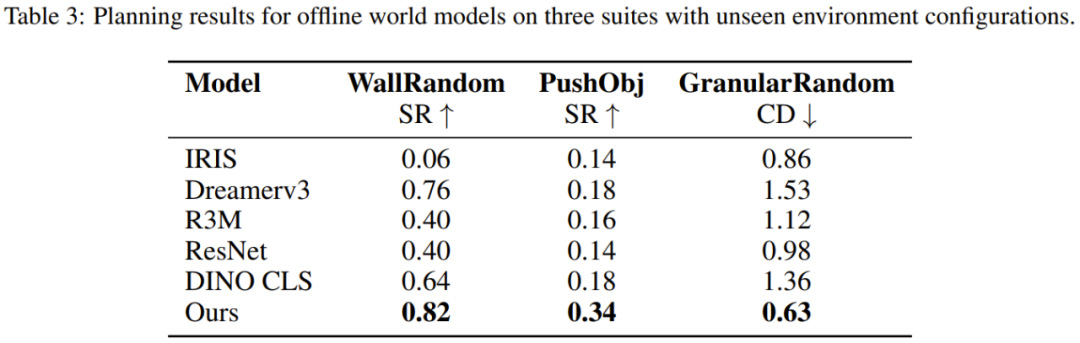
PushObj 任务对于所有方法来说都挺难,因为该模型仅针对四种物体形状进行了训练,这使其很难精确推断重心和惯性等物理参数。
在 GranularRandom 中,智能体遇到的粒子不到训练时出现的一半,导致图像出现在了训练实例的分布之外。尽管如此,DINO-WM 依然准确地编码了场景,并成功地将粒子聚集到与基线相比具有最小 Chamfer Distance(CD)的指定方形位置。这说明 DINO-WM 具有更好的场景理解能力。该团队猜想这是由于 DINO-WM 的观察模型会将场景编码为图块特征,使得粒子数量的方差仍然在每个图块的分布范围内。
与生成式视频模型的定性比较
鉴于生成式视频模型的突出地位,可以合理地假设它们可以很容易地用作世界模型。为了研究 DINO-WM 相对于此类视频生成模型的实用性,该团队将其与 AVDC(一个基于扩散的生成式模型)进行了比较。
如图 7 所示,可以看到,在基准上训练的扩散模型能得到看起来相当真实的未来图像,但它们在物理上并不合理,因为可以看到在单个预测时间步骤中就可能出现较大的变化,并且可能难以达到准确的目标状态。

DINO-WM 所代表的方法看起来颇有潜力,该团队表示:「DINO-WM 朝着填补任务无关型世界建模以及推理和控制之间的空白迈出了一步,为现实世界应用中的通用世界模型提供了光明的前景。」
参考链接:
https://www.ft.com/content/23fab126-f1d3-4add-a457-207a25730ad9
理论要掌握,实操不能落!以上关于《LeCun 的世界模型初步实现!基于预训练视觉特征,看一眼任务就能零样本规划》的详细介绍,大家都掌握了吧!如果想要继续提升自己的能力,那么就来关注golang学习网公众号吧!

-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
291 收藏
-
300 收藏
-
465 收藏
-
325 收藏
-
342 收藏
-
387 收藏
-
199 收藏
-
412 收藏
-
149 收藏
-
274 收藏
-
436 收藏
-
258 收藏
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习