阶跃星辰开源模型,StepAudioR1解析
时间:2025-12-07 15:12:42 174浏览 收藏
一分耕耘,一分收获!既然都打开这篇《StepAudio R1:阶跃星辰开源音频模型解析》,就坚持看下去,学下去吧!本文主要会给大家讲到等等知识点,如果大家对本文有好的建议或者看到有不足之处,非常欢迎大家积极提出!在后续文章我会继续更新科技周边相关的内容,希望对大家都有所帮助!
StepAudio R1是什么
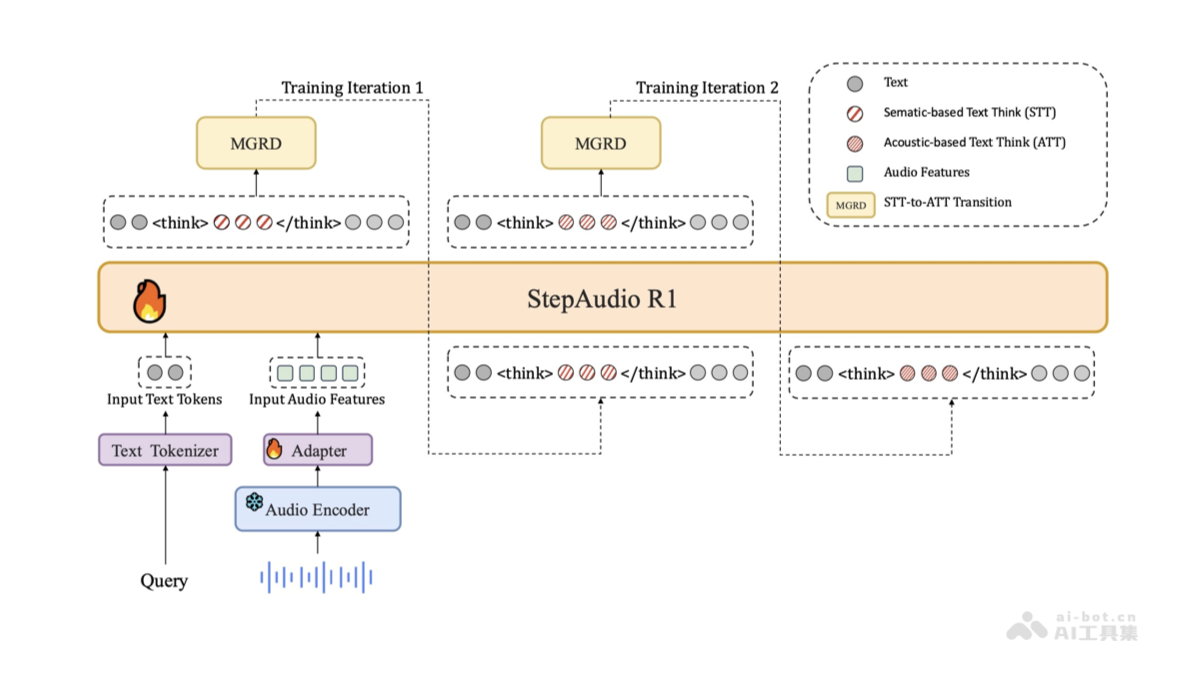
StepAudio R1 是由阶跃星辰研发并开源的全球首款原生音频推理模型,标志着音频智能处理领域的重大突破。该模型采用创新的模态锚定推理蒸馏(MGRD)框架,有效解决了传统音频模型在复杂逻辑推理任务中表现不佳的问题,真正实现了基于声学特征的深度推理能力。在多项权威基准测试中,StepAudio R1 的性能超越 Gemini 2.5 Pro,接近 Gemini 3 水平。其具备卓越的实时处理能力,推理评分高达 96%,首包响应延迟低至 0.92 秒。作为音频多模态推理的新范式,StepAudio R1 广泛适用于歌曲解读、影视内容分析、访谈信息提取等场景,为音频理解技术开辟了全新路径。
 StepAudio R1的主要功能
StepAudio R1的主要功能
- 复杂音频推理:能够完成高阶推理任务,如解析对话中的潜台词、识别情感变化、推断说话人性格与背景信息。
- 实时音频推理:具备超强实时性,首包延迟仅为 0.92 秒,适用于语音交互、实时会议记录等对响应速度要求高的场景。
- 多模态推理能力:虽然专注于音频输入,但融合了文本推理能力,可作为多模态系统中的核心组件,支持跨模态联合分析。
- 情感与社会智能推理:能从音频中识别情绪状态、人物关系和社会角色,例如通过语气判断心理压力水平或社交地位。
StepAudio R1的技术原理
- 模态锚定推理蒸馏(MGRD):这是 StepAudio R1 的核心技术机制——模态锚定推理蒸馏(Modality-Grounded Reasoning Distillation)。通过自蒸馏的迭代训练方式,将原本基于文本的抽象推理能力“锚定”到声学信号上,使模型能够在不依赖文字转录的情况下,直接从声音特征中构建推理链条,解决传统方法中推理过程与音频模态脱节的问题。
- 音频特征提取与对齐:模型首先精准提取语调、节奏、停顿、音强等关键声学特征,并利用 MGRD 框架将这些特征与具体的推理目标进行动态对齐,确保每一步推理都根植于原始音频数据。
- 多模态融合设计:尽管以音频为核心,StepAudio R1 仍保留强大的文本处理能力,支持音频与文本的协同理解,在需要结合字幕、脚本或多源信息的任务中表现出更强的适应性。
StepAudio R1的项目地址
- 项目官网:http://stepaudiollm.github.io/step-audio-r1/
- GitHub仓库:http://github.com/stepfun-ai/Step-Audio-R1
- HuggingFace模型库:http://huggingface.co/stepfun-ai/Step-Audio-R1
- arXiv技术论文:http://arxiv.org/pdf/2511.15848
StepAudio R1的应用场景
- 音乐赏析:深入解析歌曲的情感走向、旋律结构和风格特征,辅助用户更全面地欣赏音乐作品的艺术价值。
- 影视对话分析:自动分析影视剧中的对白内容,挖掘角色间的情感张力、性格冲突与人际关系,提升观剧体验。
- 访谈内容分析:提取访谈中的核心观点、情绪波动和逻辑脉络,生成结构化摘要,便于后续整理与传播。
- 学术演讲分析:帮助学者评估报告的表达逻辑、重点分布与听众反馈,优化学术沟通效果。
- 情感分析:基于语调起伏、语速变化及用词习惯,精准识别说话人的情绪状态,如兴奋、焦虑、沮丧或愤怒。
本篇关于《阶跃星辰开源模型,StepAudioR1解析》的介绍就到此结束啦,但是学无止境,想要了解学习更多关于科技周边的相关知识,请关注golang学习网公众号!

相关阅读
更多>
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
-
501 收藏
最新阅读
更多>
-
290 收藏
-
288 收藏
-
320 收藏
-
193 收藏
-
413 收藏
-
204 收藏
-
467 收藏
-
413 收藏
-
368 收藏
-
419 收藏
-
381 收藏
-
106 收藏
课程推荐
更多>
-

- 前端进阶之JavaScript设计模式
- 设计模式是开发人员在软件开发过程中面临一般问题时的解决方案,代表了最佳的实践。本课程的主打内容包括JS常见设计模式以及具体应用场景,打造一站式知识长龙服务,适合有JS基础的同学学习。
- 立即学习 543次学习
-

- GO语言核心编程课程
- 本课程采用真实案例,全面具体可落地,从理论到实践,一步一步将GO核心编程技术、编程思想、底层实现融会贯通,使学习者贴近时代脉搏,做IT互联网时代的弄潮儿。
- 立即学习 516次学习
-

- 简单聊聊mysql8与网络通信
- 如有问题加微信:Le-studyg;在课程中,我们将首先介绍MySQL8的新特性,包括性能优化、安全增强、新数据类型等,帮助学生快速熟悉MySQL8的最新功能。接着,我们将深入解析MySQL的网络通信机制,包括协议、连接管理、数据传输等,让
- 立即学习 500次学习
-

- JavaScript正则表达式基础与实战
- 在任何一门编程语言中,正则表达式,都是一项重要的知识,它提供了高效的字符串匹配与捕获机制,可以极大的简化程序设计。
- 立即学习 487次学习
-

- 从零制作响应式网站—Grid布局
- 本系列教程将展示从零制作一个假想的网络科技公司官网,分为导航,轮播,关于我们,成功案例,服务流程,团队介绍,数据部分,公司动态,底部信息等内容区块。网站整体采用CSSGrid布局,支持响应式,有流畅过渡和展现动画。
- 立即学习 485次学习