Go语言技术文章
-
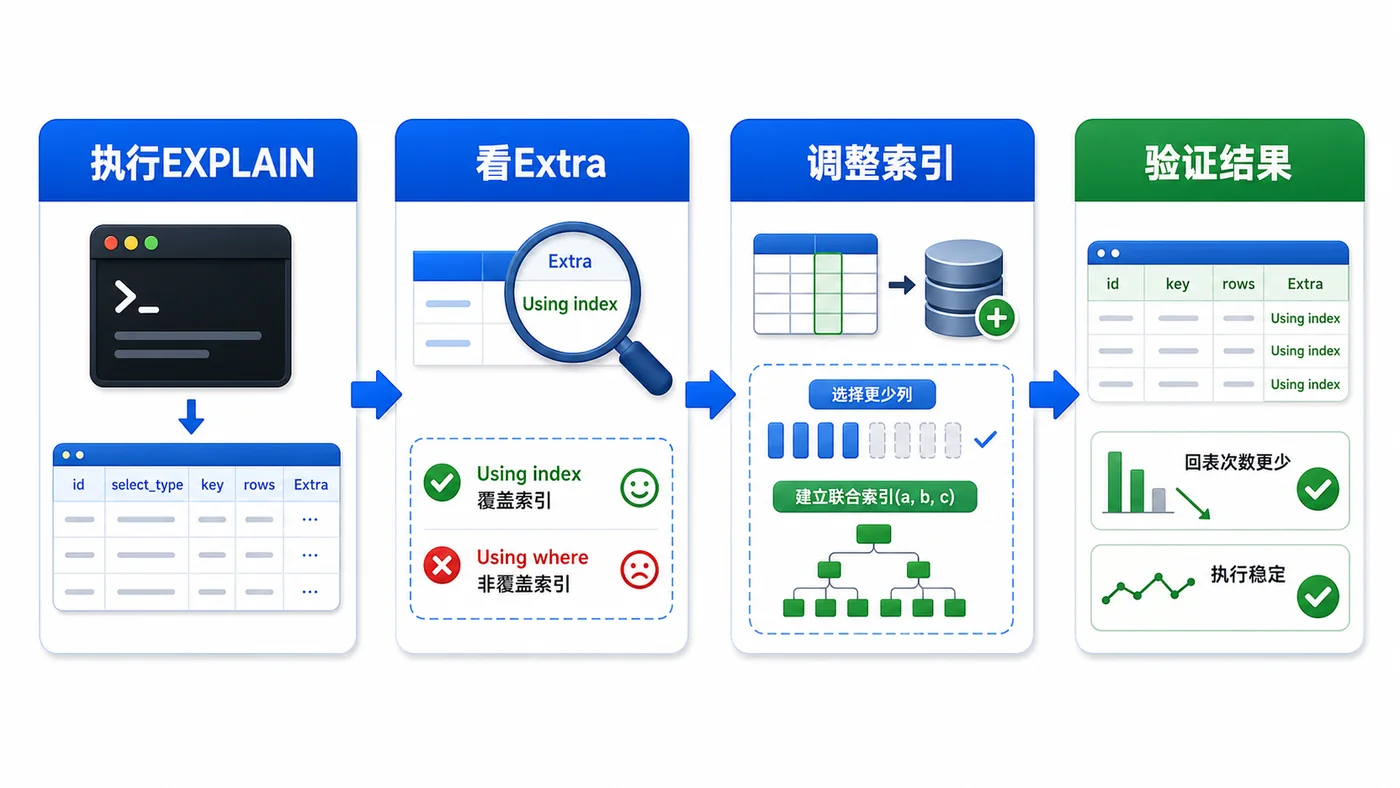 本文用订单列表查询场景,演示普通二级索引为什么需要回表,以及如何通过覆盖索引减少回表,并用 EXPLAIN 的 Extra 验证优化结果。381 收藏
本文用订单列表查询场景,演示普通二级索引为什么需要回表,以及如何通过覆盖索引减少回表,并用 EXPLAIN 的 Extra 验证优化结果。381 收藏 -
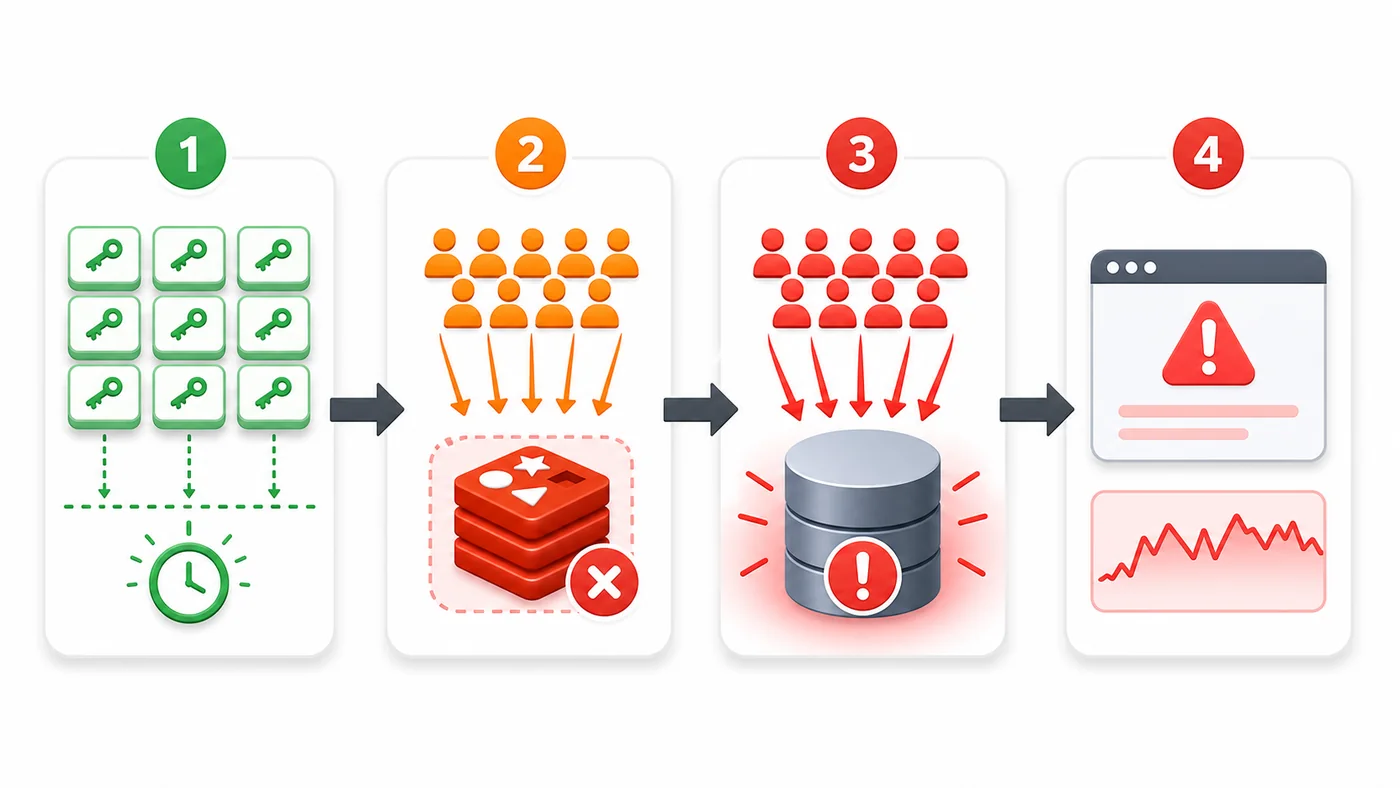 本文用商品详情缓存同时过期的场景,演示 Redis 缓存雪崩的形成过程,并给出 TTL 抖动、热点预热、互斥重建和降级保护的落地方案。139 收藏
本文用商品详情缓存同时过期的场景,演示 Redis 缓存雪崩的形成过程,并给出 TTL 抖动、热点预热、互斥重建和降级保护的落地方案。139 收藏 -
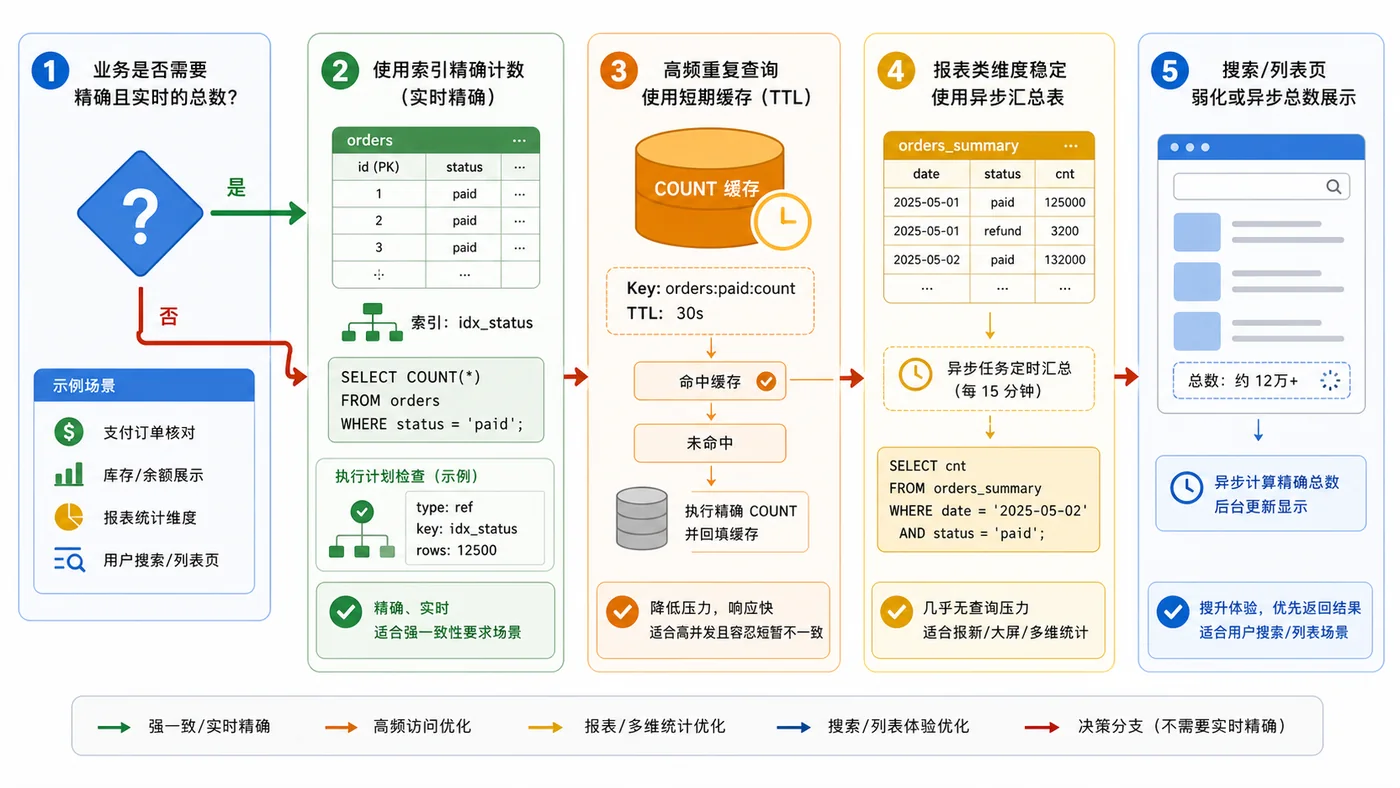 本文用后台订单列表总数统计场景,演示为什么大表每次 COUNT 会拖慢接口,并按精确总数、条件筛选、缓存和汇总表给出优化方案。336 收藏
本文用后台订单列表总数统计场景,演示为什么大表每次 COUNT 会拖慢接口,并按精确总数、条件筛选、缓存和汇总表给出优化方案。336 收藏 -
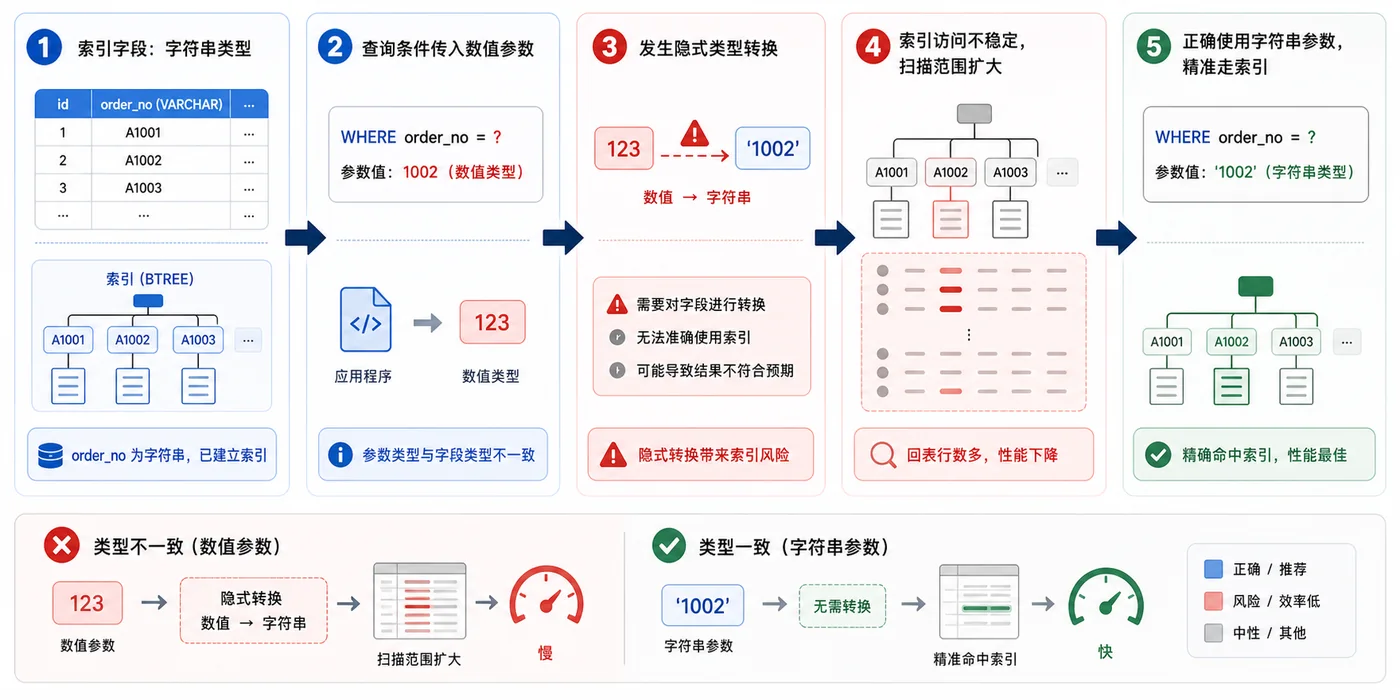 本文用订单号查询变慢的场景,演示 MySQL 隐式转换如何导致索引无法稳定命中,并给出字段类型统一、参数绑定和上线检查方案。152 收藏
本文用订单号查询变慢的场景,演示 MySQL 隐式转换如何导致索引无法稳定命中,并给出字段类型统一、参数绑定和上线检查方案。152 收藏 -
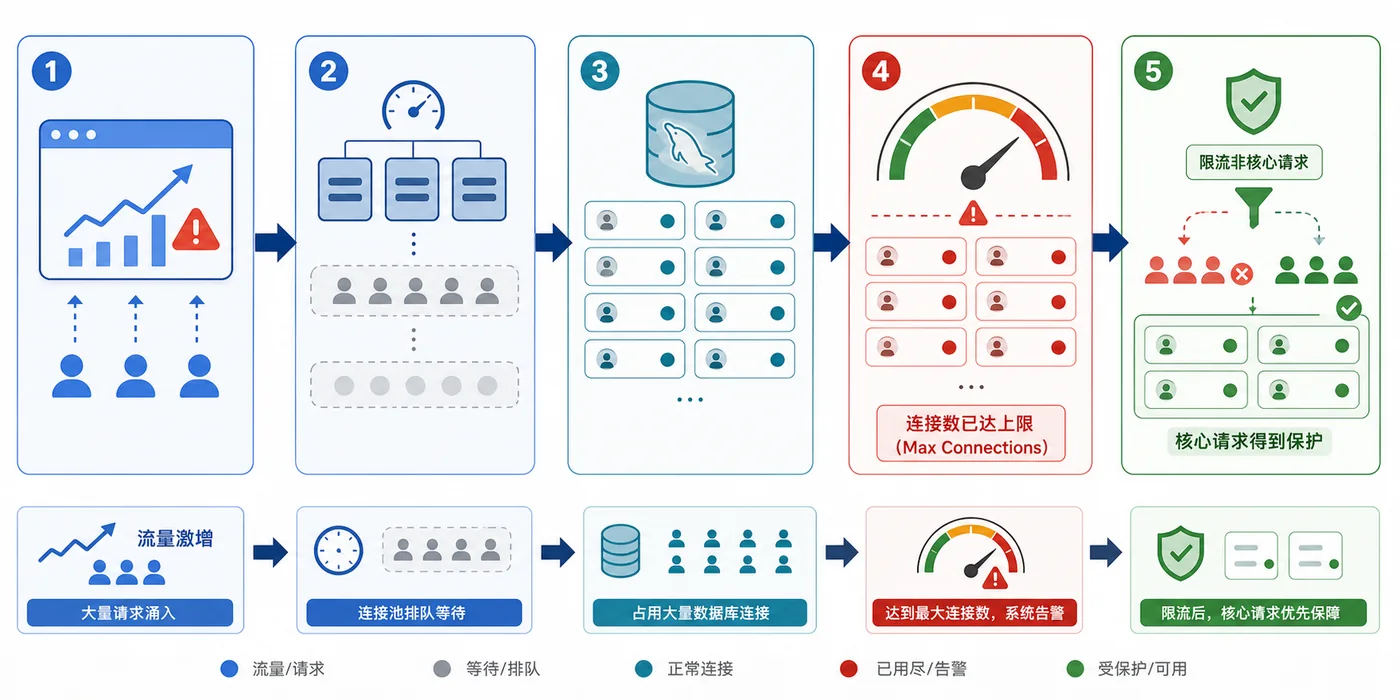 本文用一次 MySQL 连接数告警场景,演示如何区分连接池突增、慢 SQL 堵塞和长事务占用,并给出排查命令和上线兜底建议。404 收藏
本文用一次 MySQL 连接数告警场景,演示如何区分连接池突增、慢 SQL 堵塞和长事务占用,并给出排查命令和上线兜底建议。404 收藏 -
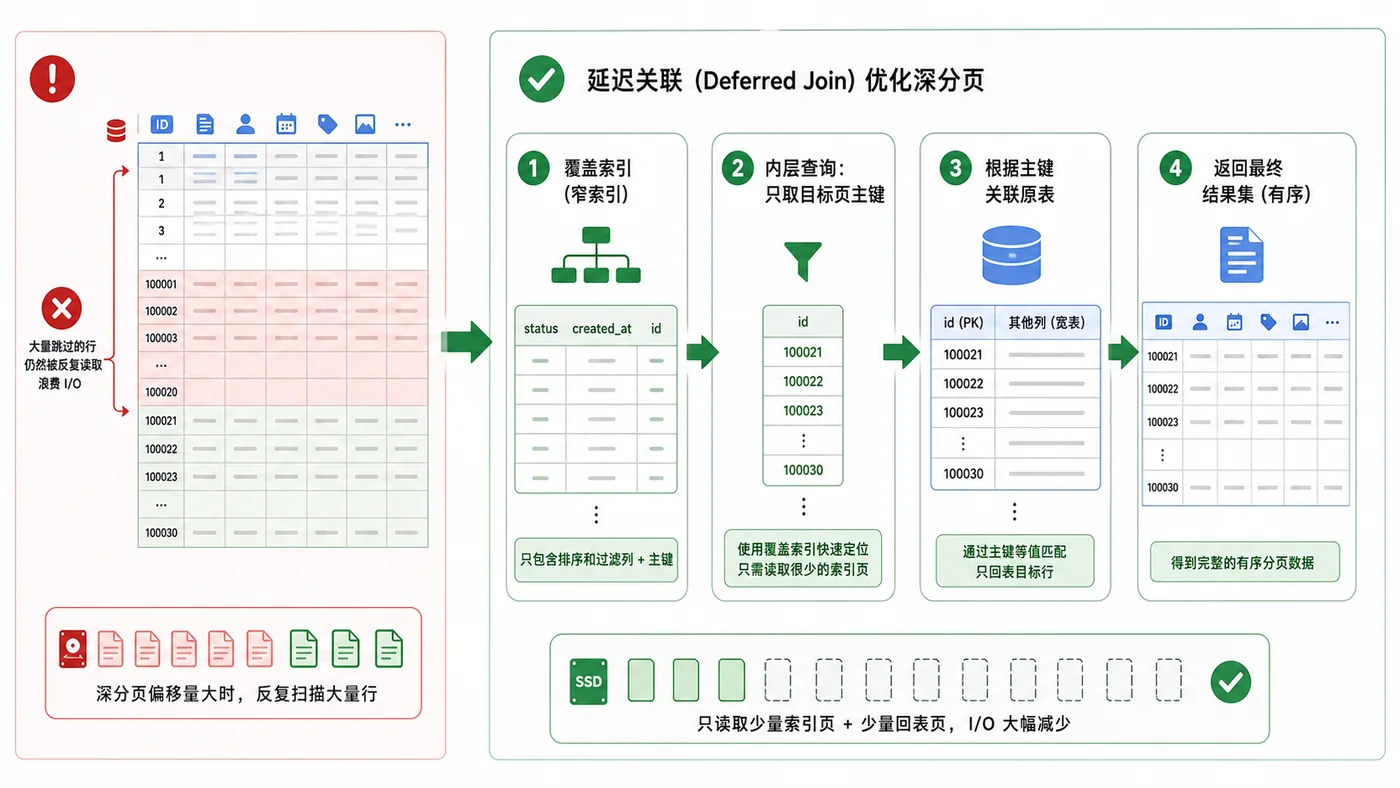 本文用订单列表深分页场景,演示为什么 LIMIT 大偏移会变慢,并通过覆盖索引、延迟关联和游标式分页减少无效扫描。339 收藏
本文用订单列表深分页场景,演示为什么 LIMIT 大偏移会变慢,并通过覆盖索引、延迟关联和游标式分页减少无效扫描。339 收藏 -
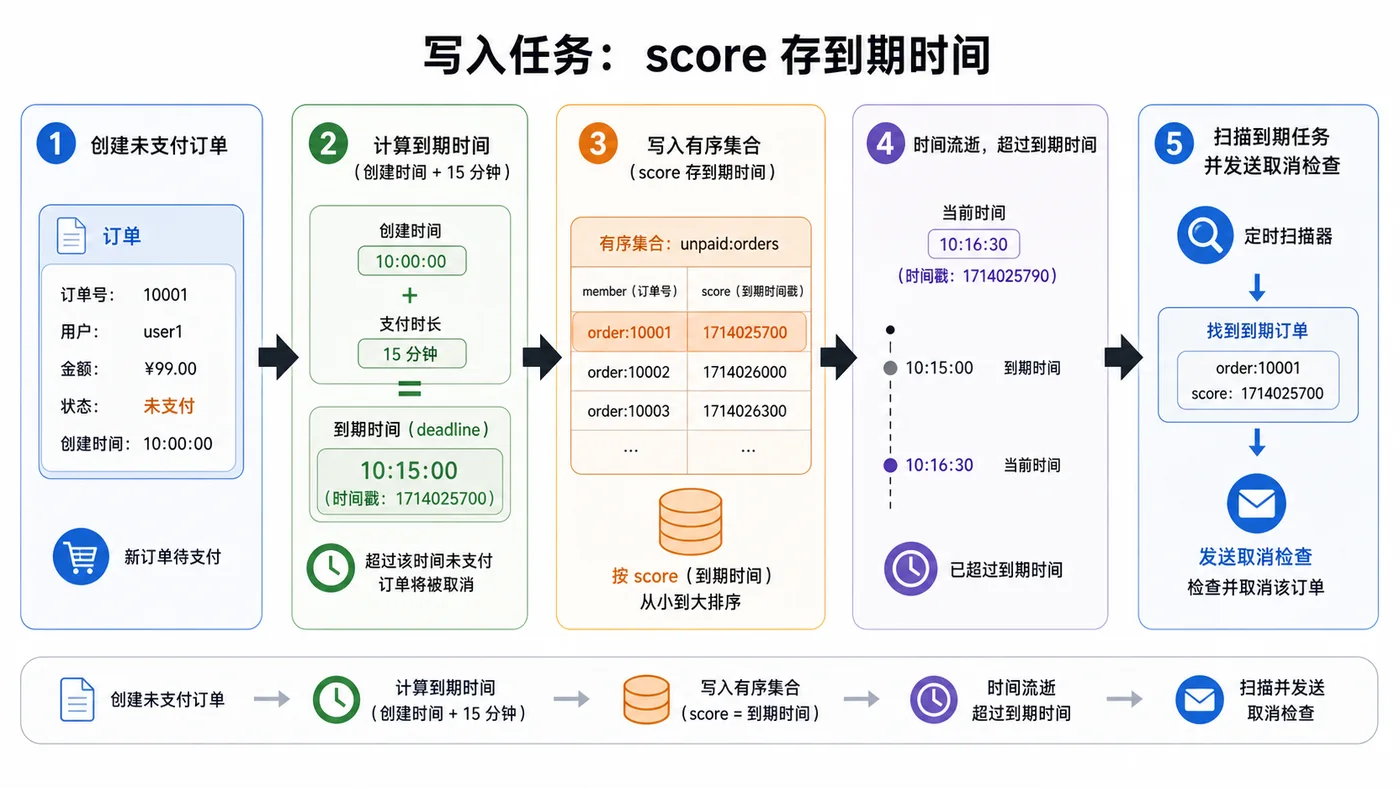 本文用 Redis ZSET 设计一个轻量延迟队列,讲清楚如何写入订单超时任务、按时间扫描到期任务、抢占删除、防重复处理以及失败重试。116 收藏
本文用 Redis ZSET 设计一个轻量延迟队列,讲清楚如何写入订单超时任务、按时间扫描到期任务、抢占删除、防重复处理以及失败重试。116 收藏 -
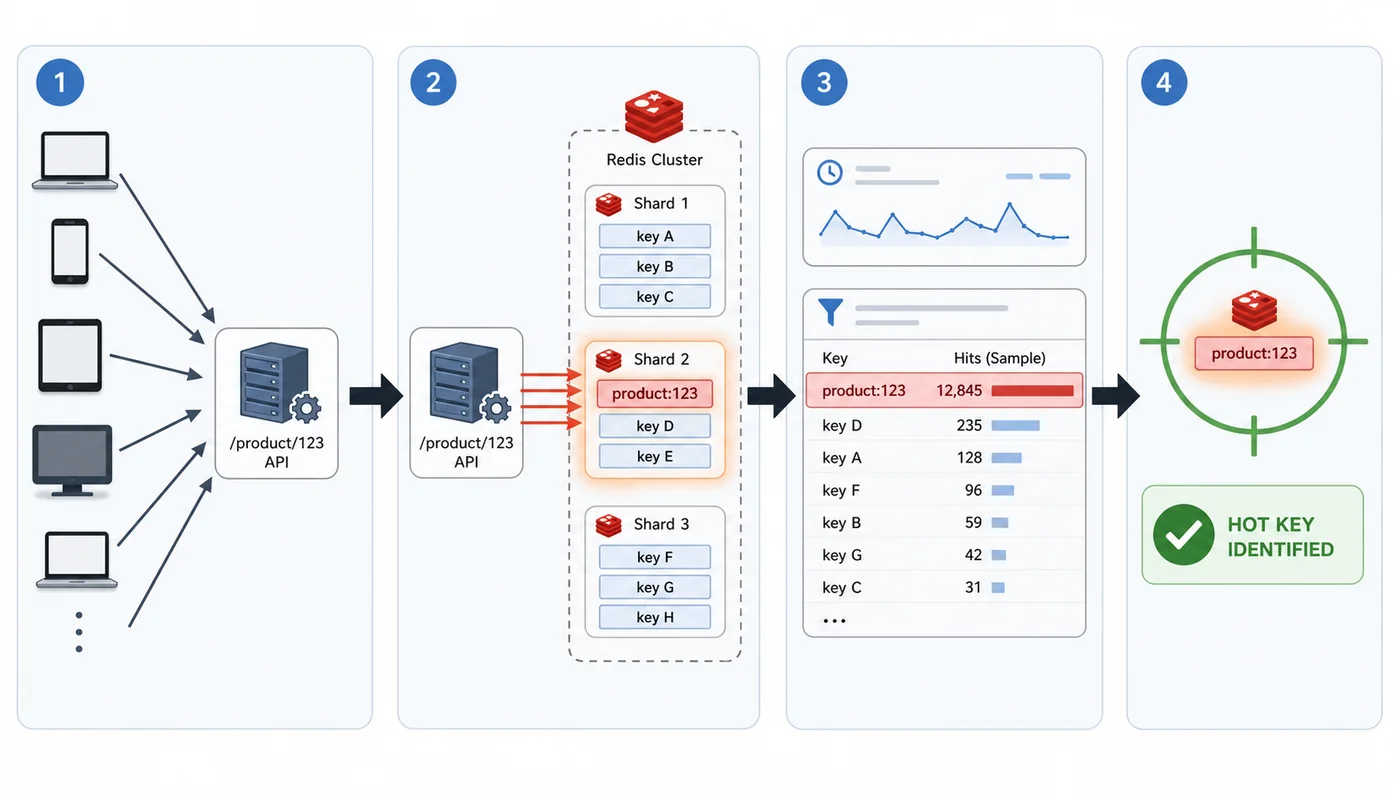 本文从一次商品详情接口抖动出发,演示如何发现 Redis 热 Key、判断访问倾斜,并通过过期时间抖动、本地短缓存、singleflight 合并加载和拆分 Key 降低热点冲击。111 收藏
本文从一次商品详情接口抖动出发,演示如何发现 Redis 热 Key、判断访问倾斜,并通过过期时间抖动、本地短缓存、singleflight 合并加载和拆分 Key 降低热点冲击。111 收藏 -
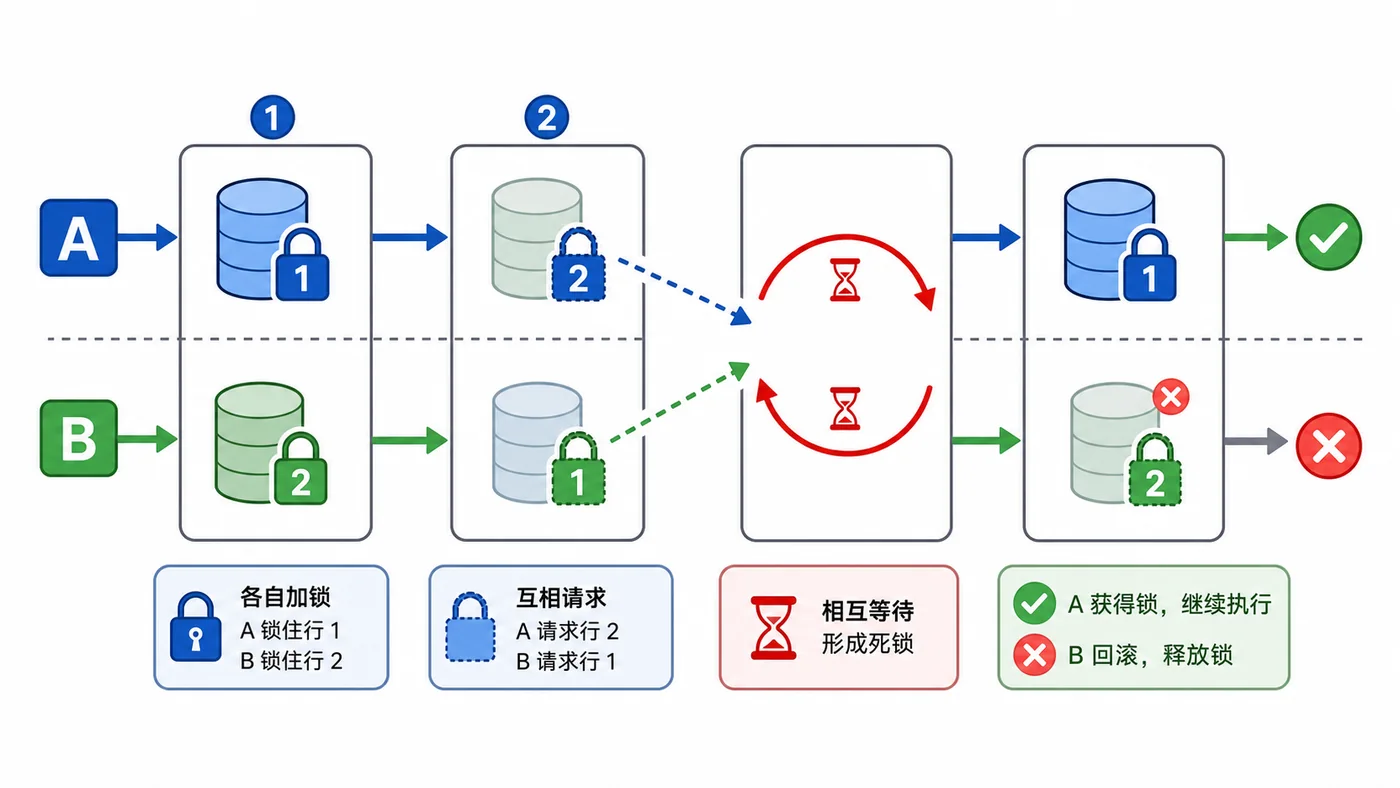 通过转账场景复现 MySQL InnoDB 死锁,演示如何查看死锁信息、理解反向加锁原因,并用固定加锁顺序、缩短事务和重试机制降低问题概率。429 收藏
通过转账场景复现 MySQL InnoDB 死锁,演示如何查看死锁信息、理解反向加锁原因,并用固定加锁顺序、缩短事务和重试机制降低问题概率。429 收藏 -
 通过订单列表慢查询案例,演示如何阅读 EXPLAIN 的 type、key、rows、Extra 字段,并设计联合索引优化 WHERE、ORDER BY 和 LIMIT 分页。159 收藏
通过订单列表慢查询案例,演示如何阅读 EXPLAIN 的 type、key、rows、Extra 字段,并设计联合索引优化 WHERE、ORDER BY 和 LIMIT 分页。159 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · 执行计划 · MySQL教程 · 慢查询治理 · 数据库运维 · mysql GROUP BY优化 TempTable 内部临时表 Created_tmp_disk_tables
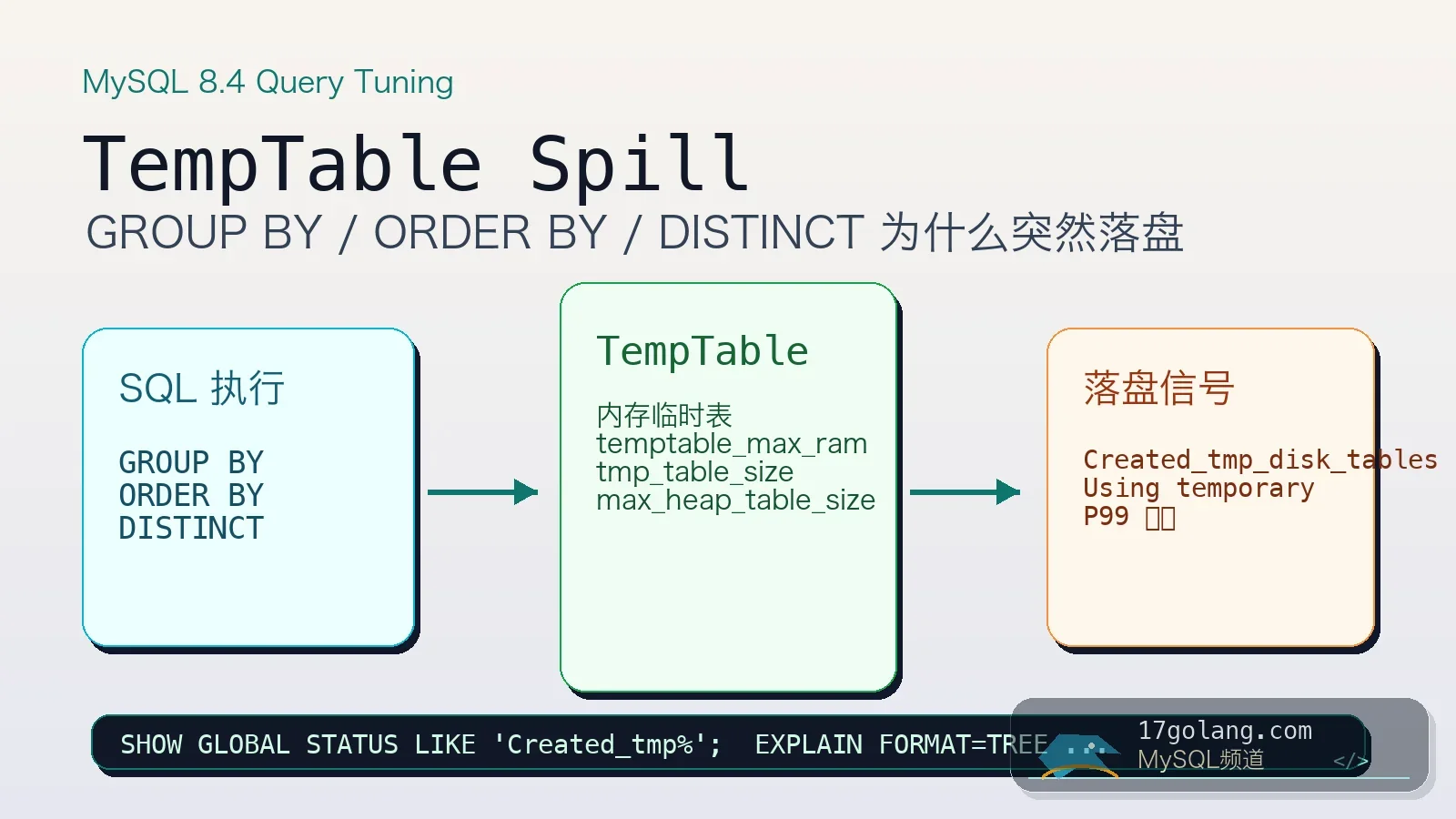 从 MySQL 8.4 内部临时表和 TempTable 入手,讲清 GROUP BY、ORDER BY、DISTINCT 落盘诊断、SQL 改写、索引策略和参数兜底。267 收藏
从 MySQL 8.4 内部临时表和 TempTable 入手,讲清 GROUP BY、ORDER BY、DISTINCT 落盘诊断、SQL 改写、索引策略和参数兜底。267 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · InnoDB · MySQL教程 · 数据库运维 · 高并发写入 · mysql innodb 批量写入 Change Buffer innodb_change_buffering
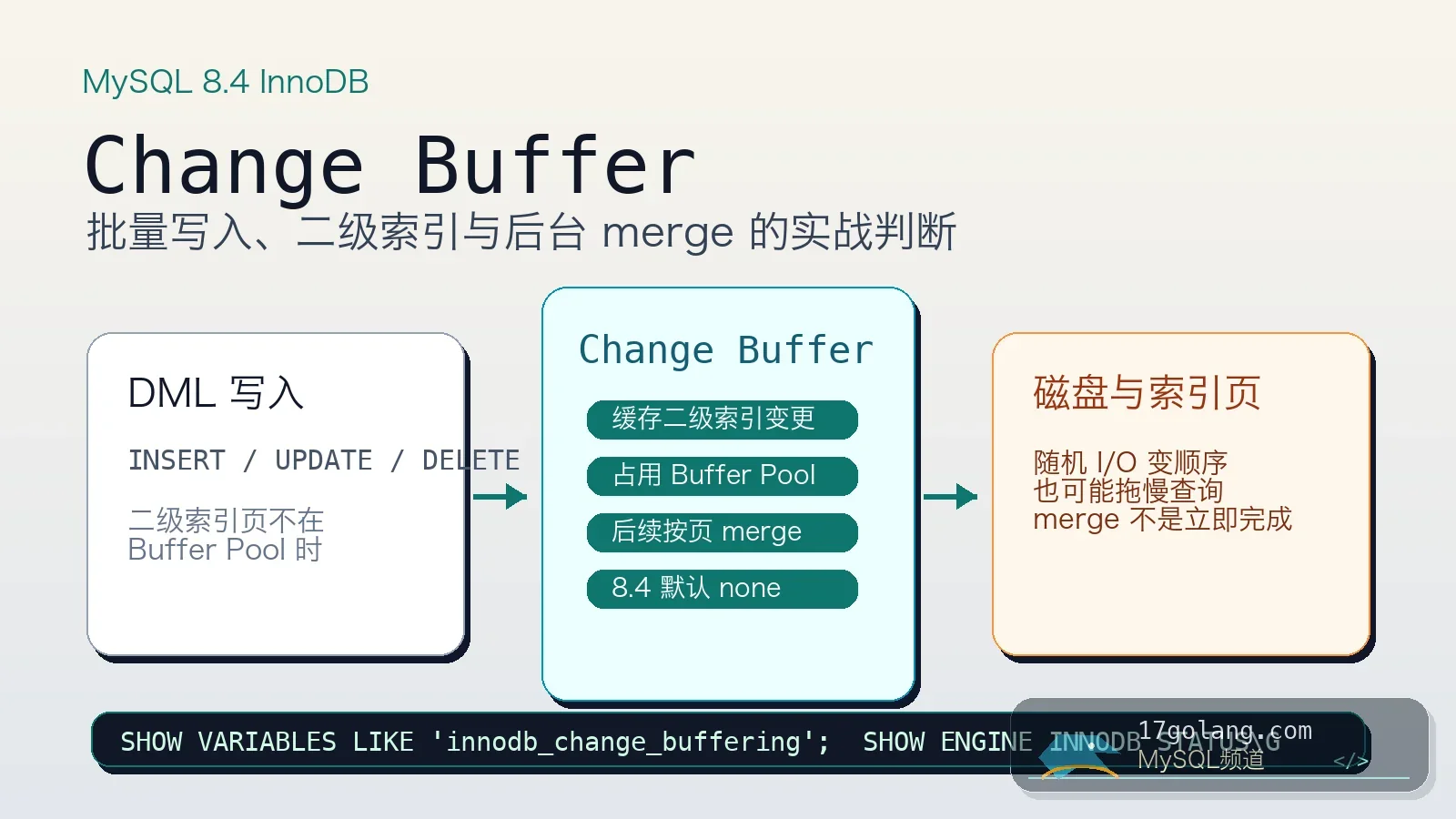 从 MySQL 8.4 InnoDB Change Buffer 默认值变化入手,讲清批量写入、二级索引随机 I/O、merge 观察和上线回滚。270 收藏
从 MySQL 8.4 InnoDB Change Buffer 默认值变化入手,讲清批量写入、二级索引随机 I/O、merge 观察和上线回滚。270 收藏 -
数据库 · MySQL | 1个月前 | 性能优化 · 高并发 · InnoDB · MySQL教程 · 数据库运维 · mysql innodb AUTO_INCREMENT 高并发写入 innodb_autoinc_lock_mode
 从 MySQL 8.4 AUTO_INCREMENT 锁模式入手,讲清高并发 INSERT、批量导入、复制格式和上线回滚检查。254 收藏
从 MySQL 8.4 AUTO_INCREMENT 锁模式入手,讲清高并发 INSERT、批量导入、复制格式和上线回滚检查。254 收藏 -
数据库 · MySQL | 1个月前 | 连接池 · 高并发 · 故障排查 · MySQL教程 · 数据库运维 · mysql 高并发 连接池 max_connections Too many connections
 从 MySQL Too many connections 事故入手,讲清 max_connections、Threads_connected、Threads_running、连接池容量预算和上线检查。491 收藏
从 MySQL Too many connections 事故入手,讲清 max_connections、Threads_connected、Threads_running、连接池容量预算和上线检查。491 收藏 -
 从手机号后四位和日期函数查询变慢切入,讲清 MySQL 8.x 函数索引、生成列、表达式匹配、EXPLAIN 验证、DDL 风险和上线检查。381 收藏
从手机号后四位和日期函数查询变慢切入,讲清 MySQL 8.x 函数索引、生成列、表达式匹配、EXPLAIN 验证、DDL 风险和上线检查。381 收藏