-

Jelly
Jelly是一款基于Netty4.x开发的TCP长连接即时通讯服务器端程序;并且提供了Java客户端API。
Github项目地址:Jelly
功能包括
账户:登录、注册、登出
好友:添加、删除、好友在线状态
消息:
-

show databases;
show columns from tableName; // 同于 describe tableName;
案例:
+------------+-----------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------
-

.NET Core容器化@Docker.NET Core容器化之多容器应用部署@Docker-Compose.NET Core+MySql+Nginx 容器化部署GitHub-Demo:Docker.NetCore.MySql
1. 引言
上两节我们通过简单的demo学习了docker的基本操作。这一节我们来一
-

mysql 数据库开发常见问题及优化
这篇文章从库表设计,慢 SQL 问题和误操作、程序 bug 时怎么办这三个问题展开。
一个小时学会 MySQL 数据库
看到了一篇适合新手的 MySQL 入门教程,希望对想学 My
-

最近项目开发遇到sql比较复杂,多表连接嵌套查询,做了很多优化。分享一下我调优的经验:
1、嵌套查询尽量减少内层查询的结果数
嵌套查询能在内层做统计或者聚合多尽量就在内层做聚合,
-

我们无法在一篇博文里解释 JavaScript 的所有细节。如果你正或多或少地涉及了 web 应用程序开发,那么,我们的 Java 工具和技术范围报告揭示了,大多数(71%)Java 开发者被归到了这一类,只是
-

准备工作
1、安装mysql,版本要和RDS实例的版本一致; 2、安装mysql备份恢复工具percona-xtrabackup,下载地址为https://www.percona.com/downl...3、rds上创建一个普通账户,无需分配任何库的权限,用于从库
-

解决过程
网上有很多解决办法,有的说重启navicat就好了,具体他也不知道为什么,我重启了也没有解决问题。有的说打开的的表格数量达到了限制,关点表格就好了,我的就开了两个表格,数
-

数据库综合实验重做
因为期末的时候做数据库综合实验太匆忙,很多地方都是能用就好,做完之后突然想到可以改进的方法,所以现在寒假来重做一下
题目如下:
设计某高校学生选课管理系统
-

存储过程简单来说,就是为以后的使用而保存的一条或多条MySQL语句的集合。可将其视为批件,虽然它们的作用不仅限于批处理。在我看来, 存储过程就是有业务逻辑和流程的集合, 可以在存
-

背景插入timestamp类型与datetime类型数据比预计结果早14小时原因如果说相差8小时不够让人惊讶,那相差13小时可能会让很多人摸不着头脑。出现这个问题的原因是JDBC与MySQL对 “CST” 时区协商不一
-

细枝末节字段名 字段类型 约束类型表级约束[CONSTRAINT 约束名] 约束类型(字段名)示例添加列级约束CREATE TABLE stuinfo(
/* 主键约束 */
id int PRIMARY KEY,
/* 非空约束 */
name varchar(20) NOT NULL,
-

HashMap 是一线资深 java工程师必须要精通的集合容器,它的重要性几乎等同于Volatile在并发编程的重要性(可见性与有序性)。本篇通过图文源码详解,深度剖析 HashMap 的重要内核知识,易看易学
-

数据库索引的数据结构
在数据库中的索引方法中,有TREE和HASH两种方法,HASH是经常使用的,本文中主要介绍TREE的数据结构。B+Tree 的高度一般是2-4层,也就是说查找一条数据记录,最多使用
-
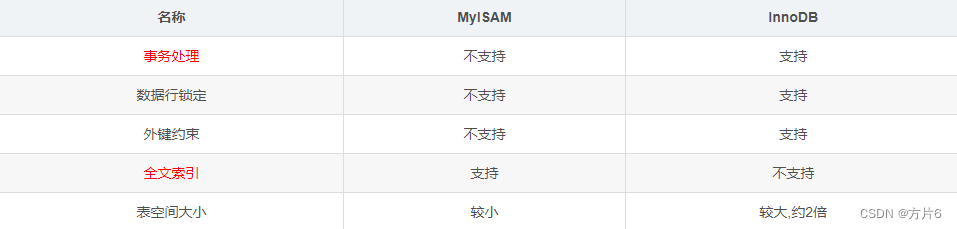
一、查看表和查看表的定义
SHOW TABLE 表名
DESC 表名;
DESCRIBE 表名
二、删除表
DROP TABLE [IF EXISTS ] 表名;
如果表USER存在,删除表USER
DROP TABLE IF EXISTS USER;
三、创建表
CREATE TABLE [ IF NOT EXISTS ] `表