-

Redis实现分布式任务调度的方法与应用实例随着技术的发展,分布式系统在互联网应用和大数据领域得到了广泛的应用。在分布式系统中,任务调度是一个重要的组成部分。分布式任务调度用于协调各节点之间的任务执行,使得任务能够在不同的节点上通过协同完成。采用Redis实现分布式任务调度是一种非常流行的方法。本文将介绍Redis实现分布式任务调度的方法以及应用实例。一、R
-
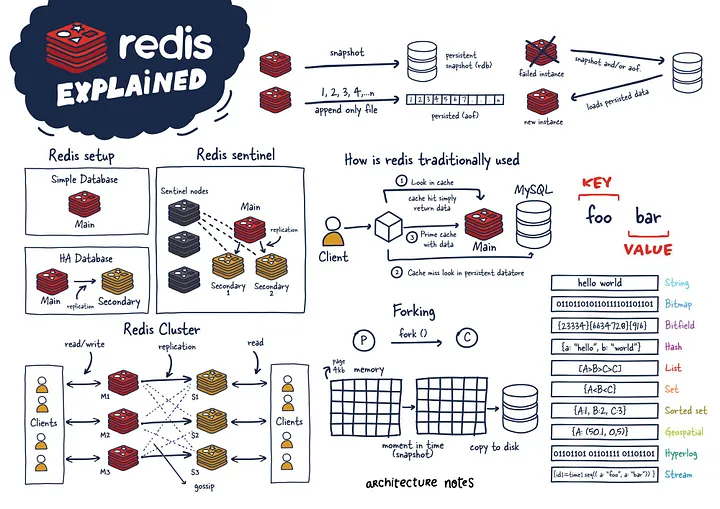
在上一篇文章中,介绍了《Redis的内存模型》,从这篇文章开始,将依次介绍 Redis 高可用相关的知识——持久化、复制(及读写分离)、哨兵、以及集群。本文将先说明上述几种技术分
-
最近,又重新学习了下Redis,Redis不仅能快还能慢,简直利器,今天就为大家介绍一下Redis延迟队列和分布式延迟队列的简单实现。
在我们的工作中,很多地
-

集成方式
使用Jedis
Jedis是Redis官方推荐的面向Java的操作Redis的客户端,是对服务端直连后进行操作。如果直接使用Jedis进行连接,多线程环境下是非线程安全的,正式生产环境一般使用连接池进
-

执行replicaofnoone再replicaof不会清空从库数据,仅切换复制源;真正全量同步需确保无运行复制流且master_replid/offset不匹配,必要时手动清空或重启从库。
-

用SETBIT和GETBIT做存在性判断最直接:SETBIT设定位为1,GETBIT查该位是否为1,O(1)时间、极省空间;不可用BITCOUNT替代,不支持三态,需确保ID到偏移量映射一致。
-

在Redis多租户环境中,通过数据库实例隔离、数据库隔离、键名前缀实现数据隔离;使用ACL进行权限控制;通过内存限制和连接池管理资源分配;通过加密传输、认证和防火墙提升安全性。
-

通过redis-cli、RedisInsight、Prometheus和Grafana等工具,以及关注内存使用率、连接数、集群节点状态、数据一致性和性能指标,可以有效监控Redis集群的健康状态。
-
Apache Flink和 Redis 是两个强大的工具,可以一起使用来构建可以处理大量数据的实时数据处理管道。Flink 为处理数据流提供了一个高度可扩展和容错的平台,而 Redis 提供了一个高性能的内存数据
-

Redis集群不自动随机化过期时间,需业务层实现;限流须在应用层或网关层统一控制;热点key需加扰动后缀分散分片;三者叠加(集群+随机过期+限流)且随机范围≥±5%才有效防雪崩。
-

Redis集群中Lua脚本不会触发传统死锁,但会因单线程执行而阻塞整个节点;无限循环脚本导致该节点所有命令超时,需通过CLIENTLIST、INFOcommandstats及CLUSTERNODES识别异常,并依赖lua-time-limit、计数器循环、客户端超时与限流等机制防控。
-

不能。RedisList无自动回绕机制,需配合LTRIM控制长度实现伪循环队列;RPOPLPUSH不限长也不丢弃数据;原子性操作须用Lua脚本封装;Stream的MAXLEN更贴近循环语义但不支持随机访问。
-

Redis列表在消息队列中的应用可以通过以下优化措施提升性能和可靠性:1.启用持久化机制(AOF或RDB)确保消息不丢失;2.使用BRPOP命令提高消费者的响应性和降低系统负载;3.通过多个列表模拟优先级队列处理不同优先级的消息;4.设置键的过期时间或在消息中加入时间戳管理消息的生命周期;5.利用批量操作减少网络开销,提升系统性能。
-

通过redis-cli、RedisInsight、Prometheus和Grafana等工具,以及关注内存使用率、连接数、集群节点状态、数据一致性和性能指标,可以有效监控Redis集群的健康状态。
-

Redis和HBase可以协同工作,发挥各自优势。1)使用Redis处理实时数据和缓存,如用户行为数据。2)利用HBase存储和分析历史数据,如用户购买习惯。通过这种方式,可以实现快速访问和长久存储的平衡。