-

需要关注Redis的版本更新,因为它能带来性能提升、安全补丁和新功能。检查Redis版本是否需要升级的步骤包括:1.使用命令“redis-cli--version”查看当前版本;2.与Redis官方版本对比;3.评估新功能、性能提升、安全补丁和兼容性;4.遵循备份数据、测试环境、逐步升级和监控日志的最佳实践。
-

Redis作为一个开源的基于内存的键值存储系统,正被越来越多的企业使用于其分布式系统中,因为其高性能、可靠性和灵活性。但是,在一些情况下,Redis作为分布式系统中的瓶颈,可能会影响系统的整体性能。本文将探讨Redis在分布式系统中的瓶颈原因及其解决方法。Redis中的单线程模型Redis采用的是单线程模型,这意味着一个Redis实例只能够处理一条命令,即使
-

在分布式系统中,消息队列(MessageQueues)是一种常见的机制,用于协调各个组件之间的通信。消息队列可以通过异步消息传递来解耦分布式系统中各个组件之间的相互依赖关系。Redis是一种流行的开源缓存系统,同时也可以作为消息队列使用。在本文中,我们将介绍Redis在消息队列中的应用实例。一、Redis作为消息队列的基本介绍Redis支持发布/订阅(P
-

HMSET自Redis6.2起被弃用,应统一使用HSET:支持批量写入、返回实际修改数、空值字段会被删除;需注意原子性(单次多字段更新)、客户端传参规范(推荐mapping=)及代理字段数限制。
-

HSET查单个字段更快,SET写整条数据更省网络;字段少且固定用HSET,动态多变或需原子替换用SET;LIST队列易丢消息,推荐STREAM;ZSET排行榜慎用浮点score;大SET内存开销大,慎用SMEMBERS。
-

SETNX不能单独用作分布式锁,因其无法原子性地设置值和过期时间,易导致死锁;必须用SETkeyvalueNXEXseconds原子命令,并配合唯一value和Lua脚本校验解锁。
-

安全更新Redis配置参数的步骤包括:1)备份Redis数据库和配置文件;2)使用CONFIGSET命令动态更新配置参数;3)编辑配置文件并重启服务更新不支持动态修改的参数;4)更新安全相关参数如requirepass和bind;5)合理配置参数并考虑版本兼容性;6)进行充分的测试和验证,确保系统运行正常。
-

要处理Redis慢查询日志,首先配置Redis服务器记录慢查询,然后分析日志并优化查询。1.设置slowlog-log-slower-than和slowlog-max-len参数。2.使用SLOWLOGGET命令查看慢查询记录。3.优化查询命令,如用SCAN替代KEYS。4.重新设计数据结构,如用有序集合替代普通集合。5.使用Pipeline批量执行命令。持续监控和分析慢查询日志以优化Redis性能。
-

有效解决Redis集群脑裂问题的方法包括:1)网络配置优化,确保连接稳定性;2)节点监控和故障检测,使用工具实时监控;3)故障转移机制,设置高阈值避免多主节点;4)数据一致性保证,使用复制功能同步数据;5)人工干预和恢复,必要时手动处理。
-

在Redis缓存清除后确保数据一致性的方法包括:1.缓存与数据库的双写一致性,通过同时更新数据库和Redis来保证实时性,但需注意写放大和一致性问题;2.缓存失效后重建,适用于读多写少的场景,需防范缓存击穿和数据一致性延迟;3.延迟双删策略,适用于高一致性需求,通过先删除缓存、更新数据库、再延迟删除缓存来解决短暂不一致问题,但增加了系统复杂度。
-

Redis集群数据分片的原理是通过哈希槽实现数据的分布式存储。1)Redis集群将键空间划分为16384个哈希槽,每个键通过CRC16校验和后对16384取模,决定所属哈希槽。2)每个Redis节点负责一部分哈希槽,实现数据分片。3)这种设计支持动态调整集群规模,通过迁移部分哈希槽添加或移除节点。
-

Redis的默认配置不安全,应配置防火墙规则以限制连接源。1)使用iptables规则允许特定子网访问Redis端口并拒绝其他连接。2)基于应用程序服务器位置限制访问源。3)使用TLS/SSL加密通信。4)定期审计和更新规则。5)监控和分析日志。6)考虑使用RedisSentinel。
-

Redis中的哈希类型适用于存储复杂数据结构,适合用户信息和购物车系统。1)存储用户信息:使用hset和hget命令管理用户数据。2)购物车系统:利用哈希存储商品,结合Set类型可优化大数据量。3)性能优化:避免频繁操作,使用批量命令和过期时间管理数据。
-

Redis启动后无法访问的原因主要包括配置文件问题、网络问题、防火墙设置和内存不足。解决方案如下:1.调整配置文件,确保绑定地址和端口正确;2.修复网络连接,确保Redis服务器和客户端连接正常;3.调整防火墙规则,允许Redis端口访问;4.增加内存或调整Redis配置,确保内存充足。
-
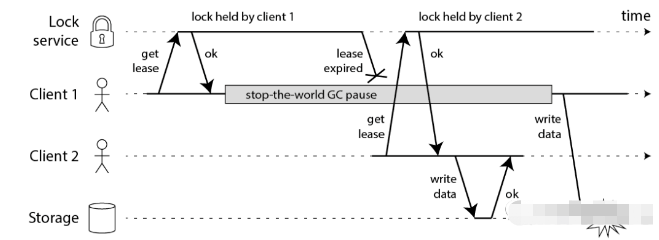
一、概述在这个技术不断更新迭代的情况下,分布式这个概念,在企业中的权重越来越高!谈及分布式时,不可避免一定会提到分布式锁,现阶段分布式锁的实现方式主流的有三种实现方式,Zookeeper、DB、Redis,我们本篇文章以Redis为例!从我们的角度来看,这三个属性是有效使用分布式锁所需的最低保证。安全特性:互斥。在任何给定时刻,只有一个客户端可以持有锁。活力属性:无死锁。最终,即使锁定资源的客户端崩溃或分区,也始终可以获得锁。活动性:容错能力。只要大多数Redis节点都处于运行状态,客户端就可以获取和释放