-
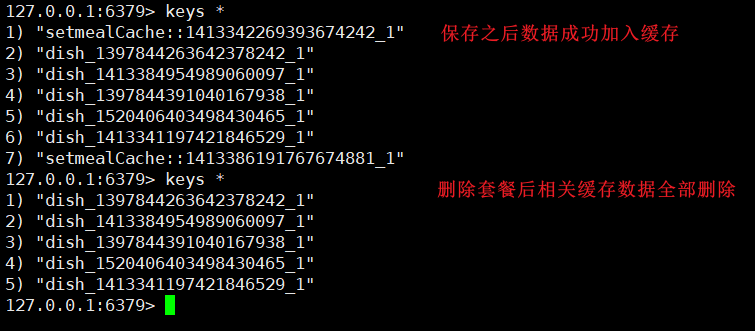
1、简介SpringCache是一个框架,实现了基于注解的缓存功能,只需要简单地加一个注解,就能实现缓存功能。SpringCache提供了一层抽象,底层可以切换不同的cache实现。具体就是通过CacheManager接口来统一不同的缓存技术。CacheManager是Spring提供的各种缓存技术抽象接口,这是默认的缓存技术,是缓存在Map中的,这也说明当服务挂掉的时候,缓存的数据就没了。针对不同的缓存技术需要实现不同的CacheManagerCacheManager描述EhCacheCacheMana
-

通过redis-cli、RedisInsight、Prometheus和Grafana等工具,以及关注内存使用率、连接数、集群节点状态、数据一致性和性能指标,可以有效监控Redis集群的健康状态。
-

要监控Redis命中率,可通过INFO命令获取keyspace_hits和keyspace_misses计算得出,或使用RedisInsight、Prometheus+Grafana等工具实现;命中率低常见原因包括1.缓存穿透,可用布隆过滤器或缓存空值解决;2.缓存击穿,可通过永不过期或互斥锁处理;3.缓存雪崩,需设置不同过期时间或引入二级缓存;4.淘汰策略不合理,应根据访问模式选择LFU等合适策略;5.内存不足,可扩容或用集群;6.Key设计不当,应规范命名并控制长度;提升命中率还需合理选用数据结构,如
-

LPUSH+BRPOP构成FIFO阻塞队列,兼容Redis2.0+;但消费失败会导致消息丢失,适合允许少量丢失的场景,强可靠性需求应改用Stream。
-

在一些网络服务的系统中,Redis 的性能,可能是比 MySQL 等硬盘数据库的性能更重要的课题。比如微博,把热点微博[1],最新的用户关系,都存储在 Redis 中,大量的查询击中 Redis,而不走 My
-

开始准备
开始之前我们需要有Redis安装,我们采用本机Docker运行Redis, 主要命令如下
docker pull redis
docker run --name my_redis -d -p 6379:6379 redis
docker exec -it my_redis bash
redis-cli
前面两个命令是启动redis doc
-

一、单点Redis的问题
1、数据丢失问题
Redis数据持久化。
2、并发能力问题
大家主从集群,实现读写分离。
3、故障恢复问题
利用Redis哨兵,实现健康检测和自动恢复。
4、存储能力问题
搭建分片
-

Node.js开发中的Redis应用指南Redis(RemoteDictionaryServer)是一个基于内存的数据存储服务,广泛用于缓存、队列、分布式锁等场景。而在Node.js开发中,Redis是一个非常有用的工具。本文将介绍如何在Node.js中使用Redis来实现常见的应用场景,并提供相应的代码示例。一、Redis安装和连接在开始使用Redis
-

如何利用Redis实现分布式事务管理引言:随着互联网的快速发展,分布式系统的使用越来越广泛。在分布式系统中,事务管理是一项重要的挑战。传统的事务管理方式在分布式系统中难以实现,并且效率低下。而利用Redis的特性,我们可以轻松地实现分布式事务管理,提高系统的性能和可靠性。一、Redis简介Redis是一种基于内存的数据存储系统,具有高效的读写性能和丰富的数据
-

Redis启动后无法访问的原因主要包括配置文件问题、网络问题、防火墙设置和内存不足。解决方案如下:1.调整配置文件,确保绑定地址和端口正确;2.修复网络连接,确保Redis服务器和客户端连接正常;3.调整防火墙规则,允许Redis端口访问;4.增加内存或调整Redis配置,确保内存充足。
-

通过Redisexporter采集Redis的指标数据,并配置Prometheus来抓取这些数据,同时设置合适的告警规则。1.安装并配置Redisexporter,使用Docker简化安装过程。2.在Prometheus配置文件中添加scrape配置以抓取Redisexporter数据。3.使用PromQL查询Redisexporter提供的指标,如内存使用率和连接数。4.通过Alertmanager设置告警规则,如内存使用率超过90%时触发告警。
-

Redis内存占用过高可以通过以下步骤优化:1.设置maxmemory参数控制内存使用量;2.选择合适的内存回收策略,如volatile-lru或allkeys-lru;3.使用EXPIRE命令设置键的过期时间;4.选择合适的数据结构,如使用Hash类型存储小对象;5.调整持久化配置,选择RDB或AOF;6.实施分片(Sharding)技术。这些方法结合使用,可以有效降低Redis的内存占用,提升系统性能。
-

在Redis缓存清除后确保数据一致性的方法包括:1.缓存与数据库的双写一致性,通过同时更新数据库和Redis来保证实时性,但需注意写放大和一致性问题;2.缓存失效后重建,适用于读多写少的场景,需防范缓存击穿和数据一致性延迟;3.延迟双删策略,适用于高一致性需求,通过先删除缓存、更新数据库、再延迟删除缓存来解决短暂不一致问题,但增加了系统复杂度。
-

应从单节点Redis升级到集群模式,因为单节点在处理大规模数据和高并发请求时会遇到瓶颈,而集群模式通过分片和高可用性解决这些问题。升级步骤包括:1.评估现有数据量和访问模式,规划分片策略;2.准备新的集群环境,使用redis-cli--clustercreate命令创建集群;3.将数据迁移到集群,可使用MIGRATE命令或RDB快照方法;4.更新客户端连接逻辑,使用如redis-py-cluster库;5.实施分批迁移策略,监控数据一致性和系统性能;6.优化性能,设置监控和告警,制定故障恢复计划。通过这些
-

随着互联网的快速发展,大规模数据的处理成为越来越普遍的需求。特别是在协同处理的场景下,分布式架构更是成为了不可或缺的选择,因为传统的单点架构可能会在数据量过大的时候导致处理速度过慢或者崩溃。随着分布式架构的发展,越来越多的开源工具也应运而生。Redis作为一款流行的内存数据库,不仅可以用于缓存、会话管理、实时消息推送等实际场景,也可以用于搭建分布式协同处理平