-

在Linux、Windows和macOS上查看Redis版本的命令分别是:1.Linux:redis-cli--version和redis-server--version;2.Windows:redis-cli.exe--version和redis-server.exe--version;3.macOS:redis-cli--version和redis-server--version,这些命令通过调用Redis的CLI工具或服务器进程并传递--version参数来获取版本信息。
-
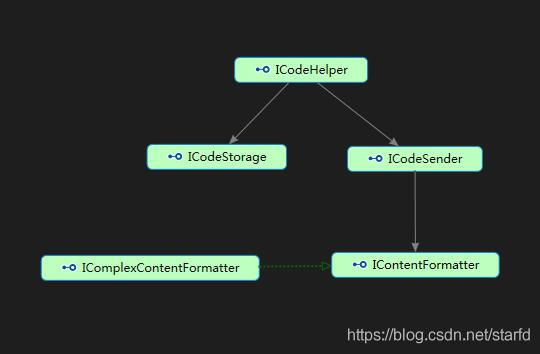
在我们的业务中,经常存在需要通过发送验证码、校验验证码来完成的一些业务逻辑,比如账号注册、找回密码、用户身份确认等。
在该类业务中,发送验证码的方式可以有各种各样,比如最
-

必须同时启用io-threads和io-threads-do-reads,否则I/O线程不参与读请求处理;io-threads≥2才生效,需configrewrite或重启;推荐值为min(4,CPU核心数×0.7),NUMA架构下必须用server_cpulist绑定同node核心。
-

应从单节点Redis升级到集群模式,因为单节点在处理大规模数据和高并发请求时会遇到瓶颈,而集群模式通过分片和高可用性解决这些问题。升级步骤包括:1.评估现有数据量和访问模式,规划分片策略;2.准备新的集群环境,使用redis-cli--clustercreate命令创建集群;3.将数据迁移到集群,可使用MIGRATE命令或RDB快照方法;4.更新客户端连接逻辑,使用如redis-py-cluster库;5.实施分批迁移策略,监控数据一致性和系统性能;6.优化性能,设置监控和告警,制定故障恢复计划。通过这些
-

Redis中的哈希类型适用于存储复杂数据结构,适合用户信息和购物车系统。1)存储用户信息:使用hset和hget命令管理用户数据。2)购物车系统:利用哈希存储商品,结合Set类型可优化大数据量。3)性能优化:避免频繁操作,使用批量命令和过期时间管理数据。
-

Redis通过事务、Lua脚本和SETNX命令实现数据操作的原子性。1)事务使用MULTI和EXEC命令,确保命令作为整体执行,但不支持回滚。2)Lua脚本通过EVAL命令,适合复杂操作,确保原子性。3)SETNX命令用于简单原子操作,如分布式锁,但需防死锁。
-

通过调整Redis的配置参数可以显著提高其读写性能。1.内存管理:设置maxmemory为10GB,maxmemory-policy为allkeys-lru。2.网络通信:调整tcp-backlog为511,timeout为0。3.持久化:设置RDB快照频率为save9001、save30010、save6010000,AOF的appendfsync为everysec。
-

需要关注Redis的版本更新,因为它能带来性能提升、安全补丁和新功能。检查Redis版本是否需要升级的步骤包括:1.使用命令“redis-cli--version”查看当前版本;2.与Redis官方版本对比;3.评估新功能、性能提升、安全补丁和兼容性;4.遵循备份数据、测试环境、逐步升级和监控日志的最佳实践。
-

分布式应用开发中,自增ID的生成是一个常见的需求。在单机环境下,可以使用数据库的自增主键来实现自增ID,但在分布式环境下,使用自增主键会出现重复的情况,因此需要使用其他的方案来保证自增ID的唯一性。Redis是一款高性能的内存数据库,可以实现分布式自增ID方案。在本文中,我们将介绍三种常见的Redis实现分布式自增ID方案,并对它们进行比较,帮助开发者选择适
-

启动
进入etc目录下 启动redis
sudo ../bin/redis-server ./redis.conf
停止 ./redis-cli shutdown 注释:这里关闭默认端口号 ./redis-cli -h 127.0.0.1 -p 7001 shutdown 注释:关闭指定端口号 实时查看日志 tail -f /usr/local/redis/l
-
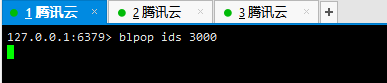
list列表简介
list是简单的字符串列表(说通俗点,存储的还是字符串),按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边),个列表最多可以包含^32-1个元素(每个列表超过
-

min-slaves-to-write作用是当在线且延迟≤min-slaves-max-lag的从库数量不足时,主库主动拒绝写命令以保障数据安全;但因不校验从库是否真正落盘、主库缓冲区数据未发送、diskless复制期间内存积压等原因仍可能丢数据。
-

Redis和HBase可以协同工作,发挥各自优势。1)使用Redis处理实时数据和缓存,如用户行为数据。2)利用HBase存储和分析历史数据,如用户购买习惯。通过这种方式,可以实现快速访问和长久存储的平衡。
-

通过Redisexporter采集Redis的指标数据,并配置Prometheus来抓取这些数据,同时设置合适的告警规则。1.安装并配置Redisexporter,使用Docker简化安装过程。2.在Prometheus配置文件中添加scrape配置以抓取Redisexporter数据。3.使用PromQL查询Redisexporter提供的指标,如内存使用率和连接数。4.通过Alertmanager设置告警规则,如内存使用率超过90%时触发告警。
-

Redis在高并发环境下的性能调优可以通过以下步骤实现:1.内存管理:使用maxmemory和maxmemory-policy配置,建议使用allkeys-lru策略。2.网络I/O优化:调整tcp-backlog和client-output-buffer-limit配置。3.持久化优化:调整rdb和aof的配置,平衡性能和数据安全。4.集群和分片:使用RedisCluster或Codis分散数据。5.客户端优化:使用连接池和批处理命令如pipeline或mget/mset。通过这些措施,可以确保Redi