Redis技术文章
-
 RedisPub/Sub不支持延迟投递,一发即广播、离线即丢失;可靠延时需绕开Pub/Sub,改用ZSET存消息+调度器触发PUBLISH,并用Lua保证原子性。172 收藏
RedisPub/Sub不支持延迟投递,一发即广播、离线即丢失;可靠延时需绕开Pub/Sub,改用ZSET存消息+调度器触发PUBLISH,并用Lua保证原子性。172 收藏 -
 Redis原生String类型无法解析JSON字段,必须用RedisJSON模块实现路径查询、原子更新等能力;启用需加载模块,使用JSON.SET/JSON.GET命令,性能提升体现在频繁子字段操作场景。170 收藏
Redis原生String类型无法解析JSON字段,必须用RedisJSON模块实现路径查询、原子更新等能力;启用需加载模块,使用JSON.SET/JSON.GET命令,性能提升体现在频繁子字段操作场景。170 收藏 -
 Redis集群默认不支持读写分离,所有请求均被重定向至主节点,从节点仅用于故障转移;如需读写分离,须弃用集群客户端,改用普通主从客户端自行路由。169 收藏
Redis集群默认不支持读写分离,所有请求均被重定向至主节点,从节点仅用于故障转移;如需读写分离,须弃用集群客户端,改用普通主从客户端自行路由。169 收藏 -
 down-after-milliseconds不是触发故障转移的开关,仅决定哨兵何时标记主节点为主观下线(SDOWN);完成自动切换需满足quorum票数达成客观下线(ODOWN),再经选举和failover-timeout窗口内执行完整流程。166 收藏
down-after-milliseconds不是触发故障转移的开关,仅决定哨兵何时标记主节点为主观下线(SDOWN);完成自动切换需满足quorum票数达成客观下线(ODOWN),再经选举和failover-timeout窗口内执行完整流程。166 收藏 -
 <p>Redis7.2优化内存淘汰池,将evictionPoolEntry.key由sds改为非持有型char*指针,避免memcpy和重复内存分配,显著降低高采样数下的CPU开销,不改变淘汰逻辑。</p>165 收藏
<p>Redis7.2优化内存淘汰池,将evictionPoolEntry.key由sds改为非持有型char*指针,避免memcpy和重复内存分配,显著降低高采样数下的CPU开销,不改变淘汰逻辑。</p>165 收藏 -
 SpringBoot默认不开启Redis读写分离,纯主从模式下即使配置read-from也无效;必须使用哨兵/集群模式或自定义MasterReplica.connect(),并配合LettuceClientConfigurationBuilderCustomizer注入ReadFrom.REPLICA_PREFERRED才能生效。161 收藏
SpringBoot默认不开启Redis读写分离,纯主从模式下即使配置read-from也无效;必须使用哨兵/集群模式或自定义MasterReplica.connect(),并配合LettuceClientConfigurationBuilderCustomizer注入ReadFrom.REPLICA_PREFERRED才能生效。161 收藏 -
 分片后每个Redis节点必须独立配置持久化,RDB需统一save规则且隔离磁盘路径,AOF应全节点开启并设appendfsynceverysec,避免部分节点未持久化导致数据丢失。158 收藏
分片后每个Redis节点必须独立配置持久化,RDB需统一save规则且隔离磁盘路径,AOF应全节点开启并设appendfsynceverysec,避免部分节点未持久化导致数据丢失。158 收藏 -
 缓存空值、布隆过滤器和业务层校验是防御缓存穿透的三层策略:空值需设短过期并避免null值;布隆过滤器须预估容量、全局单例且配合写库更新;业务层应优先校验参数合法性。158 收藏
缓存空值、布隆过滤器和业务层校验是防御缓存穿透的三层策略:空值需设短过期并避免null值;布隆过滤器须预估容量、全局单例且配合写库更新;业务层应优先校验参数合法性。158 收藏 -
 调小down-after-milliseconds并非提速关键,它仅控制单哨兵标记SDOWN的阈值;真正影响故障转移速度的是探测间隔、quorum共识、hello广播周期及failover-timeout与从节点同步能力的协同匹配。156 收藏
调小down-after-milliseconds并非提速关键,它仅控制单哨兵标记SDOWN的阈值;真正影响故障转移速度的是探测间隔、quorum共识、hello广播周期及failover-timeout与从节点同步能力的协同匹配。156 收藏 -
 Redis集群连接失败需先确认服务端启用cluster-enabledyes且至少3个主节点;客户端必须用redis-cli-c或集群驱动,否则报MOVED错误;KEYS*等跨slot命令不支持,SCAN需遍历各节点执行。155 收藏
Redis集群连接失败需先确认服务端启用cluster-enabledyes且至少3个主节点;客户端必须用redis-cli-c或集群驱动,否则报MOVED错误;KEYS*等跨slot命令不支持,SCAN需遍历各节点执行。155 收藏 -
 需结合XINFOCONSUMERS与XINFOGROUPS判断Streams实时消费延迟:关注pel-count、pending数、idle值及last-delivered-id与流尾ID的字典序比较,避免误判离线或假死状态。155 收藏
需结合XINFOCONSUMERS与XINFOGROUPS判断Streams实时消费延迟:关注pel-count、pending数、idle值及last-delivered-id与流尾ID的字典序比较,避免误判离线或假死状态。155 收藏 -
 Redis延迟高但CPU正常通常是网络丢包或抖动所致,表现为redis-cli--latency毛刺飙升、ping标准差>10ms或丢包率>0.1%,需用tcpdump抓包分析重传与ACK丢弃,并排查云环境安全组、NAT会话老化及内核TCP参数配置。154 收藏
Redis延迟高但CPU正常通常是网络丢包或抖动所致,表现为redis-cli--latency毛刺飙升、ping标准差>10ms或丢包率>0.1%,需用tcpdump抓包分析重传与ACK丢弃,并排查云环境安全组、NAT会话老化及内核TCP参数配置。154 收藏 -
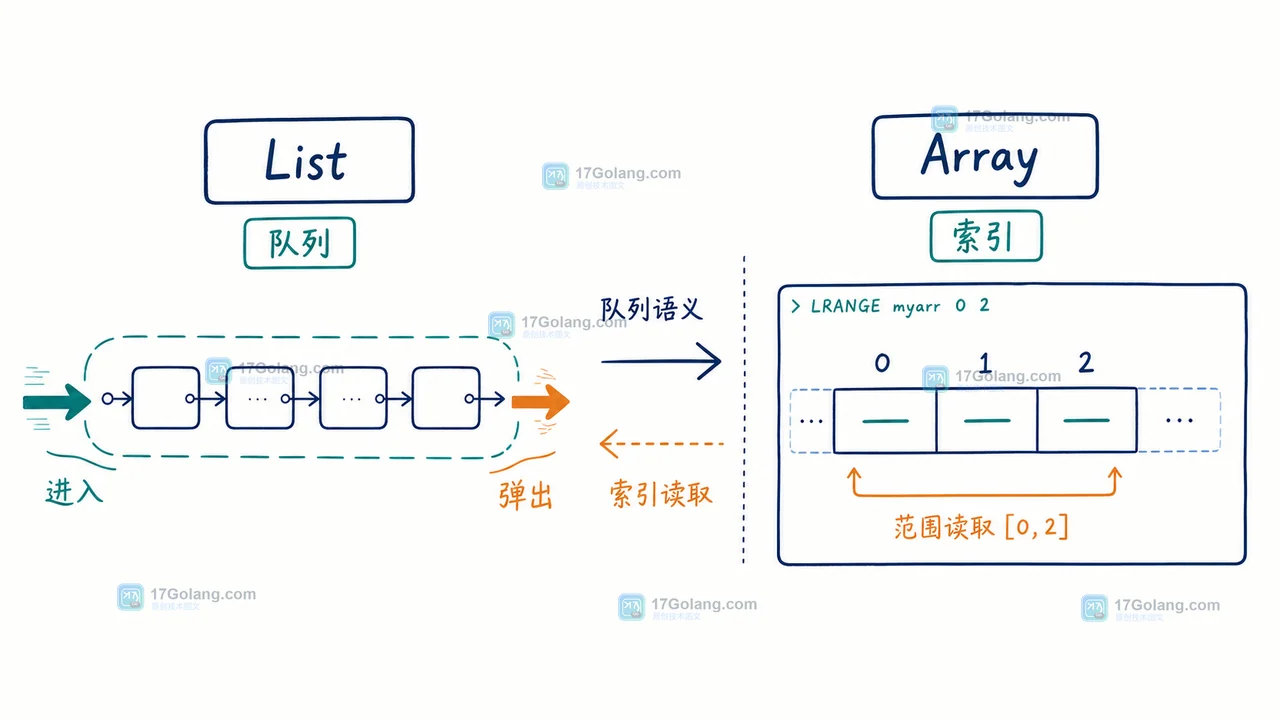 Redis 8.8 带来原生 Array 数据结构,适合滚动窗口、按索引读取和范围聚合。本文用一组最小命令验证它与 List 的差异,并给出从 List 迁移前应检查的读写边界、客户端支持和回滚办法。154 收藏
Redis 8.8 带来原生 Array 数据结构,适合滚动窗口、按索引读取和范围聚合。本文用一组最小命令验证它与 List 的差异,并给出从 List 迁移前应检查的读写边界、客户端支持和回滚办法。154 收藏 -
 redis.call()比redis.pcall()更易触发OOM,因其失败即终止,而pcall()返回的错误表常驻Lua栈且累积不释放,RedisLua引擎仅在脚本退出时批量GC。153 收藏
redis.call()比redis.pcall()更易触发OOM,因其失败即终止,而pcall()返回的错误表常驻Lua栈且累积不释放,RedisLua引擎仅在脚本退出时批量GC。153 收藏 -
 GEORADIUS返回空结果最常见原因是经纬度顺序写反,必须经度在前、纬度在后;而高德/百度等地图API默认是纬度在前、经度在后,导致坐标存入错误位置。152 收藏
GEORADIUS返回空结果最常见原因是经纬度顺序写反,必须经度在前、纬度在后;而高德/百度等地图API默认是纬度在前、经度在后,导致坐标存入错误位置。152 收藏