Go语言技术文章
-
科技周边 · 人工智能 | 1天前 | go · openai · AI接口 · Responses API · Go OpenAI Responses API background mode 异步轮询 大模型接口
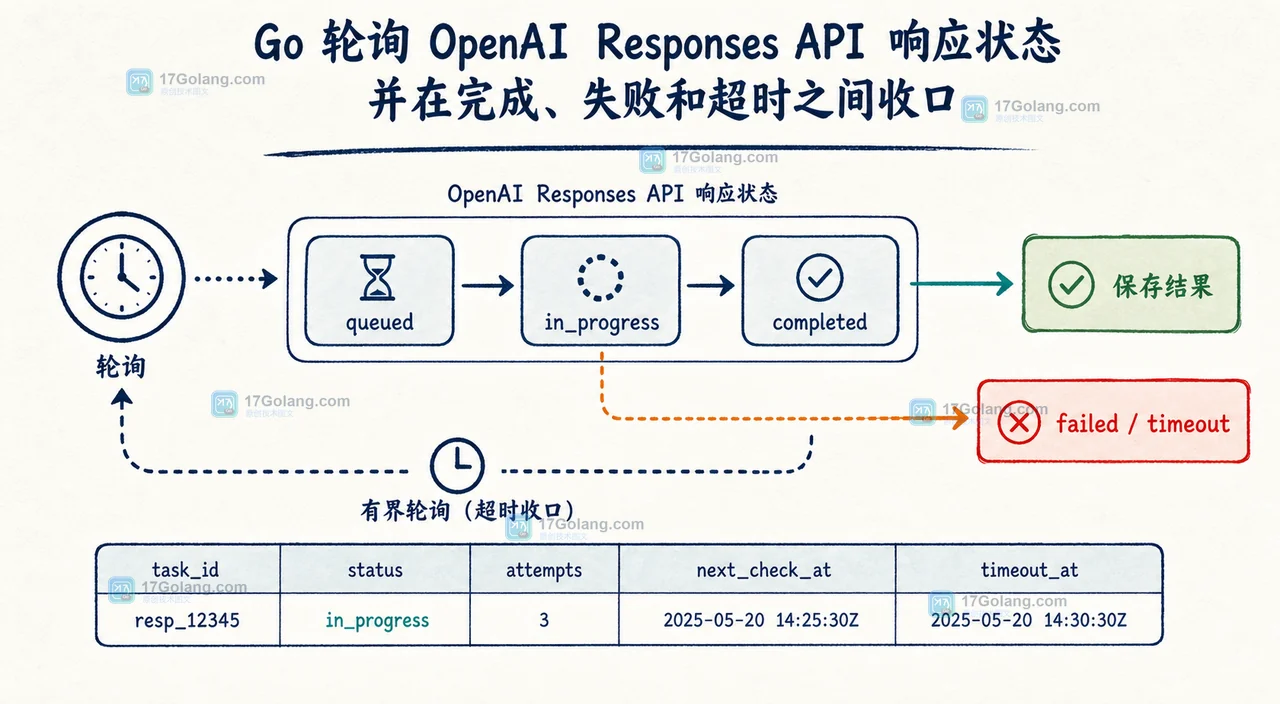 用 Go 接入 OpenAI Responses API 时,长推理或工具调用容易让同步 HTTP 请求撞上超时。本文从同步调用迁移到 background 模式,演示如何提交任务、按响应 ID 轮询、处理失败状态,并说明约 10 分钟保留窗口与 Zero Data Retention 的边界。388 收藏
用 Go 接入 OpenAI Responses API 时,长推理或工具调用容易让同步 HTTP 请求撞上超时。本文从同步调用迁移到 background 模式,演示如何提交任务、按响应 ID 轮询、处理失败状态,并说明约 10 分钟保留窗口与 Zero Data Retention 的边界。388 收藏 -
科技周边 · 业界新闻 | 1天前 | 前端 · 流式处理 · sse · Web Streams · TextDecoderStream · 流式解码 SSE ReadableStream TextDecoderStream UTF-8分块
 SSE 返回的 UTF-8 字节可能把一个汉字拆在两个网络 chunk 中,逐块直接 TextDecoder.decode 容易出现替换字符。本文用浏览器 TextDecoderStream 处理 SSE 文本流,说明 pipeThrough、行缓冲、事件结束标记和兼容边界。186 收藏
SSE 返回的 UTF-8 字节可能把一个汉字拆在两个网络 chunk 中,逐块直接 TextDecoder.decode 容易出现替换字符。本文用浏览器 TextDecoderStream 处理 SSE 文本流,说明 pipeThrough、行缓冲、事件结束标记和兼容边界。186 收藏 -
科技周边 · 人工智能 | 1天前 | go语言 · 异步任务 · 人工智能 · openai · API工程化 · Go 异步任务 轮询 数据保留 OpenAI Responses API background mode
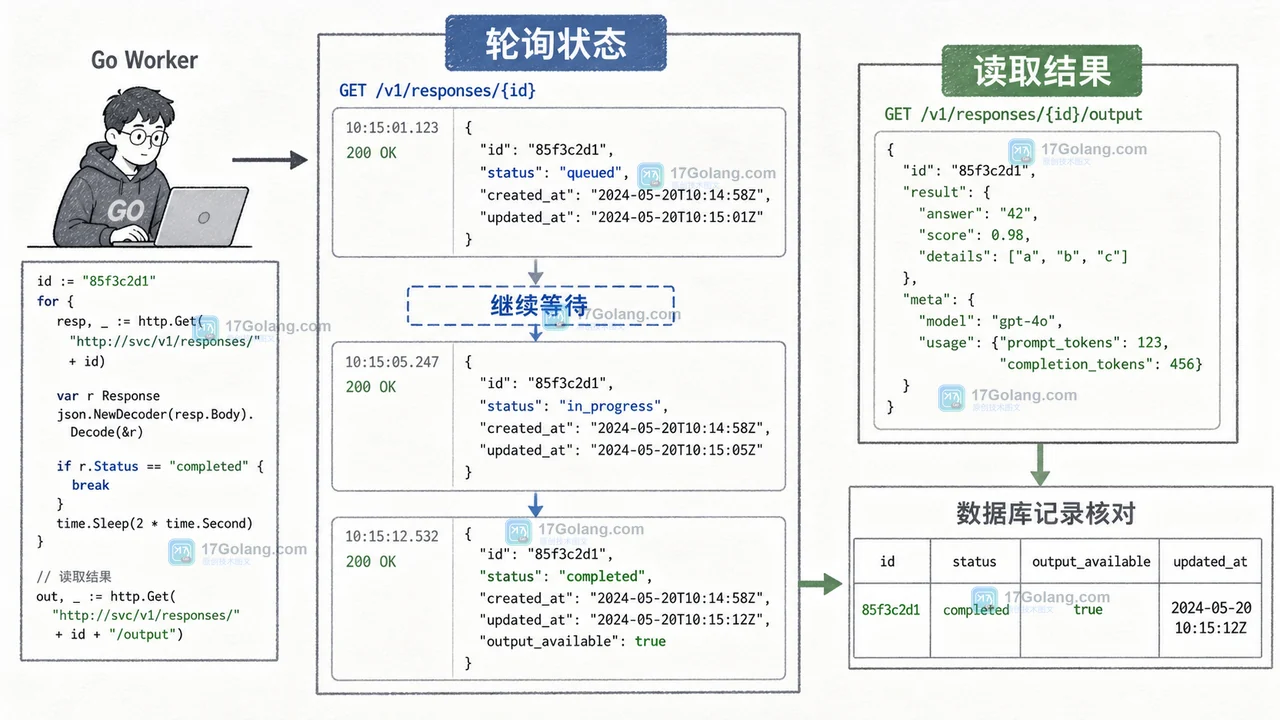 长时间 AI 请求不适合一直占着 Go HTTP 连接。本文用一个报告生成场景拆开 Responses API background mode 的提交、轮询、完成判断和错误处理,并提醒后台模式与数据保留、Zero Data Retention 的边界。183 收藏
长时间 AI 请求不适合一直占着 Go HTTP 连接。本文用一个报告生成场景拆开 Responses API background mode 的提交、轮询、完成判断和错误处理,并提醒后台模式与数据保留、Zero Data Retention 的边界。183 收藏 -
 Node.js 26.5.0 新增 Blob.textStream(),返回可读流。本文从 Blob 文本读取场景出发,对比 text()、stream() 和 textStream(),给出逐块处理、编码边界与版本核对方法。468 收藏
Node.js 26.5.0 新增 Blob.textStream(),返回可读流。本文从 Blob 文本读取场景出发,对比 text()、stream() 和 textStream(),给出逐块处理、编码边界与版本核对方法。468 收藏 -
 Go 官方在 2026 年 5 月发布 pkg.go.dev API,提供查询模块、包、版本、符号和漏洞元数据的 GET 接口。本文用 v1beta 做一个小型依赖索引实验,处理路径编码、版本参数、歧义模块和失败重试边界。310 收藏
Go 官方在 2026 年 5 月发布 pkg.go.dev API,提供查询模块、包、版本、符号和漏洞元数据的 GET 接口。本文用 v1beta 做一个小型依赖索引实验,处理路径编码、版本参数、歧义模块和失败重试边界。310 收藏 -
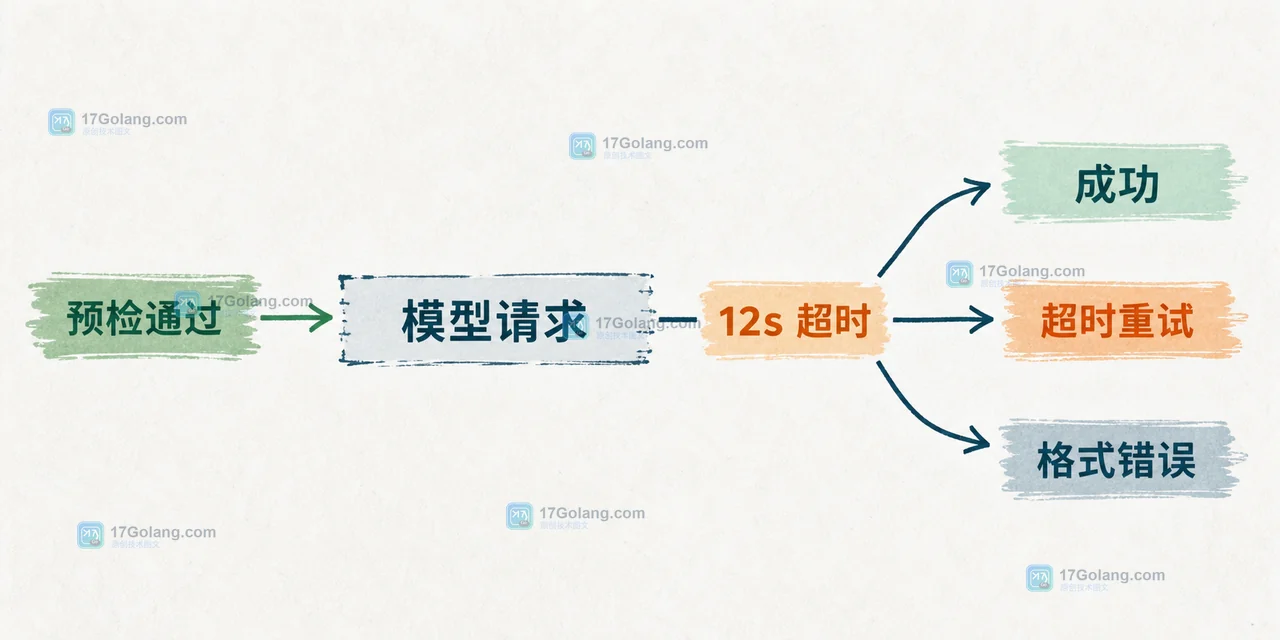 Go 服务接入多模态接口时,图片预检应放在上传入口:先检查 MIME、文件头和字节上限,再决定是否送给模型;遇到格式不支持或服务超时则返回可解释的降级结果。202 收藏
Go 服务接入多模态接口时,图片预检应放在上传入口:先检查 MIME、文件头和字节上限,再决定是否送给模型;遇到格式不支持或服务超时则返回可解释的降级结果。202 收藏 -
科技周边 · 人工智能 | 3天前 | API · go · 人工智能 · 工程实践 · 工具调用 · Go Anthropic Messages API tool_use tool_result Claude工具调用
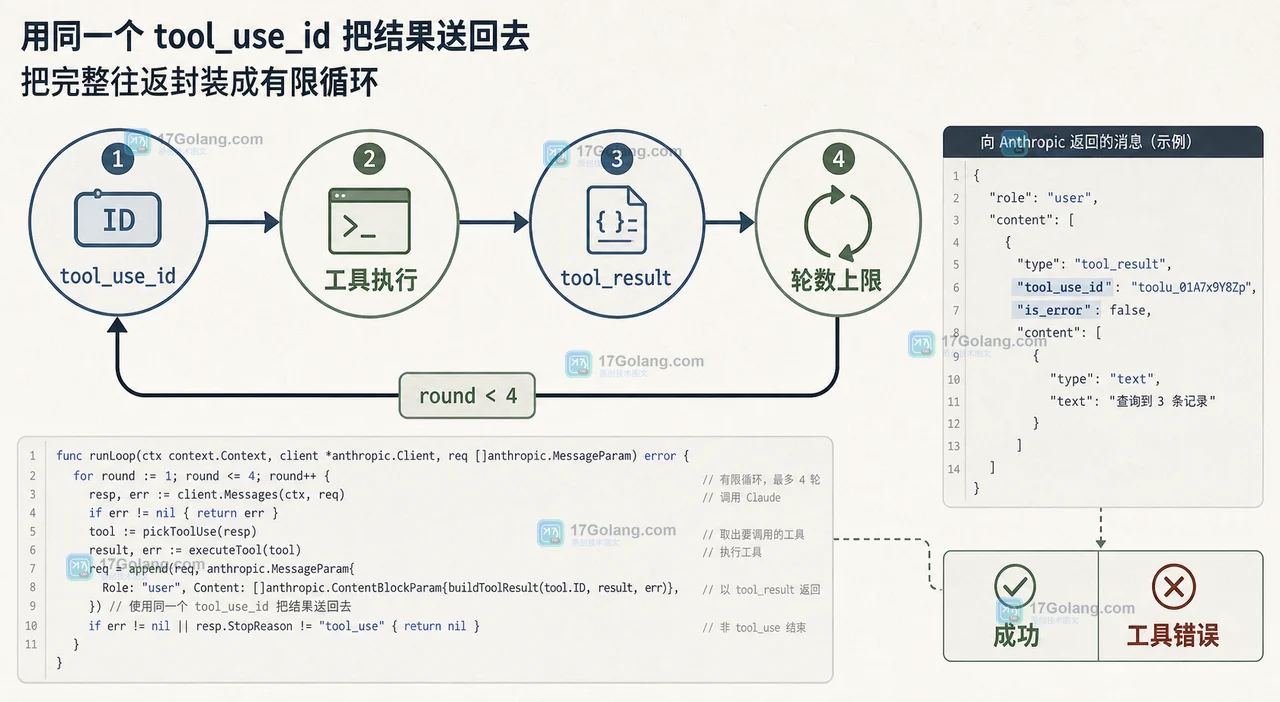 Go 服务接入 Anthropic Messages API 的工具调用时,模型返回 tool_use 只是请求执行工具,不是最终答案。本文用天气查询工具拆解 stop_reason、tool_use_id、tool_result 的往返消息格式,并给出防止无限循环和错误回传的实现边界。368 收藏
Go 服务接入 Anthropic Messages API 的工具调用时,模型返回 tool_use 只是请求执行工具,不是最终答案。本文用天气查询工具拆解 stop_reason、tool_use_id、tool_result 的往返消息格式,并给出防止无限循环和错误回传的实现边界。368 收藏 -
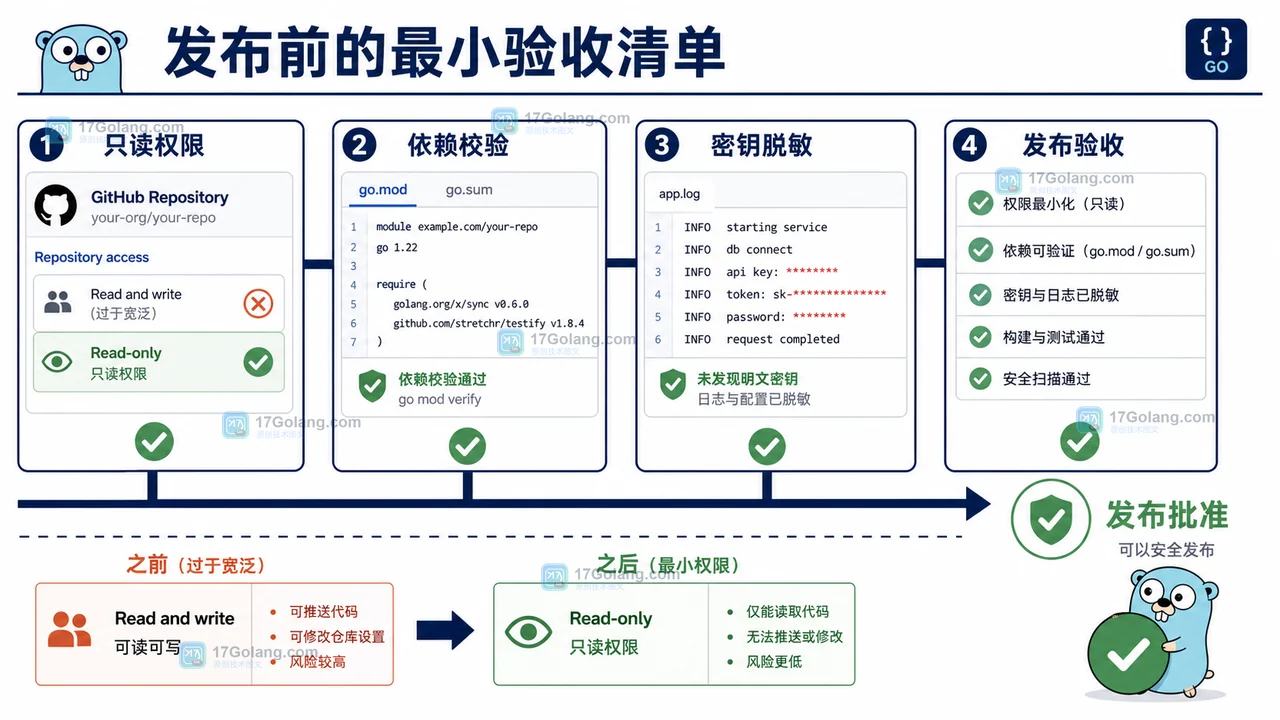 GitHub 披露受污染 VS Code 扩展事件后,Go 团队应如何检查仓库权限、Actions 工作流、依赖来源和密钥暴露?本文给出一套可在半小时内完成的安全体检清单。388 收藏
GitHub 披露受污染 VS Code 扩展事件后,Go 团队应如何检查仓库权限、Actions 工作流、依赖来源和密钥暴露?本文给出一套可在半小时内完成的安全体检清单。388 收藏 -
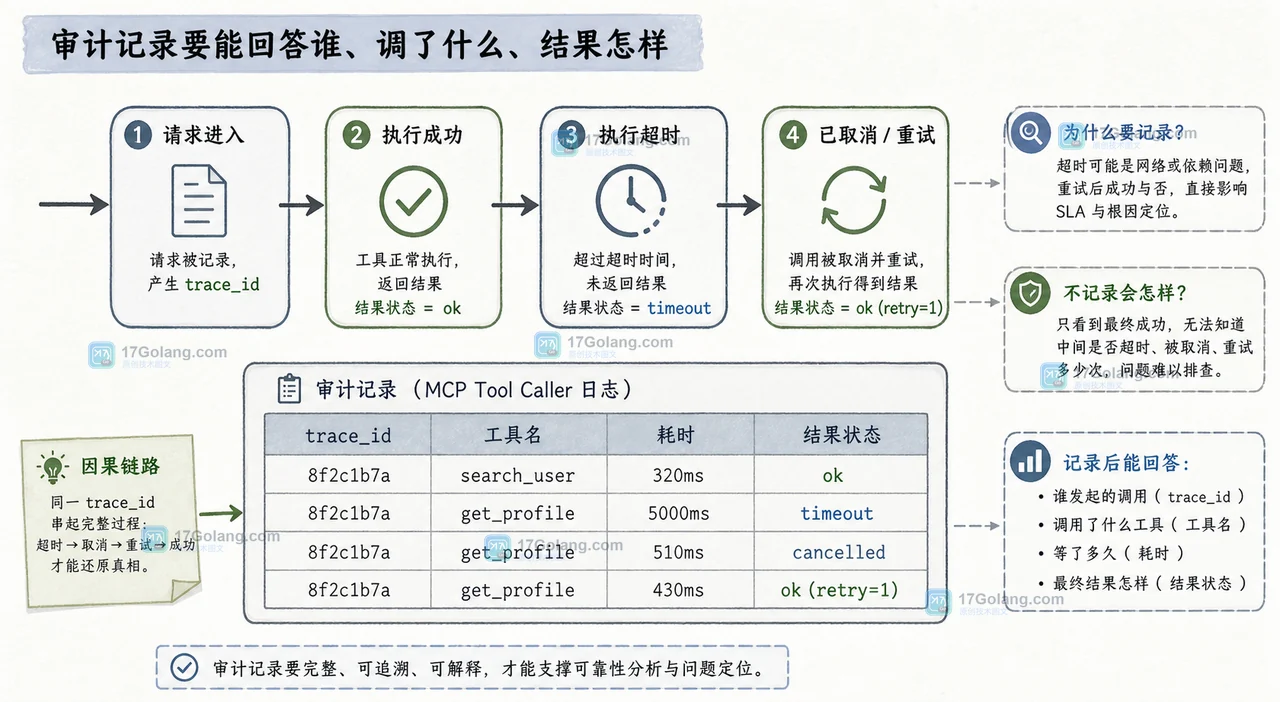 把 MCP tools/call 接进 Go 服务后,真正难处理的不是发出 JSON-RPC 请求,而是超时、取消、重试和审计如何共同收口。本文用一个可运行的调用包装器,把总预算、单次调用、重试边界和结果记录拆开。243 收藏
把 MCP tools/call 接进 Go 服务后,真正难处理的不是发出 JSON-RPC 请求,而是超时、取消、重试和审计如何共同收口。本文用一个可运行的调用包装器,把总预算、单次调用、重试边界和结果记录拆开。243 收藏 -
科技周边 · 业界新闻 | 4天前 | golang · 业界新闻 · 版本升级 · 安全修复 · 生产运维 · crypto/tls Go 1.26.5 Go 1.25.12 CVE-2026-39822 Go 版本升级 生产发布
 Go 官方发布 Go 1.26.5 与 Go 1.25.12,包含 crypto/tls 和 os 相关安全修复,以及编译器、运行时和 go 命令的缺陷修复。本文把这次小版本更新拆成影响面、升级判断、灰度检查和回退清单,帮助生产团队决定何时跟进。324 收藏
Go 官方发布 Go 1.26.5 与 Go 1.25.12,包含 crypto/tls 和 os 相关安全修复,以及编译器、运行时和 go 命令的缺陷修复。本文把这次小版本更新拆成影响面、升级判断、灰度检查和回退清单,帮助生产团队决定何时跟进。324 收藏 -
 即使接口启用了严格 JSON Schema,Go 服务仍要检查拒答、截断和字段值语义。本文用一个可运行的校验边界示例,拆开模型响应、json.Unmarshal 和业务校验各自该负责什么。195 收藏
即使接口启用了严格 JSON Schema,Go 服务仍要检查拒答、截断和字段值语义。本文用一个可运行的校验边界示例,拆开模型响应、json.Unmarshal 和业务校验各自该负责什么。195 收藏 -
科技周边 · 业界新闻 | 5天前 | postgresql · 数据库升级 · Beta测试 · pg_upgrade · 数据库升级 兼容性测试 PostgreSQL 19 Beta 2 pg_upgrade pg_dump
 PostgreSQL 19 Beta 2 已发布,但测试版不该直接进入生产。本文按数据导出、升级、典型查询、异常回收四段链路,给出一套可复用的预发布兼容性验证方法,并列出 pg_upgrade 与逻辑导出的选择边界。423 收藏
PostgreSQL 19 Beta 2 已发布,但测试版不该直接进入生产。本文按数据导出、升级、典型查询、异常回收四段链路,给出一套可复用的预发布兼容性验证方法,并列出 pg_upgrade 与逻辑导出的选择边界。423 收藏 -
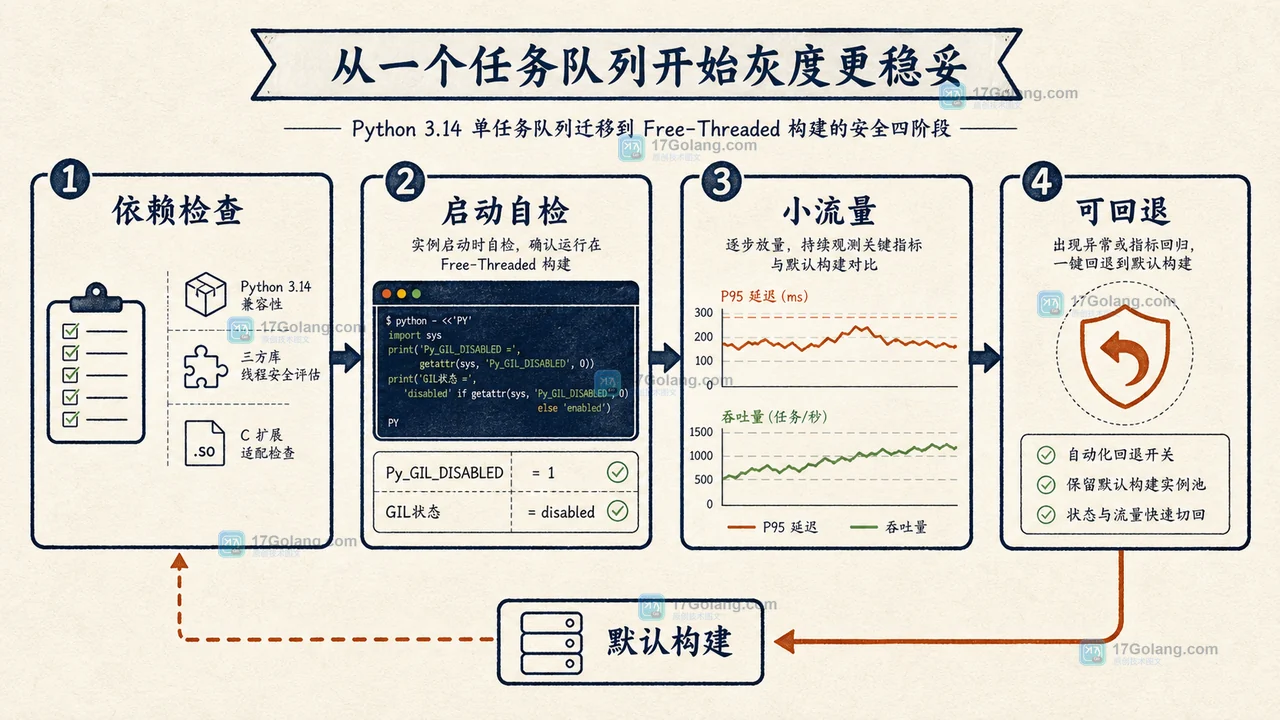 Python 3.14 将 free-threaded build 纳入正式支持。它能让设计得当的 CPU 密集型多线程工作负载利用多核,但不是把现有服务切换后就自动提速。本文从扩展兼容、共享状态、压测与回退四个角度拆解团队该如何判断与迁移。314 收藏
Python 3.14 将 free-threaded build 纳入正式支持。它能让设计得当的 CPU 密集型多线程工作负载利用多核,但不是把现有服务切换后就自动提速。本文从扩展兼容、共享状态、压测与回退四个角度拆解团队该如何判断与迁移。314 收藏 -
科技周边 · 业界新闻 | 6天前 | 云原生 · Etcd · kubernetes · 分布式系统 · 业界新闻 · Kubernetes etcd 3.7.0 RangeStream etcd升级 v2store etcdctl
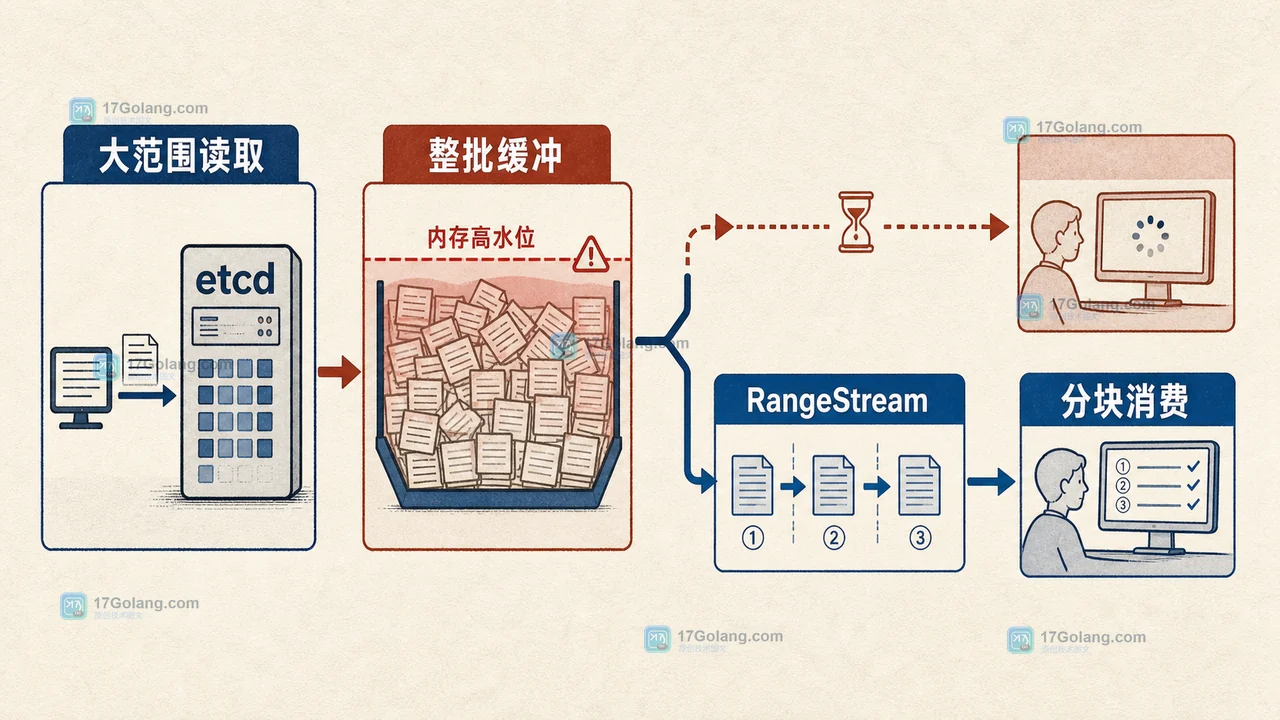 etcd 3.7.0 已发布,重点是用 RangeStream 分块返回大范围读取结果、优化 keys-only 查询和租约路径,并移除遗留 v2 组件。对 Kubernetes 控制面和自建 etcd 集群而言,升级前更该核对 v2 依赖、镜像标签、客户端行为与滚动升级顺序。230 收藏
etcd 3.7.0 已发布,重点是用 RangeStream 分块返回大范围读取结果、优化 keys-only 查询和租约路径,并移除遗留 v2 组件。对 Kubernetes 控制面和自建 etcd 集群而言,升级前更该核对 v2 依赖、镜像标签、客户端行为与滚动升级顺序。230 收藏 -
 大模型流式输出不能把每个分片当成完整 JSON。用缓冲区、完成事件、事务与请求幂等键,把半截内容和重试写入挡在数据库之外。186 收藏
大模型流式输出不能把每个分片当成完整 JSON。用缓冲区、完成事件、事务与请求幂等键,把半截内容和重试写入挡在数据库之外。186 收藏