-

Indiegogo网站产品URL爬取失败及问题排查本文将针对“无法爬取某网站各项产品的URL”这一问题进行分析和解答。...
-

在SQLAlchemy...
-
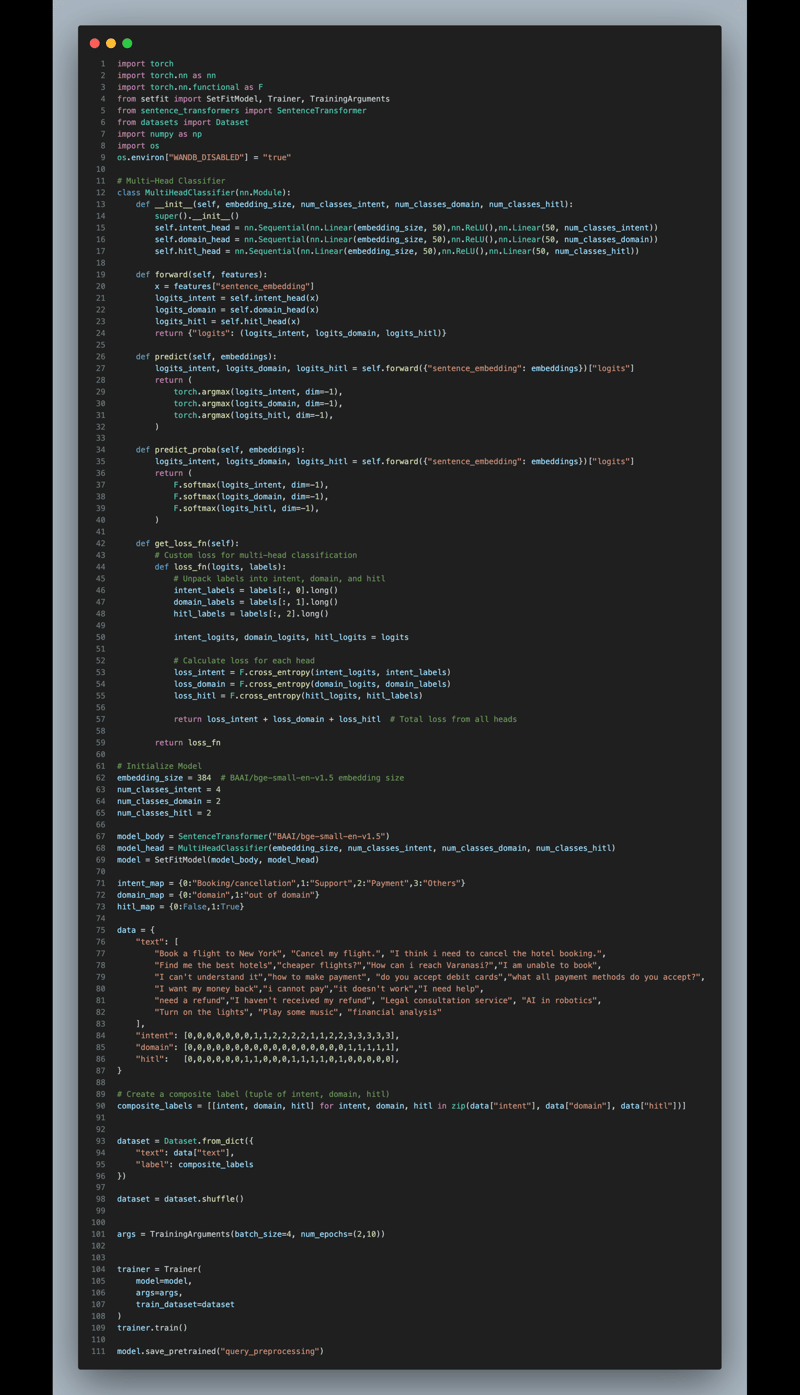
客户至上的应用程式,查询预处理是确保精准路由和行动决策的关键步骤。我并没有训练独立的模型,而是将拟合与多头分类器结合使用,这是一个拥有独立分类头的共享嵌入空间。每个分类头专注于一项特定任务,允许针对任务的学习,同时通过共享表示保持效率。利用(意图、领域、HITL(循环中的人))组创建正负样本对进行对比学习,确保模型有效区分相关查询。这种结构化方法平衡了效率和灵活性,非常适合需要既精准又可扩展的实时查询分类应用。这只是一个范例,您可以根据需求进行调整。链接到代码库
-

人工智能技术日新月异,开发者们正积极探索将智能功能融入日常工作流程的方法。构建能够自主完成任务、将推理与行动相结合的智能代理便是其中一种有效途径。本文将指导您如何利用LangChain、OpenAI的GPT-4以及LangChain的实验工具,创建一个能够执行Python代码、处理CSV文件并解答复杂问题的智能代理。LangChain的优势LangChain是一个功能强大的框架,用于构建基于语言模型的应用程序。其模块化、可重用的组件(例如代理)使其在创建智能代理方面尤为出色,它具备以下能力:执
-

Python在各行各业的应用建模Python凭借其强大的功能和易用性,已成为构建和部署行业特定模型的热门编程语言。金融、医疗、电商和制造业等众多领域都利用Python解决实际问题,提升效率。其灵活性和可扩展性,加上丰富的库和框架支持,使其成为数据分析、机器学习、自动化和模拟的理想工具。Python在行业建模中的关键应用:核心应用领域:机器学习与预测分析:金融:Python的机器学习库(scikit-learn,TensorFlow,Keras)用于构建股票预测、风险评估、欺诈检测和算法交易模型。医疗:用于
-
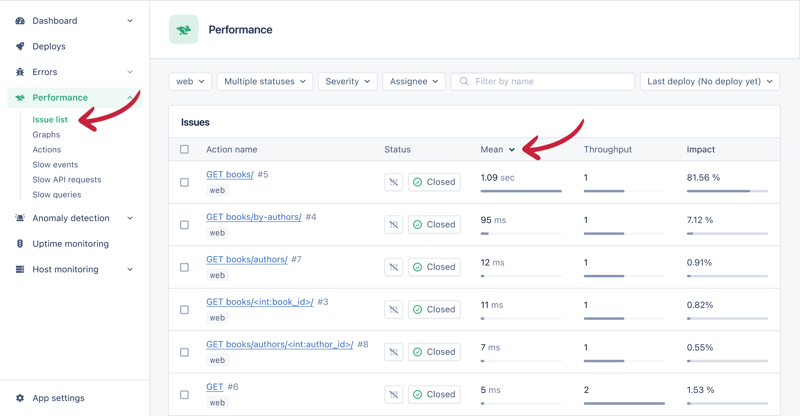
在本文中,您将了解n1查询、如何使用appsignal检测它们,以及如何修复它们以显着加快django应用程序的速度。我们将从理论方面开始,然后转向实际示例。实际示例将反映您在生产环境中可能遇到的场景。让我们开始吧!什么是n1查询?n1查询问题是与数据库交互的web应用程序中普遍存在的性能问题。这些查询可能会导致严重的瓶颈,并且随着数据库的增长而加剧。当您检索对象集合,然后访问集合中每个项目的相关对象时,就会出现问题。例如,获取书籍列表需要单个查询(1个查询),但访问每本书的作者会触发对每个项目的额外查询
-

在当今竞争激烈的数字世界中,在Google第一页获得曝光度对于任何企业或网站都至关重要。优化网站以实现这一目标的过程称为SEO(搜索引擎优化)。通过精心设计的SEO策略在Google上获得高排名,您的网站可以获得更多的自然流量、提高可信度并提高转化率。在本指南中,我们将深入探讨SEO的关键要素以及如何利用它们有效地在Google上排名更高。为什么SEO对于Google上的高排名至关重要Google每天处理超过85亿次搜索,使其成为全球最重要的搜索引擎。在Google上获得高排名至关重要,因为:流量增加:大
-

如何在Python中实现此JavaScript代码?JavaScript代码:function_(){return...
-

简介数字时代,提升用户体验是关键。凭借人工智能语音助手和语音用户界面的强大功能,SistaAI正在引领这场革命。他们的技术无缝集成在任何应用程序或网站中,改变了交互方式,使它们更具吸引力和可访问性。重新构想客户支持客户支持至关重要,SistaAI的人工智能语音助手彻底改变了这一流程。支持40多种语言,用户可以体验动态交互,从而前所未有地提高效率和可访问性。赋能内容创作利用人工智能助手生成博客文章是未来。HubSpot等服务提供了轻松优化SEO帖子的工具,通过GPT-4等创新增强内容创建。人工智能增强内容创
-

单向循环链表将所有的链接在一起,每一个节点分为数据存储区和链接区,数据区存储数据,链接区链接下一个节点item:存储数据的地方next:链接下一个节点注意:单向循环链表是首位链接,即尾部的节点要和头部的节点链接单向链表操作1、链表是否为空2、链表的长度3、遍历链表4、链表头部添加元素5、链表尾部添加元素6、链表指定位置添加元素7、链表删除节点8、查找节点是否存在代码实现#Functions函数声明classNode():"""实例化节点类"""def__init__(self,item):self.ite
-

解决matplotlib中文乱码的技巧与经验分享【导言】在使用matplotlib绘制图形时,我们难免会遇到中文乱码的问题。这一问题通常出现在图例、坐标轴标签等地方。为了解决这个问题,本文将分享一些实用的技巧和经验,以帮助读者轻松解决matplotlib中文乱码的困扰。【问题描述】在使用matplotlib绘制图形时,我们默认使用的是英文字符集。在添加中文文
-

了解Django版本,为项目选择正确的框架基础!随着互联网的快速发展,Web应用程序的需求不断增长。在开发Web应用程序的过程中,选择一个合适的框架非常重要。Django作为一个高度可扩展的Web框架,它提供了许多功能强大而易于使用的特性,使得开发Web应用程序变得更加简单和高效。然而,对于初次接触Django的开发者来说,选择适合自己项目的合适Django
-

如何使用Python中的正则表达式正则表达式是一种强大的文本匹配工具,可以帮助我们检索、替换、分割等各种文本处理操作。而在Python中,我们可以使用内置的re模块来操作正则表达式。本文将详细介绍如何使用Python中的正则表达式,并提供具体的代码示例。导入re模块在使用正则表达式之前,我们需要先导入Python的re模块。importre简单的匹配操作我
-

如何在Python中处理JSON数据的问题,需要具体代码示例引言JSON(JavaScriptObjectNotation)是一种常用的数据交换格式,广泛应用于各种编程语言和平台之间的数据传输。在Python中,我们可以使用内置的json模块来处理JSON数据。本文将介绍如何在Python中使用json模块来解析和生成JSON数据,并提供一些具体的代码示
-
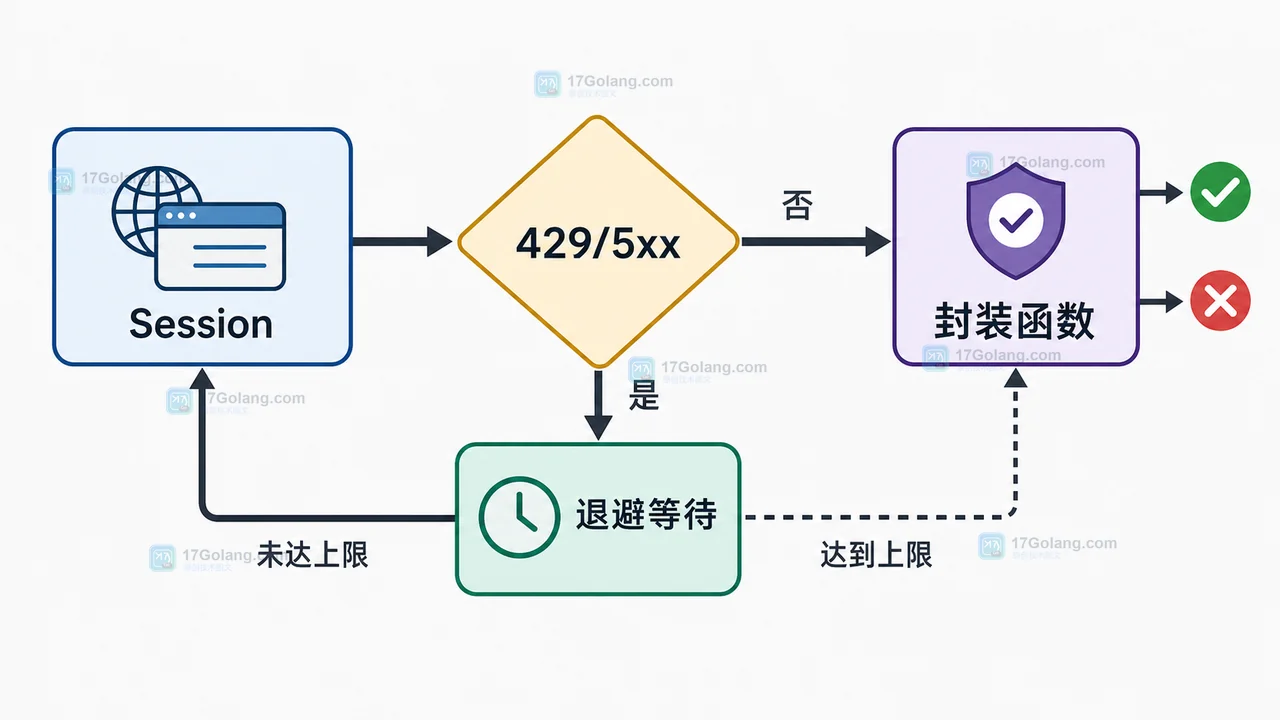
用一个最小 requests 配方解决 HTTP 请求卡住、慢接口无响应和偶发 5xx 问题:分开设置连接/读取超时,用 Session 统一重试,再封装业务请求函数。